crowRedis Data Replication , delving into distributed systems.
 Biohacker0
Biohacker0
How I implemented the data replication concept of master and worker previously known as master/slave architecture for distributed databases on my project crowRedis.
If you want to know what have I done till now : Read the previous blog

GitHub Link -https://github.com/biohacker0/crowRedis/tree/dataReplication-1
The replication feature is currently on dataReplication-1 branch only not on the main branch.
Why do this?:
Where would be fun if I just left crowRedis to do set, get and those transactions, that is just language play.
You don't get good just by doing the bare minimum, I want to tackle most of the big-sounding concepts.
And this was my solution to data replication, I wrote on paper how I would do it, and I iterated 4 times to see how I would replicate data if someone told me:
hey, I have this database-1 and I want to connect my other databases to this one and replicate the data of database-1 to all the databases connected.
You don't need to read someone else's blog to do this, the problem is straightforward, and you should think about how you would do this.

isn't my handwriting beautiful, ( ˘͈ ᵕ ˘͈♡)
Master / Worker dynamic mode
** Currently we are replicating data for set data command only , not for delete or other things, I will add those afterwords maybe **
Yes, you can run my script to act as both master or worker based on the user's choice.
For the clear test, you can clone the same repo twice and name one folder instance 1 and their run the script in master mode and another as instance-1 and run it in worker mode for clarity.
def start(self):
replication_thread = None
if self.is_master:
replication_thread = threading.Thread(target=self.run_replication_log, name='replication-thread')
print("master thread started")
else:
# If this server is a worker, connect to the master
try:
self.worker_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
master_host, master_port = self.master_address.split(':')
master_port = int(master_port)
self.worker_socket.connect((master_host, master_port))
self.worker_socket.send(b"REGISTER")
print(f"Connected to master server at {self.master_address}")
replication_thread = threading.Thread(target=self.replicate_data_from_master, name='worker-replication-thread')
print("worker thread started")
except Exception as e:
print(f"Error connecting to master: {e}")
# Handle errors, e.g., by setting self.worker_socket to None
return
# Start the replication thread
replication_thread.start()
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as server_socket:
server_socket.bind((self.host, self.port))
server_socket.listen()
print(f"Server listening on {self.host}:{self.port}")
while True:
try:
client_socket, client_address = server_socket.accept()
print(f"Accepted connection from {client_address[0]}:{client_address[1]}")
threading.Thread(target=self.handle_client, args=(client_socket,client_address)).start()
except Exception as e:
print(f"Error accepting client connection: {e}")
if __name__ == "__main__":
is_master = input("Are you running as a master (y/n)? ").lower() == 'y'
if is_master:
host = '127.0.0.1'
port = 6381
master_address = None
worker_port = None
redis_server = RedisServer(host, port, is_master, master_address)
else:
master_address = '127.0.0.1:6381'
host = '127.0.0.1'
worker_port = 6382
redis_server = RedisServer(host, worker_port, is_master, master_address)
redis_server.start()
1. How it works as Master and Worker Dynamically:
The server can operate as either a master or a worker, depending on the choice made when the script is executed. Here's how it works in each mode:
Master Mode:
In master mode👑, the server acts as the primary data source.
When starting in master mode, the server listens for incoming client connections on a specified host and port (e.g., host: 127.0.0.1 and port: 6381)🚀.
It also starts a replication thread (🏃♂️
run_replication_log) that logs write operations into a queue (thelog_queue). This is the replication log🔄.Clients can connect to the master to execute various Redis commands💼.
If a client is a worker, it can register with the master using the "REGISTER"👥 command. The master adds the connected worker's socket to a list of connected workers.
The master continuously logs write operations, and it also manages replication to all registered worker servers.🔄
Data is replicated from the master to all connected workers by sending the replication log entries to each worker's socket.🔄
So both the worker and normal clients can connect to the master, The worker lets the master know that it is a worker client by sending msg "REGISTER" at the connect time.
Worker Mode:
. Worker as an Independent Server:
When the server is started in worker mode, it can connect to the master for data replication, as you mentioned.💪
However, the worker server is not restricted to just replicating data; it also behaves like a typical Redis server.🤖
It can accept client connections and handle read (GET) and write (SET, DEL, etc.) queries independently, just like a master server.🤝
When clients connect to the worker server and send read queries (e.g., GET), the worker can respond to these queries based on its own data.📚
It maintains its own data store, which is a copy of the data it replicates from the master. The data store is used to handle read queries locally.📦
2. Replication from the Master:
🚀In addition to being an independent server, the worker server also continuously connects to the master to replicate data.
It sends a "REGISTER"🔌 command to the master to indicate its intention to replicate.
The master, upon receiving the registration request, adds the worker to its list of connected workers.📋
🚢The worker's primary role, in this case, is to receive and apply replication data sent by the master. The replication data typically includes write operations (e.g., SET, DEL) that the master has received from its clients.🚢
🔄The worker processes these replication data entries as plain Redis commands and applies them to its local data store. This ensures that the worker's data remains consistent with the master's data.🔄
If you have read this, I know you must have thought of 5-10 cases where my code would crumble or there would be data inconsistency.
I too know that. But let's deal with one problem at a time
And if you want to run multiple worker servers, then you need to tweak the code a bit, in the else part, just take the host, and worker port, as input from the user, so based on that you can run what port you like and there is no conflict.
huge respect for backed/network engineers, these ports and socket things fired my brain.

once it's done it looks simple, but believe me, the theory of TCP is very different than the implementation.
also, sockets are a sort of abstraction layer that provides a high-level API for interacting with TCP and UDP protocols.
so pay attention in network classes where they teach about ports and how TCP/udp work, else you will bang your heads on the desk like me, cause you won't know where the connection failed, why it failed and what caused the failure.
I and 3-4 online frens sat down and, we debugged my socket mess at night(2 am) on Discord.
Data Replication in crowRedis:
I've implemented data replication, a crucial feature for distributed systems. Data replication ensures that data remains consistent across multiple database instances, providing fault tolerance and load balancing.
1. Initialization: The data replication process begins during server initialization. I've designed this code to allow one crowRedis instance to act as a master and another as a worker. You, as the system administrator, decide the role during startup.
2. Master-Worker Connection: If you choose to run the server as a master, you'll create a socket and bind it to a specific host and port, making it accessible for other servers to connect. If the server is running as a worker, it connects to the master server using the specified IP address and port.
if __name__ == "__main__":
is_master = input("Are you running as a master (y/n)? ").lower() == 'y'
if is_master:
host = '127.0.0.1'
port = 6381
master_address = None
worker_port = None
redis_server = RedisServer(host, port, is_master, master_address)
else:
master_address = '127.0.0.1:6381'
host = '127.0.0.1'
worker_port = 6382
redis_server = RedisServer(host, worker_port, is_master, master_address)
redis_server.start()
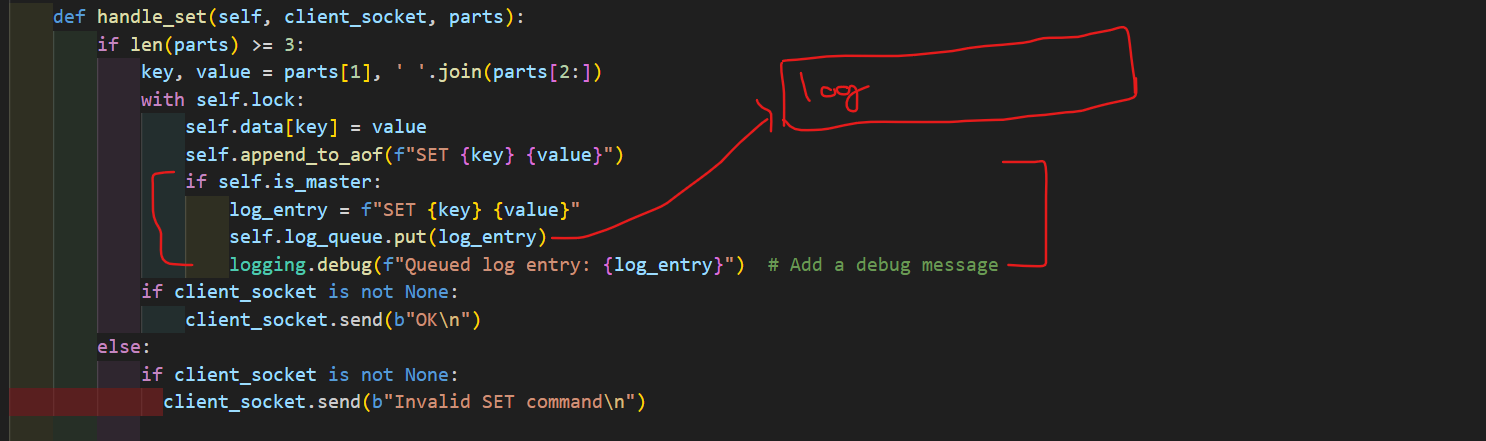
3. Replication Log Queue: To achieve data replication, I've created a queue called log_queue. This queue stores replication log entries generated by the master server. When changes are made to the data store (e.g., a SET command), the log entry is added to the queue.
log_queue = queue.Queue()
4. Replication Thread: A dedicated thread, named replication-thread for the master server and worker-replication-thread for the worker server, is responsible for managing the replication log.
Master Server: When the server is running as a master, the run_replication_log function is executed. This function constantly checks the log queue for new log entries. When a new entry is available, it's sent to connected worker servers.
replication_thread = threading.Thread(target=self.run_replication_log, name='replication-thread')
replication_thread.start()
The run_replication_log function runs on the master server. It continually checks a log queue for new entries. These log entries represent commands that have modified the data in the master server, e.g., "SET key value." When a new log entry is added to the queue, it's sent to all connected worker servers. The master informs the workers about data changes through these log entries.
Worker Server: The worker server, on the other hand, connects to the master server and initiates the replicate_data_from_master function in a separate thread. This function is responsible for receiving replication log data from the master and applying it to the local data store.
def replicate_data_from_master(self):
logging.debug("replicate_data_from_master called")
while True:
try:
data = self.worker_socket.recv(1024).decode('utf-8')
if data:
logging.debug(f"Received data from master: {data}")
# Process the received data and apply replication
self.apply_replication_data(data)
else:
logging.debug("No data received from master")
except ConnectionResetError:
logging.error("Connection with master reset. Reconnecting...")
except Exception as e:
logging.debug(f"Worker socket - {self.worker_socket}" )
logging.error(f"Error replicating data from master: {e}") # Stop replication thread if an error occurs
return
Applying Replication Data: In the apply_replication_data function, I parse and execute the replication log entries received by the worker. This involves checking the command (e.g., SET, DEL) and applying it to the local data store.
def apply_replication_data(self, data):
parts = data.strip().split()
command = parts[0].upper()
if command == "SET":
self.handle_set(None, parts)
# Handle other replication commands as needed
Telling master to let us connect and register
self.worker_socket= socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.worker_socket.connect((master_host, master_port))
self.worker_socket.send(b"REGISTER")
replication_thread = threading.Thread(target=self.replicate_data_from_master, name='worker-replication-thread')
replication_thread.start()
We register the Worker:
def handle_worker_registration(self, client_socket,client_address):
# Handle worker registration here
logging.debug("handle_worker_registration called")
if self.is_master:
# Add the connected worker socket to the list
self.connected_workers.append(client_socket)
logging.debug(f"Worker registered from {client_address[0]}:{client_address[1]}")
logging.debug(f"Number of connected workers: {len(self.connected_workers)}")
logging.debug(f"Connected workers: {self.connected_workers}")
5. Replication Log Entry: A replication log entry is a string that represents a Redis command, such as "SET key value." The master server generates these entries when data changes and pushes them into the log_queue.
log_entry = f"SET {key} {value}"
self.log_queue.put(log_entry)
6. Replication Data Transmission: In the send_replication_log function, I loop through connected worker servers and send them the replication log entries. The worker server receives these entries through its replicate_data_from_master function and processes them.
send_replication_log(self, log_entry):
for worker_socketin self.connected_workers:
worker_socket.send(log_entry.encode('utf-8'))
8. Ensuring Consistency: By following this replication lifecycle, data changes made in the master server are transmitted to worker servers, ensuring data consistency across the cluster. This is a fundamental mechanism for high availability and disaster recovery in distributed systems.
I can write more and more, but I think if you read the code and understand the flow, it will be faster, it's not that complex.
| Master Server (is_master=True) | Worker Server (is_master=False) |
|---------------------------------|---------------------------------|
| AOF mode enabled | AOF mode enabled |
| Main server loop starts | Connects to master |
| Replication log thread starts | Replication thread starts |
| - Queue log entries | - Receive replication data |
| - Send log entries to workers | - Apply replication data |
| Handle client requests | Handle client requests |
| - Update data store | - Update data store |
| - Append to AOF log | - Append to AOF log |
| Transaction handling | Transaction handling |
| Replication log thread | Replication thread |

Issues I faced this time :
Previous things were straightforward, and this was a spiral mess.
1st: so you can set data that can be used by normal clients or workers to replicate data on their side, now this is a tricky thing, cause both send socket commands to the master. During replication, you just set and don't send anything back as a response, but I wrote code such that when you set data you send back a msg via socket to the client, and this would mess up with the workers working cause the worker's replication function was not made to receive and handle a send ok msg to the client back.
so what would happen is, I set data to master, it sends it to the worker, and workerwould just close the connection cause, it would try to send a socket response back, which the replication function is not made to handle, and it would just close the socket.
when I explain the issue now, it is very clear what the issue was, but when I was testing it, in that zone, it took me too long to figure out why I could send one piece of data and it got replicated and then I couldn't send more data.
Even after I found that the connection was closed, I didn't know why and what was closing it, cause sockets are usually always open.

2nd : uhh I was listening for worker requests at the start of the program using one socket where It was receiving requests and seeing if the msg is "REGISTER", to see if a woker is registering.
it was something like message_bytes = client_socket.recv(8), so you see REGISTER is 8 bit so it would handle it accurately.
but you see, since it's at the top, it also would receive the commands from the client like SET KEY VALUE, but these commands are more bits than 8 right, so the first time I would just get an error, and I couldn't figure out why I am not able to use SET KEY VALUE, previously it worked lol.
and there is another client_socket that receives 1024 bits of data, this is what used to handle my set, get etc commands, but since I put thatmessage_bytes = client_socket.recv(8)
at the top, it would try to receive these commands also and I would get an error.
stupid brain, he should have thought of this, caused too much pain in my empty head
Solution :
def handle_client(self, client_socket,client_address):
try:
while True:
request = client_socket.recv(1024).decode('utf-8')
if not request:
break
if self.is_master and request == "REGISTER":
self.handle_worker_registration(client_socket,client_address)
parts = request.strip().split()
command = parts[0].upper()
if command == "SET":
self.handle_set(client_socket, parts)
elif command == "GET":
self.handle_get(client_socket, parts)
def handle_worker_registration(self, client_socket,client_address):
# Handle Worker registration here
logging.debug("handle_worker_registration called")
if self.is_master:
# Add the connected worker socket to the list
self.connected_workers.append(client_socket)
so we receive all requests in one place and then differentiate what to do based on the msg, the client will send a msg so will the worker, and based on that msg we call appropriate functions.
Current Limitations:
1: Data inconsistency and synchoronization issues:
When running the server in worker mode, it not only replicates data from the master but can also act as an independent server where you can write data. This can lead to data inconsistency if you write data to the worker or multiple workers, as the workers may contain data that the master does not possess or have knowledge of.
This is a common issue in distributed computing.
One potential solution is to restrict the worker servers to only receive data and disable their write operations.
Or I can transform each server into a peer-to-peer network where everyone shares data; I've heard that there are specific protocols and algorithms designed for this purpose.
Subscribe to my newsletter
Read articles from Biohacker0 directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Biohacker0
Biohacker0
Making cool stuff