Why Uber ditched Postgres Monolithic database and why you should too.
 Ian Carson
Ian CarsonWith the advent of better and more efficient tools and infrastructure, companies are starting to consider improving and completely phasing out some of the previously used tools. Uber is not an exception. Recently, they moved their critical trip data to an in-house database known as Schemaless.
According to their claims, Schemaless is a scalable and fault-tolerant datastore. However, Schemaless is a wrapper built on MySQL. But what makes it amazing? To answer this, let's focus on the architecture behind Schemaless.
Schemaless is made up of two nodes.
Worker nodes.
Storage nodes.
The job of the worker nodes is to receive requests from clients, fan out those requests to the storage nodes, and aggregate the results. The storage node stores the actual data. The data itself is divided into a fixed number of shards.
Why is there a need for two separate nodes then?
Well, this is because having separate nodes allows Uber to scale each part independently. Each shard is mapped to a particular storage node. The shards are also replicated to other storage nodes. The number(replication factor) can be controlled by the configuration. For example, the typical replication factor comprises 3 nodes- one primary and two replicas. The replica nodes are distributed across multiple data centers to maintain data redundancy in case of an outage.
The below photo from @progressiveCod2 on Twitter(X) visually demonstrates this concept.
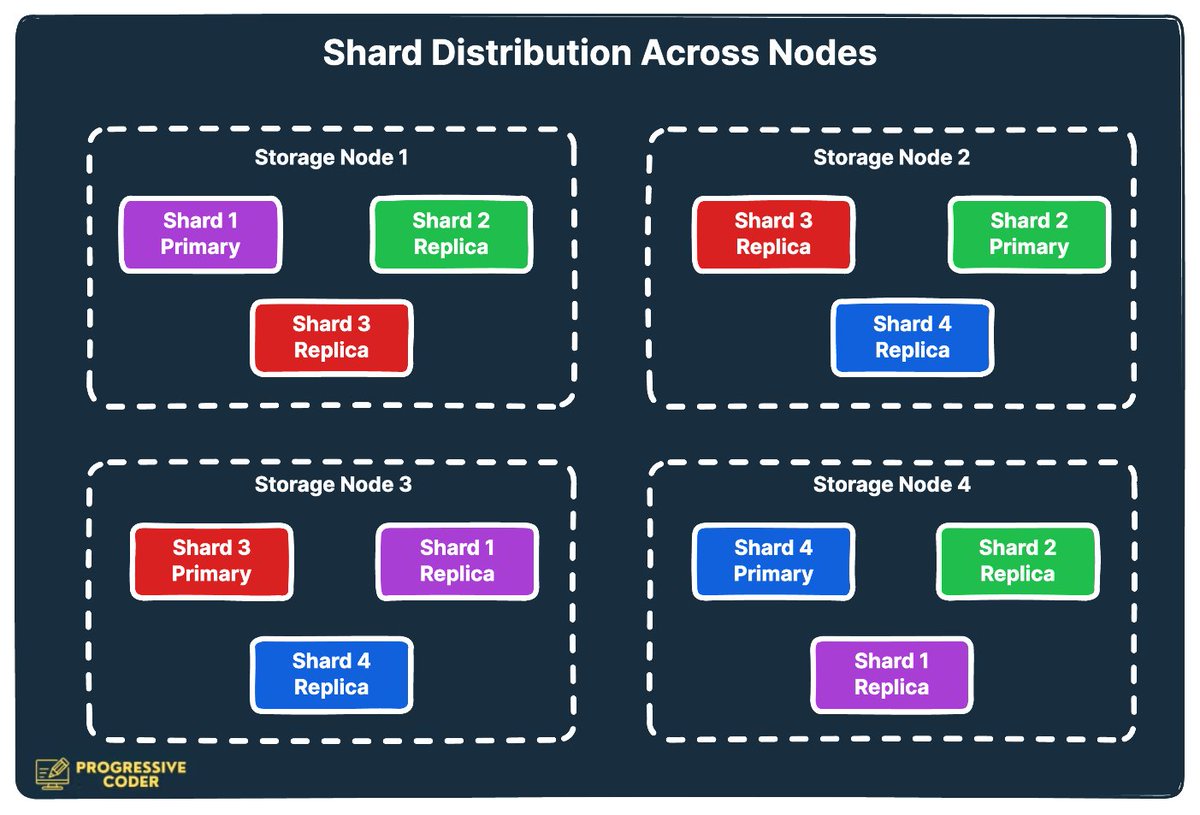
Given that this is the scenario, what happens during Read and Write?
Well, during read, a request is made to the Schemaless DB, the worker node can read the data from any storage node. The client can configure the request to be read from the primary or the replica nodes. By default, the primary is chosen guaranteeing a read-after-write consistency. It is a guarantee that if the client makes some updates, they will see their updates.
During write, all writes go to the primary node. A replica going down doesn't impact the Writes. If the primary node goes down, Schemaless will still accept the write requests. However, the data is persisted to the disk on another randomly chosen primary node. This ensures data availability.
There are some tradeoffs to be considered here as well. Subsequent read requests cannot read this writes before:
The primary node comes up again.
The replica node is promoted to the primary node.
This approach is often described as Buffered writes. More on this on an upcoming article. For now, thank you for your time.
Subscribe to my newsletter
Read articles from Ian Carson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ian Carson
Ian Carson
A Disciplined, keen on details, and curious problem solver. I read and code a lot. I believe in Teamwork, Accountability, Transparency, and Competency.