Speech Analysis: Accessing whisper.cpp in Python
 Richard Thompson
Richard Thompson
In the conclusion of my last article - about my search for a suitable Open-Source Automatic Speech Recognition (ASR) model - I decided to try and pursue whisper.cpp as a model, along with a set of Python bindings that allow us to access the otherwise C++ model with Python.
Rather than just jump straight into the implementation, let's take some time to understand what I'm going to be working with - the Whisper model, as well as its C++ port.
Open AI's Whisper Model
Reading through the whitepaper explaining the Whisper approach to speech-to-text conversion, I've become more confident that it seems to be the right approach. The paper suggests that Whisper represents an improvement over wav2vec2 - which uses unsupervised learning on auditory data that hasn't been labeled. This is because they still require fine-tuning to actually perform speech recognition, which itself is a challenging process.
This makes sense of what I found in my previous article when trying to find an easy-to-use out-of-the-box speech recogniser.
With Whisper, OpenAI has trained a model on a wide variety of sources, rather than a single training source. This markedly improves accuracy. The amount of training data has been increased by an order of magnitude to 680,000 hours of 'weakly supervised data,' meaning speech that has been labelled, but not directly examined for accuracy - hence 'weakly supervised'. They've constructed the dataset with audio that is paired with transcripts on the internet and used various filtering methods to remove lower-quality and machine-generated text.
The last thing to say before we move on is that Whisper utilises a Transformer model. I don't know enough about this architecture yet (the Whisper architecture is explained on this nice looking page here) - other than it being responsible for the latest most advanced AI Language Models, Chat GPT et. al.
Rather than delve any further into the architecture here, I'll just say that this seems to be a powerful model and if I can integrate it into my little program, I think I'll be pretty close to utilising the cutting-edge of speech recognition technologies.
For completeness, the GitHub page of the Open Source code for Whisper is here. It's written in Python but requires a GPU to be able to be run. Leading us on to whisper.cpp....
Whisper.cpp
Now, a very interesting and talented gentleman named Georgi Gerganov (GitHub here) has ported Whisper into C++, which seems to allow for a number of benefits:
Inference can be run on CPU - no fancy graphics processor card required.
Generally a lighter-weight program so can run on smaller devices, e.g. smartphones, etc.
It's probably worth noting that Mr. Gerganov is also responsible for llama.cpp, which allows quantized (reduced-resolution) language models to be run on a standard Macbook (i.e. CPU-only inference). Good news for me and many other thousands of people I'm sure. Nothing quite like running a chatbot in a linux terminal on your laptop with no internet connection. I'm looking forward to jumping into language models a little later in my studies.
So this is all good. We have something powerful and lightweight.
Here's a nice little web demonstration of whisper.cpp that allows you to transcribe audio from the microphone or from a file.
And here's a cool little demonstration using whisper.cpp along with llama.cpp assumedly to have four different chat bots speaking to each other in a podcast format.
Setting up PyWhisperCpp in My Python App
Another talented gentleman Abdeladim Sadiki has kindly written some Python bindings for whisper.cpp. This enables us to interact with the program through Python. Great.
The same person seems to have written some Python bindings for Llama.cpp as well. That could be useful later!
For now I'm interested in implementing a kind of assistant model, which listens and responds to commands.
As I'm running a virtual environment with VS Code for my VoxPlan app, I installed the package as so:
pip install pywhispercpp
I then dropped the very few lines of code into my existing app...
To be met with an error:
OSError: PortAudio library not found
It looks like pywhispercpp uses a library called sounddevice to stream data from the microphone. While I don't quite yet understand how it does this, I've seen something similar in another voice-activated personal assistant app, and it seems to provide some kind of buffer, assumedly so the program can grab utterances of varying length.
A brief glance at the documentation implies that the module can somehow store an audio recording as a NumPy array (an array of numbers). That's awesome.
I just noticed one of the example programs on the sounddevice docs page is to plot microphone signals in Real-Time. That's definitely going to come in handy later, so I can show a snazzy audio wave when the speech recognition function is working in my app.
While the sounddevice module was installed, it looks like something it depends on, namely the PortAudio library, isn't installed as of yet.
Looks like this did the trick.
sudo apt-get install libportaudio2
Next, all I needed to do was add this code into my app:
from pywhispercpp.examples.assistant import Assistant
my_assistant = Assistant(commands_callback=print, n_threads=8)
my_assistant.start()
And now I'm able to recognise speech... In theory at least..
Here's a list of test command phrases that I want to be able to use:
COMMANDS TO TEST WITH VOICE COMMAND ON VOXPLAN
- NEW GOAL
- EDIT GOAL
- CREATE NEW SUBGOAL
- DELETE GOAL
- BYE BYE
- UP, DOWN, LEFT, RIGHT
- ACTIVE FOCUS MODE
- GOAL EDIT MODE
- PAUSE, CONTINUE
- BRAINSTORM
- THINGS TO DO TODAY
- STUDY ARTIFICIAL INTELLIGENCE
- MEDITATE
- LANGUAGE LEARNING
And here is what I got:
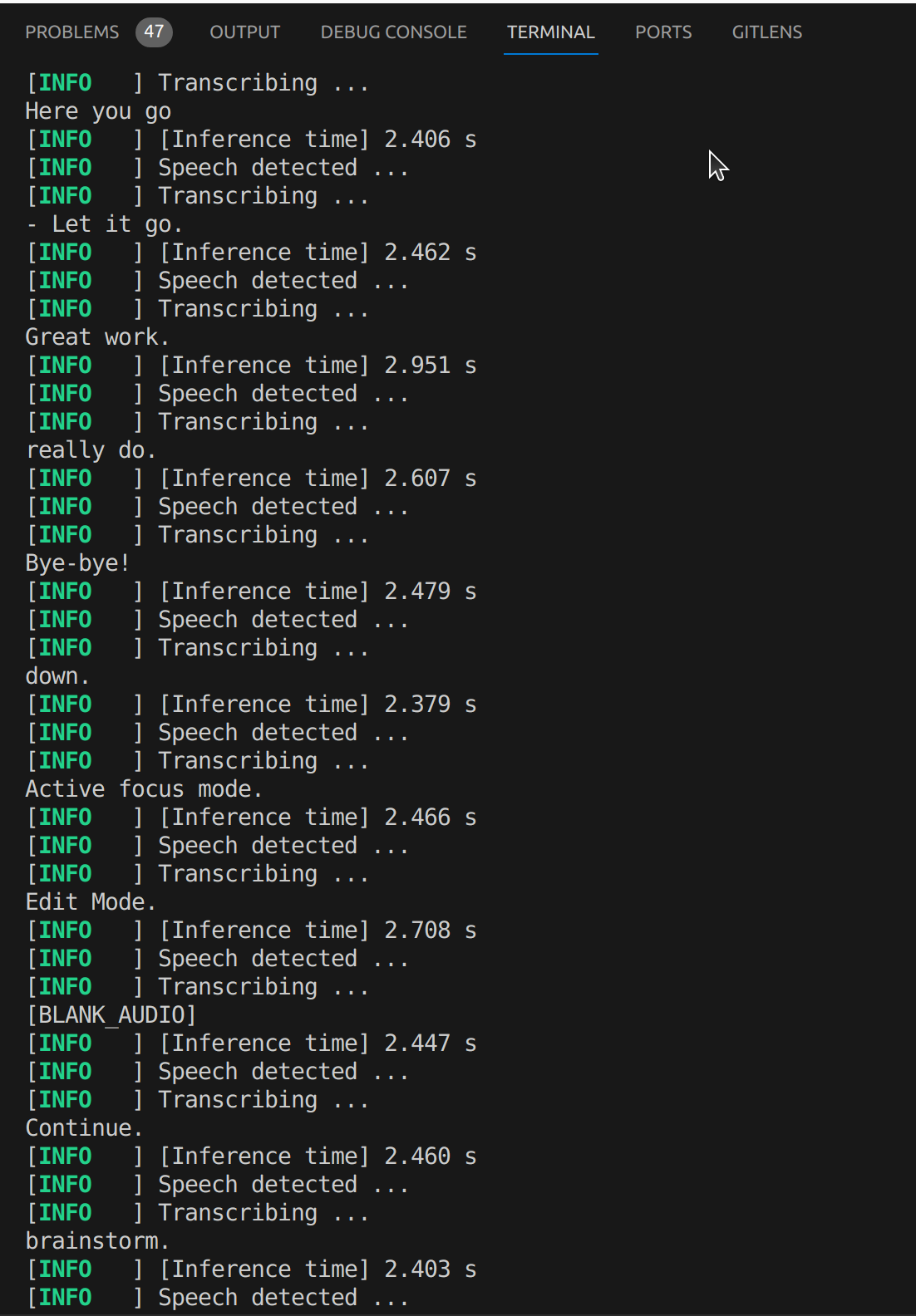
HMMMMMMM....
Whoever said you don't get something for nothing... Was right.
We're getting some input, but the accuracy seems to be very low. The latency is high as well. I imagine piping the program through python to whisper.cpp and back again to deliver the resulting message, isn't great in terms of performance. Plus I'm only running this on an old Macbook Pro.
Setting up Pocketsphinx in my Python App
Given the poor results above, I thought I'd try Pocketsphinx...
The simplest version of a Python speech recogniser using Pocketsphinx is very, very simple:
from pocketsphinx import LiveSpeech
for phrase in LiveSpeech():
print(phrase)
So let's see how we did...
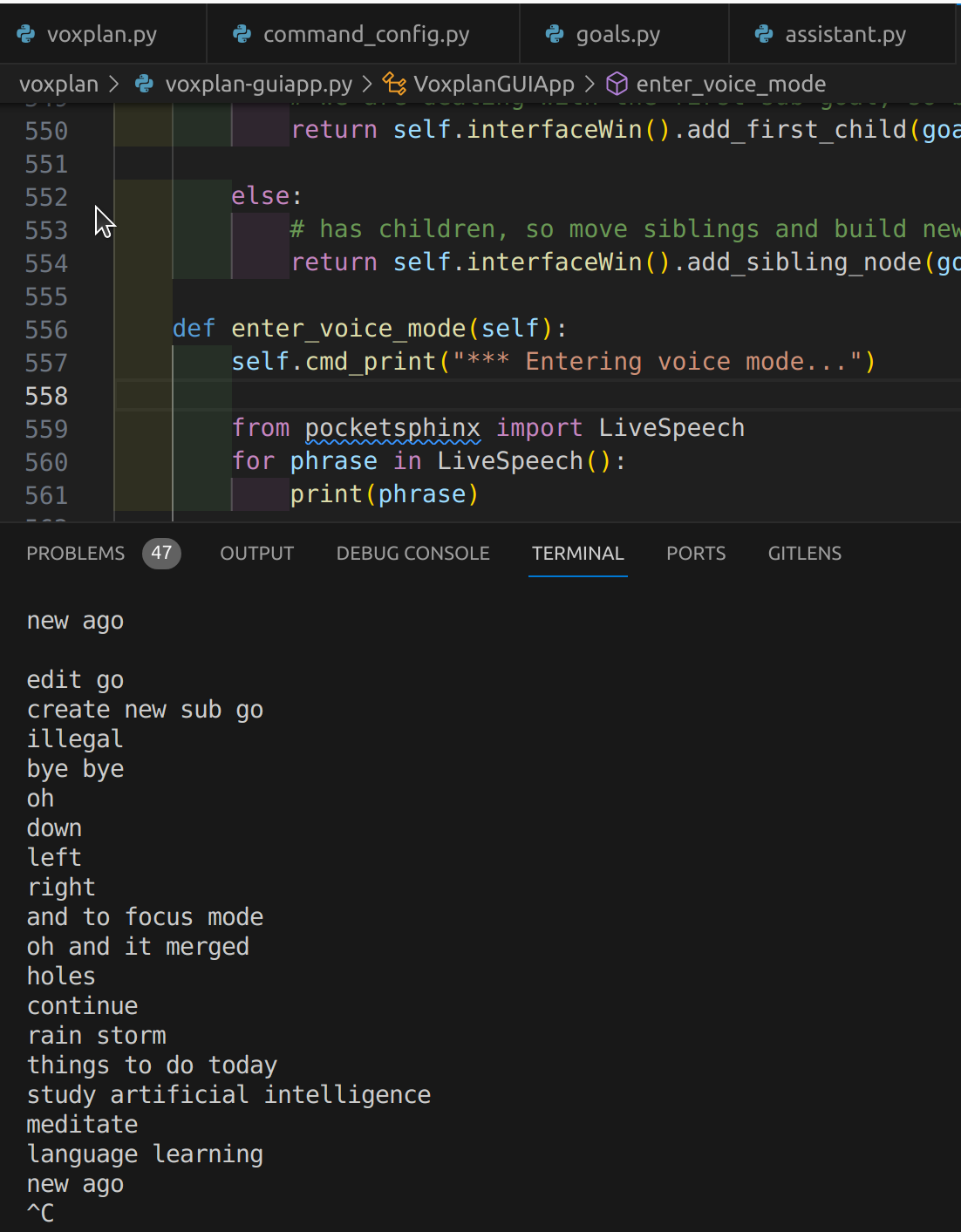
HMMM... Yes just as bad if not worse.
Now, we should bear in mind that these methods aren't constrained by a language model at all and have been implemented with pretty much 3 lines of code each.
I'm sure if all the commands were longer utterances, there would be more to constrain the recogniser and the results would be better. Single words seem to be a problem - not surprisingly, as there's no context to help in the understanding.
A language model would constrain the model's listening to a specific list of commands that are specified by the program. As the domain of potential utterances we are looking at is going to start out very constrained, it would be nice if we could somehow use a language model to constrain the options. However, I'm not sure how easy that would be to implement.
A possible method of doing this in the future could be to simply fine-tune a pre-trained recognition network with a set of potential command words, to provide a kind of helping-hand to improve accuracy. This would involve introducing some additional layer(s) onto the end of an existing model, to nudge the output towards our set of command-words. This is obviously a more in-depth solution and quite outside of my current skillsets.
The latency of PyWhisperCpp is a bit too long, and accuracy too low. I definitely need to find a way of improving accuracy if I decide to use Pocketsphinx.
I think there is also a third option for implementing speech recognition in Python, so we'll look at that next, then make a plan of action for this next phase.
Well, after a few simple commands:
apt-get install portaudio19-dev libportaudio2 libportaudiocpp0
pip install pyaudio
pip install SpeechRecognition
I have a speech_recognition module, which I test simply using:
python -m speech_recognition
Calling the module using -m ensures the module calls and interprets the code in '__main__.py' , which in this case directly launches our speech_recogniser. And here is what we got:
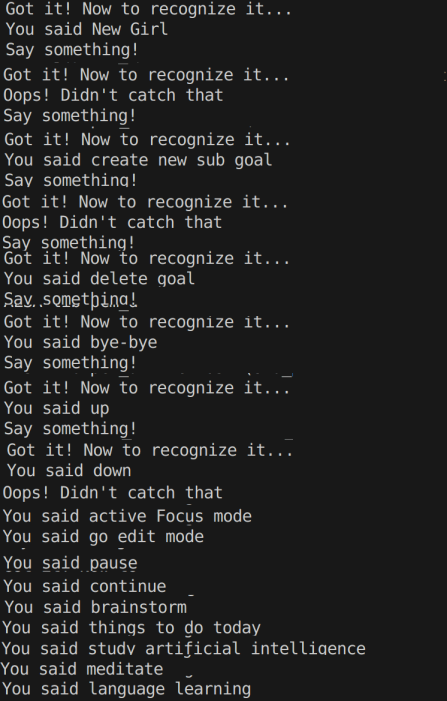
... You'll have to excuse my slightly dodgy editing (I've just discovered the fantastic Pinta app for linux. It's like the old MS Paint but even better! I had to edit out a bunch of error messages, but the results are apparent.
As you can tell, I'm very happy with the output of this one, and again, it hardly took any code to implement. However, I've just realised the reason the results were so good is that by default, the speech_recognition module connects with the Google web speech API!!
Doh...
This means we're not doing any of this recognition offline and we depend on an internet connection for success. I switched it over to the sphinx offline mode and got basically worse results than I did for PocketSphinx above! >:0
I should have known it wouldn't be so easy!
Back to the drawing board.....
Conclusion
It seems I can get reasonably accurate and low-latency speech recognition with minimal Python code by using the speech_recognition module, along with Google's Web speech API. Assumedly any other web API would be of a similar quality. As I outlined in my previous article, however, I am ultimately looking for something that can operate offline, and this probably means training a model, or at least, fine-tuning a model myself, based on a subset of command words.
It looks like more research is required to figure out speech recognition for simple commands if I don't want to use Google's (or anyone else's) web API.
Summary:
'The Easy Way' (quick & dirty) involves using online calls to any one of a number of different online services, which run complex models on advanced hardware and supply API interfaces which operate at very low latencies - even lower than we can achieve running a local model (Whisper CPP via Python API calls).
'The Hard Way' (slow but clean) probably involves choosing a sophisticated model and fine-tuning it to the specific commands we are using, or at least to the "one-shot" type command-interface we're using in this application.
I'm sure any of the models we've looked at would be most suitable for something like transcription of long auditory sequences, but short phrases or single words require some additional contextual input into the models we've loked at, as far as I can tell with my admittedly limited experience of the Automatic Speech Recognition (ASR) field.
The journey continues...
Subscribe to my newsletter
Read articles from Richard Thompson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Richard Thompson
Richard Thompson
Spending a year and a half re-educating myself as a Cognitive Scientist / Ai Engineer.