The Evolution of HTTP: From HTTP/1 to HTTP/3. Why HTTP/3 is the Future?
 Ritwik Math
Ritwik MathTable of contents

In the world of networking and data exchange, HTTP, short for Hypertext Transfer Protocol, takes center stage as a fundamental application layer protocol. This crucial protocol serves as the backbone for transmitting data between devices connected to the vast expanse of the internet. Whether it's in the form of JSON, XML, plain text, HTML, or other data formats, HTTP effortlessly facilitates this transfer.
HTTP operates through a simple yet powerful model involving two key entities: the client and the server. The client initiates the process by sending a request to the server, and in response, the server efficiently delivers the requested data back to the waiting client. It is this seamless interaction between client and server that forms the core of HTTP, making it an indispensable part of the modern digital landscape. In this article, we'll delve deeper into the inner workings of HTTP, exploring its functions, uses, and importance in modern technology.
HTTP/1.*
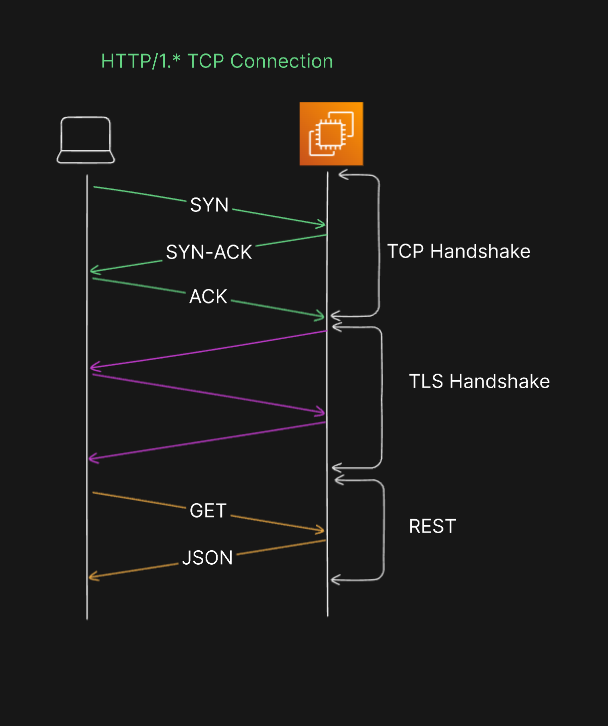
The initial incarnation of HTTP, known as HTTP/0.9, made its release as the very first version. Five years later, in 1996, HTTP/1.0 was introduced, marking a significant milestone in the protocol's development.
HTTP/0.9 was a rudimentary beginning, offering only the GET method for fetching resources. However, with the emergence of HTTP/1.0, the protocol received a substantial upgrade. HTTP/1.0 introduced support for additional methods such as POST and HEAD, providing more versatility in handling data transfer. Furthermore, HTTP/1.0 brought essential features like HEADER, Content-Type, and Status Code into the mix, enhancing the protocol's capabilities.
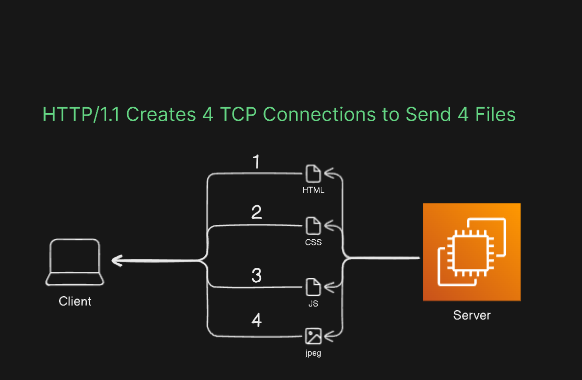
One notable characteristic of HTTP/1.0 was its use of TCP (Transmission Control Protocol) to establish connections between clients and servers. Under this version, each request from the client to the server necessitated the creation of a new TCP connection. While this approach worked for a time, it began to exhibit limitations as websites expanded in size and the volume of content surged. As a result, the need for a more efficient solution led to the development of HTTP/1.1, which addressed these performance issues and ushered in a new era of web communication.
HTTP 1.1 was released merely one year after the release of HTTP 1.0. HTTP 1.1, a significant advancement over its predecessor, brought a more extensive repertoire of HTTP methods into play. In addition to the familiar GET, POST, and HEAD methods, HTTP 1.1 introduced new methods like DELETE, PATCH, PUT, CONNECT, TRACE, and OPTIONS, providing greater flexibility in data interaction and manipulation.
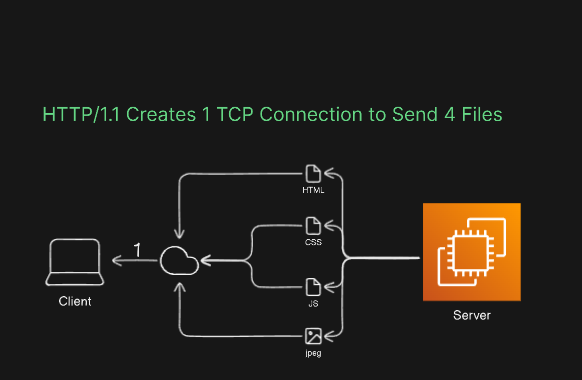
However, the standout feature of HTTP 1.1 was its remarkable performance improvements compared to HTTP 1.0. In the era of HTTP 1.0, fetching multiple pieces of content could be a sluggish process due to the necessity of establishing a new TCP connection for each request. HTTP 1.1 addressed this issue by introducing a groundbreaking concept known as 'HEADER keep-alive.' This innovation enabled clients and servers to transmit multiple pieces of content over the same persistent TCP connection, eliminating the need to create new connections repeatedly.
The implementation of a 'keep-alive timeout' on the Message Processor played a pivotal role in this improvement. This timeout mechanism allowed a single TCP connection to serve as the medium for sending and receiving multiple HTTP requests and responses to and from the backend server. In essence, it revolutionized the efficiency of data exchange by replacing the cumbersome practice of opening a new connection for every request and response pair.
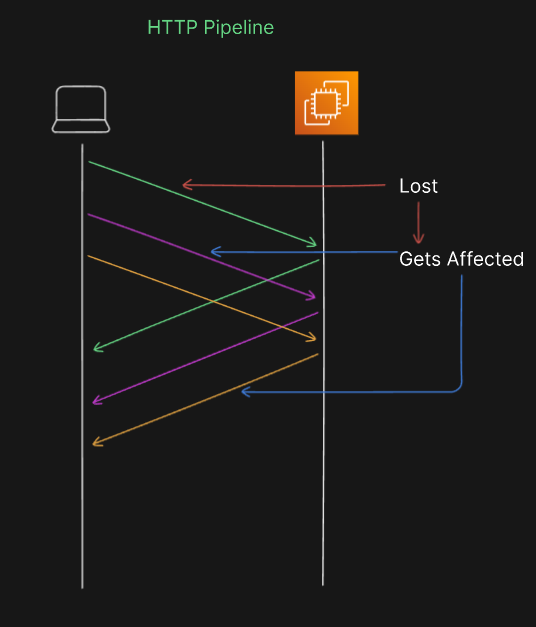
HTTP 1.1 tried to use a feature called 'pipeline,' which was meant to help browsers send many requests at once without waiting for each one to finish. But there was a problem. If one of those requests got messed up or lost, it could block the others from working. So, they had to remove this feature.
Now, to balance between saving resources and being fast, browsers use multiple connections to send requests at the same time.
HTTP/2
HTTP/2 came out in 2015 with some cool improvements. It introduced something called 'HTTP streams' to make web pages load faster. Here are some of the neat things it does:
Multiplexing: This means it can send lots of requests at the same time over a single connection. So, web pages with many things on them load faster. This also fixes a problem from the older HTTP/1.1 where one slow request could hold up others.
Binary Protocols: This helps in transferring data more efficiently and securely. It uses a special way of sending data as 1s and 0s, making it faster.
Mandatory Encryption: In HTTP/2, data must be encrypted. This is like making sure your information is in a secret code when it's sent.
Header Compression: HTTP/2 uses a trick to make things even faster by reducing extra stuff sent with each request. TCP's slow-start mechanism is prevented.
Push Capability: The server can inform the client about new updates without the client needing to poll.
All these things work together to make the web faster and more secure with HTTP/2.

Why HTTP/2 did not become popular?
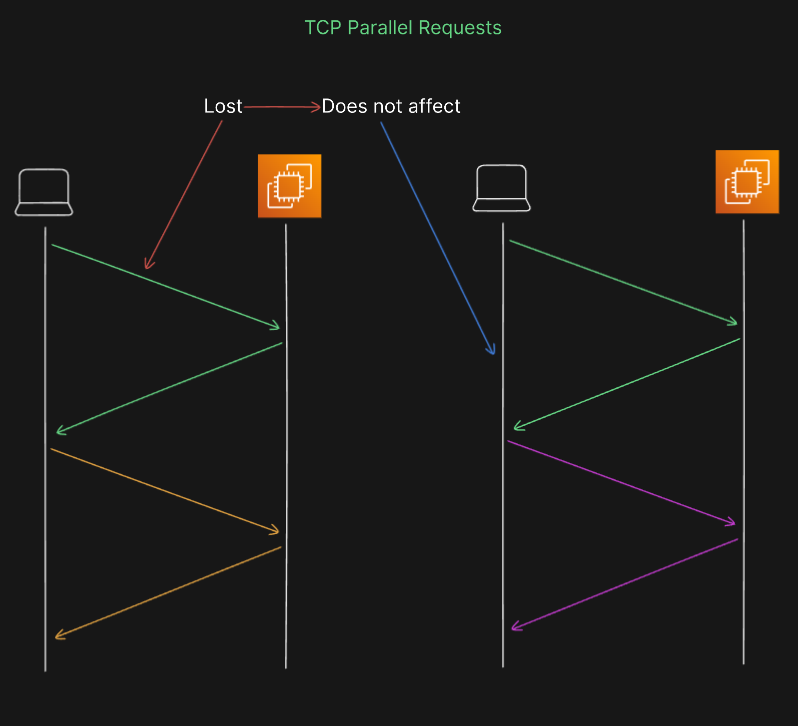
The picture above shows how HTTP/2 should work, but in reality, it's not that simple with TCP. TCP doesn't handle multiple things at once as HTTP/2 suggests. If a request for an HTML file doesn't go through, TCP will keep trying until it gets the file. And while it's busy with that, all the other requests have to wait. This waiting causes a problem called 'head of line blocking.' So, when a packet is lost in HTTP/2, it takes much longer to recover than in HTTP/1.1, where many requests can go on at the same time. This a bit confusing but in reality HTTP/2 does not work in the TCP layer as it was proposed.
Practical Roadblock:
Multiplexing in HTTP/2 put a big load on our servers. Imagine a bunch of requests arriving all at once, like a big crowd showing up at a party. This made our servers work extra hard. Plus, in HTTP/2, the requests didn't arrive one by one, but all together, so they started almost at the same time. This made it more likely for some of them to take too long and not finish in time.
Difference Between HTTP/2 and Websockets
Websockets and HTTP/2 are different in how they communicate.
Websockets can talk back and forth, like having a two-way conversation. But HTTP/2 is more like taking turns in a conversation; first, you talk, and then you listen.
With Websockets, both the sender and receiver can talk whenever they want. But in HTTP/2, only the sender (usually your computer or phone) can ask for things and get responses.
Websockets don't need to do extra security checks, so they're faster. On the other hand, HTTP/2 is better if you want to keep things secure and efficient for normal web browsing or using web services.
If you need quick, back-and-forth chats with low delays and lots of data, go for Websockets. But if you want a balance between security and efficiency, HTTP/2 is your choice. Sometimes, it's even good to use both to get the best of both worlds.
HTTP/3
HTTP/3 is the latest and greatest thing in web development. It's the first big update to the way the web works since HTTP/2 back in 2015.
One of the big changes with HTTP/3 is that it uses a brand-new transport protocol called QUIC. This new protocol is designed for the way we use the internet today, especially on our smartphones. We're always on the move, switching between networks as we go about our day. That wasn't the case when the first internet rules were made - back then, our devices didn't move around as much.
QUIC also means that HTTP/3 uses a different system called the User Datagram Protocol (UDP) instead of the old one called the Transmission Control Protocol (TCP). Using UDP makes things faster and gives you a speedier experience when you're surfing the web.
New Features
QUIC is here to solve some of the problems we had with HTTP/2:
It makes your internet on your phone work better when you go from Wi-Fi to using your cellular data, like when you leave home or the office.
It also helps when some of your data gets lost on the way. With QUIC, losing one piece of data won't slow down everything else, which used to be a problem known as 'head-of-line blocking.'
QUIC
QUIC, which stands for Quick UDP Internet Connections and is pronounced 'quick,' is a new network protocol created by Google. Its main aim is to make the internet faster by reducing delays, especially when compared to the older TCP protocol.
How QUIC Handles Packet Loss
Each transmission in QUIC includes a packet-level header, which serves to convey essential information such as the encryption level and a packet sequence number (known as a packet number). The encryption level defines the packet number space. What's important is that packet numbers are never repeated within a packet number space throughout a connection's entire lifespan. Within each space, packet numbers are sent in a constantly increasing order, which avoids any confusion or ambiguity.
This design simplifies the process, eliminating the need to distinguish between initial transmissions and retransmissions. By doing so, QUIC reduces the complexity involved in how it handles TCP-like loss detection mechanisms. QUIC packets have the capacity to carry various types of data frames. The recovery mechanisms within QUIC make sure that both data and frames requiring dependable delivery receive acknowledgment or, when necessary, are declared lost and then sent again in new packets. This approach ensures reliable data transfer and efficient error recovery. See QUIC Loss Detection and Congestion Control
Conclusion
In conclusion, the introduction of HTTP/3 with the QUIC transport protocol marks a significant leap forward in the evolution of web communication. With its focus on reducing latency, solving issues like head-of-line blocking, and enhancing the overall user experience, HTTP/3 is poised to reshape the way we browse the internet. The transition from the traditional TCP to the more agile UDP not only promises faster connections but also adapts seamlessly to the modern, mobile-centric lifestyle. This change is not just a technical upgrade but a testament to the continuous innovation in web development. As the internet continues to evolve, so does the technology that powers it, and HTTP/3 is at the forefront of this exciting transformation. Its adoption, along with the ongoing collaboration within the internet community, ensures that our online experience remains secure, efficient, and future-proof. Whether you're a web developer, a casual user, or a technology enthusiast, the arrival of HTTP/3 represents a promising step toward a faster, more reliable, and user-friendly internet.
Subscribe to my newsletter
Read articles from Ritwik Math directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ritwik Math
Ritwik Math
As a seasoned senior web developer with a wealth of experience in Python, Javascript, web development, MySQL, MongoDB, and React, I am passionate about crafting exceptional digital experiences that delight users and drive business success.