How Git Works Internally?
 Rishabh Chandel
Rishabh Chandel
All of us use git on a daily basis. But how many of us know what goes on under the hood? In this blog post, we will take a deep dive into the inner workings of Git.
How does Git store data?
Git is a content-addressable file system, which means it’s a key-value store where you can insert any type of content and get back a unique key that you can later use to retrieve that content.
| Key | Object |
| accefceba62b4874a613a2336de33ee716e99931 | console.log(”Hello World!”); |
| deb909034d4053be6bdc041e8280e6d0f6eecfe | console.log(”Foo Bar”); |
The key is generated from the content of the object, using the SHA-1 hash function. So, two files having the same content will have the same key🧐(more on this later). Also, git compresses the content of the object using the zlib library to save disk space.
If you have used git before, then you have probably seen the directory called .git.This is where git stores almost everything. The object database is stored in the .git/objects directory.
Git Objects — blob, tree, and commit
In Git, the contents of files are stored in objects called blobs, binary large objects. These blobs are different from regular files because they don't keep any extra information like when they were created or their names. Each blob is identified by a unique SHA-1 hash. SHA-1 hashes consist of 20 bytes, often represented using 40 characters in hexadecimal form(In this blog, we may occasionally display only the initial characters of this hash).
Let’s add a file to git and see, what a blob object and its hash look like.
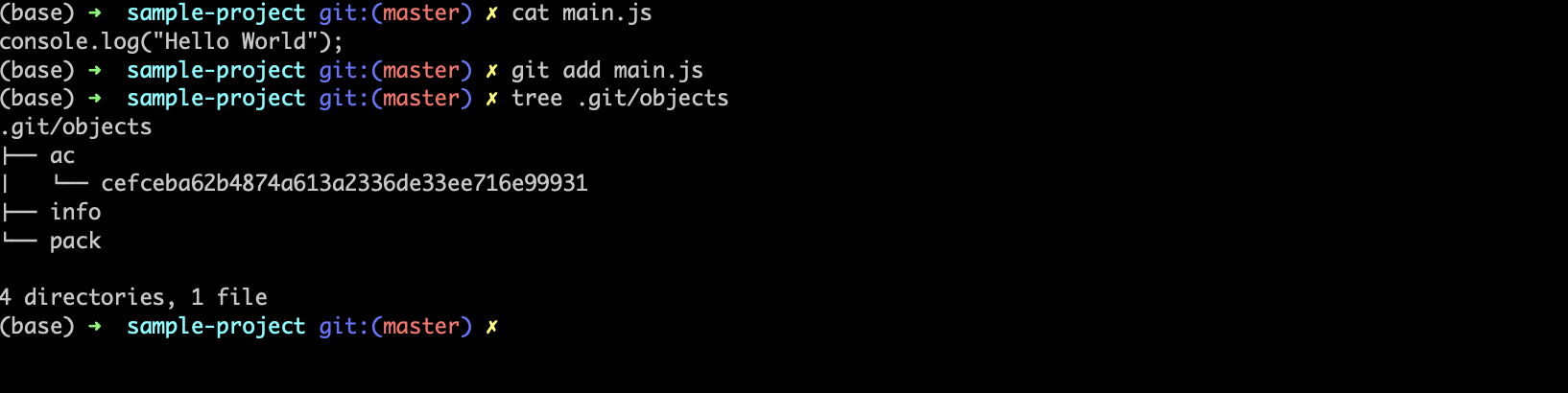
Here a new object is created with a key accefceba62b4874a613a2336de33ee716e99931(Note Git utilizes the initial two characters of the SHA-1 hash as a directory name and the remaining characters are used as the filename for the file that actually contains the blob. Git does this to reduce the number of files per directory).
We can check the type & content of the object by following commands:

Now let's create another file and add it to git.
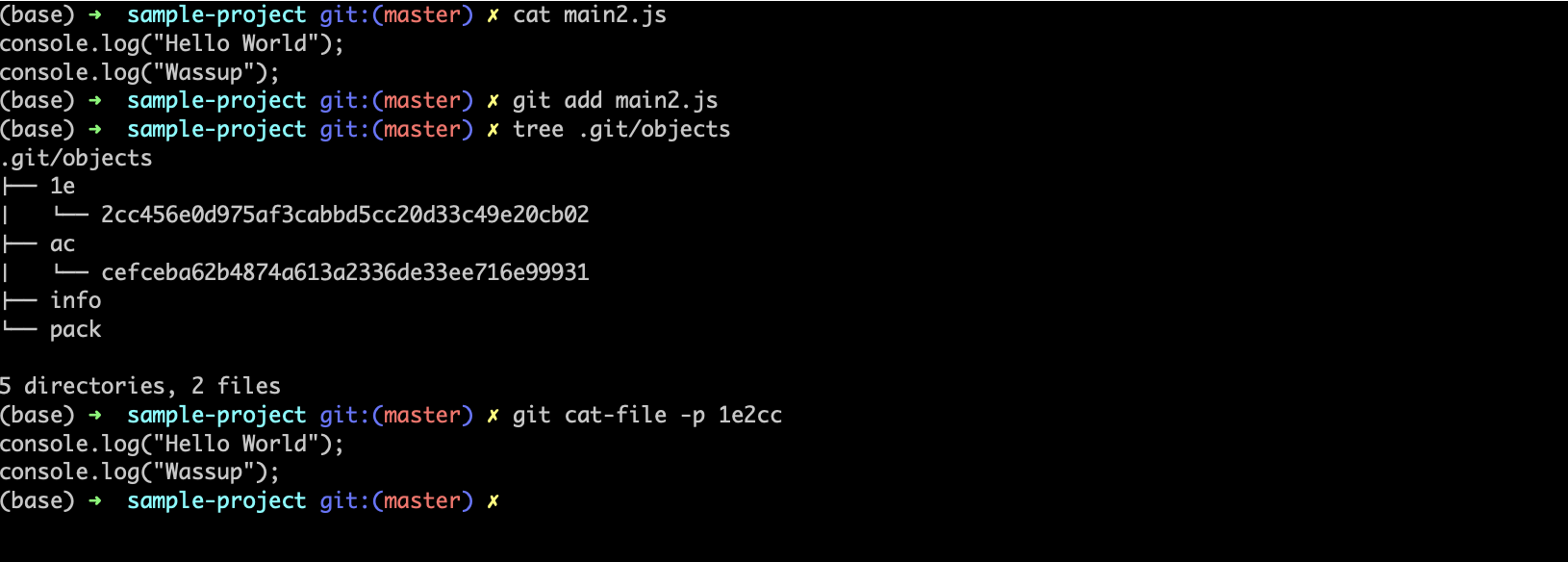
As you can see from the main2.js a new blob object is created with a different key since the content of the file is different. What if the content of 2 or more files has the same content?
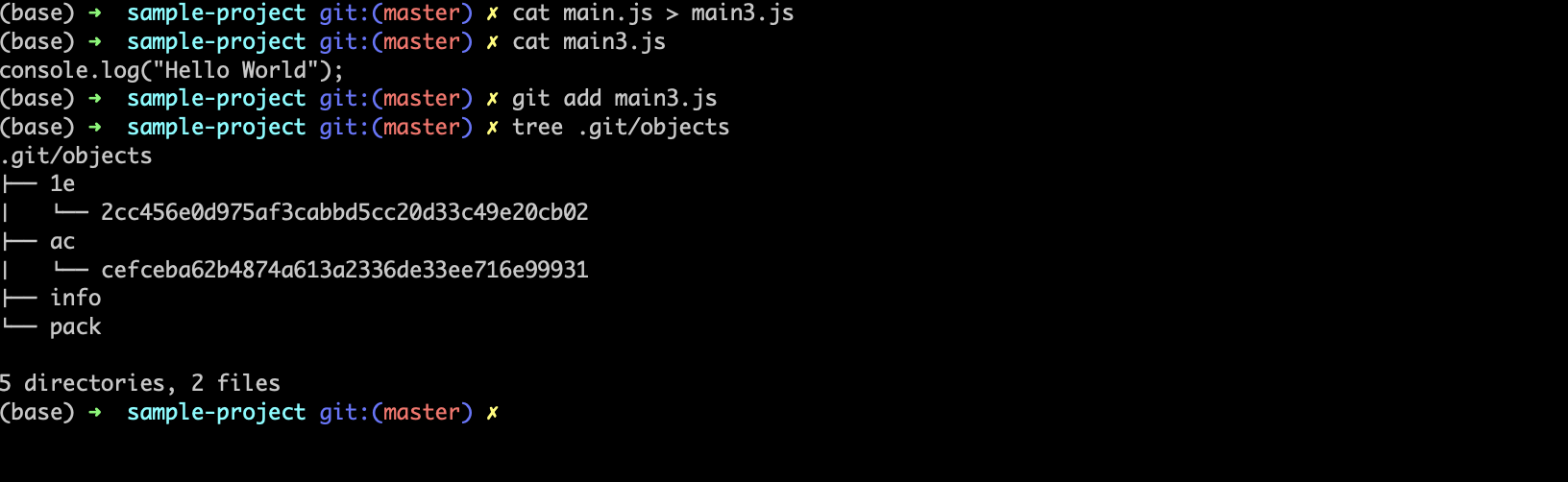
Git does not create duplicate objects 😉.
In git, the equivalent of a directory is a tree. A tree is basically a directory listing, referring to blobs as well as other trees. Trees are identified by their SHA-1 hashes as well.
Let’s take a snapshot of that file system — and store all the files that existed at that time, along with their contents.
In Git, a snapshot is represented as a commit, containing a reference to the main tree (the root directory) and additional metadata, including the committer, commit message, and commit timestamp. Typically, commits also have one or more parent commits, representing previous snapshots. These commit objects are also identified by SHA-1 hashes, which you often encounter when using git log.
Let’s restructure our code a bit and make the first commit. Move the files main2.js main3.js to directory src and commit. Our directory and git objects will look something like this:
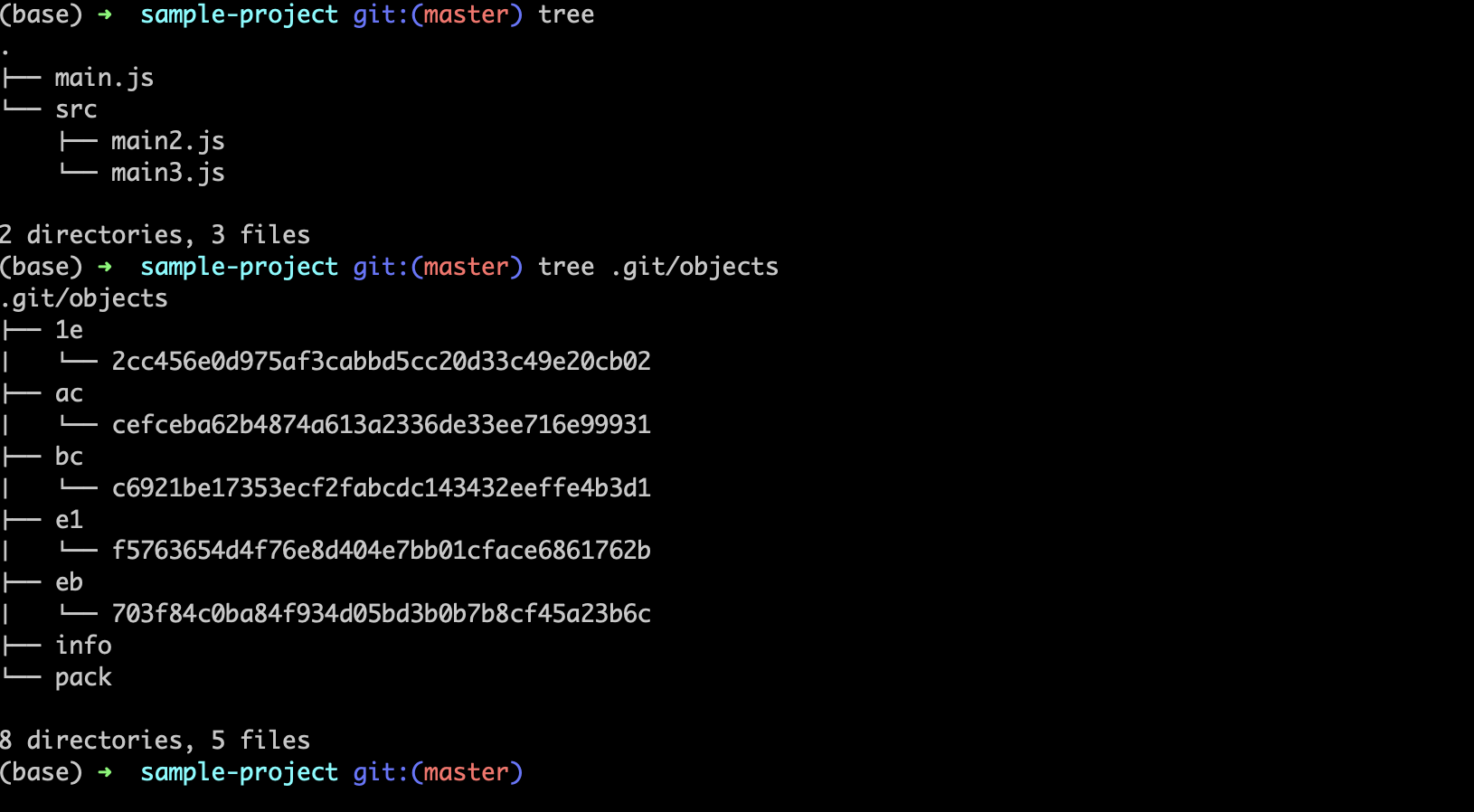
Time to traverse this git graph of objects. We will start from the commit. Get the commit hash using the command git log

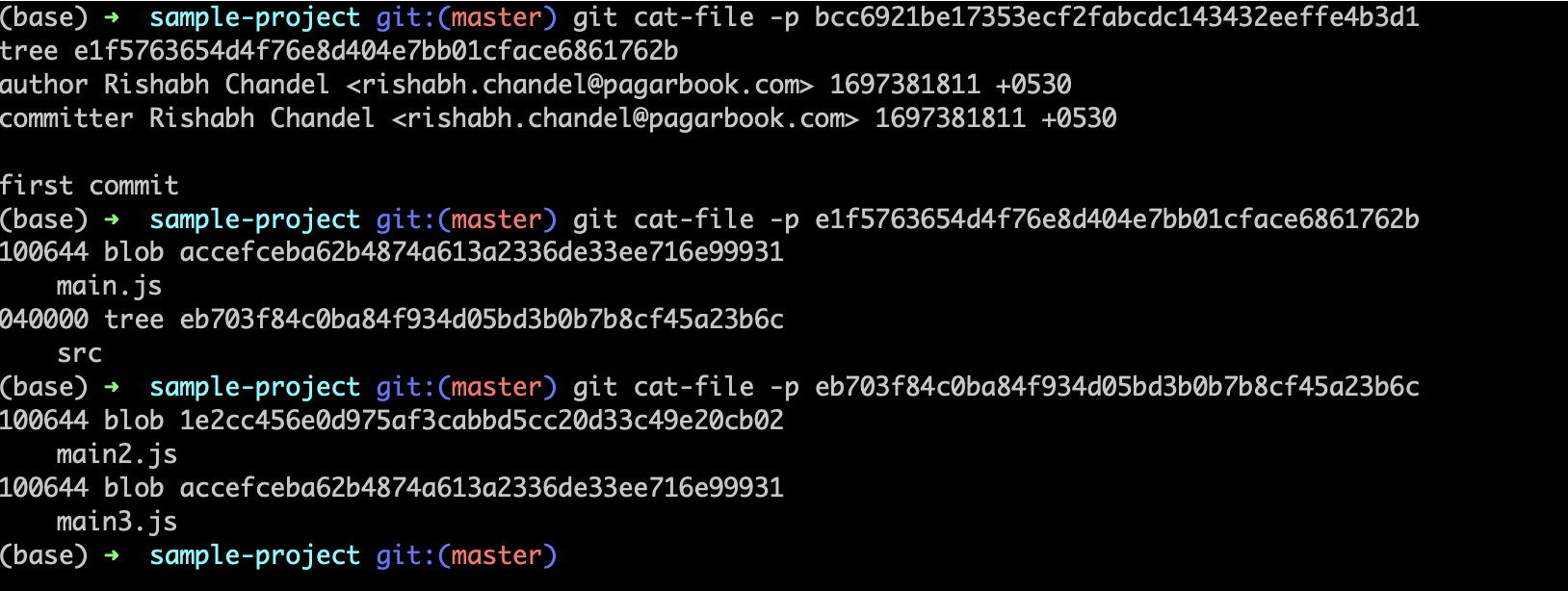
When we print a commit object in Git, it reveals essential commit details, including the author's information, the commit message, and the commit timestamp. Additionally, it provides a hash pointing to a tree object. If we delve into the tree object by printing it, we find the hash for the main.js blob and another tree object representing the src directory. Continuing this process, printing the src tree object uncovers the hashes for the remaining two blobs: main2.js and main3.js.
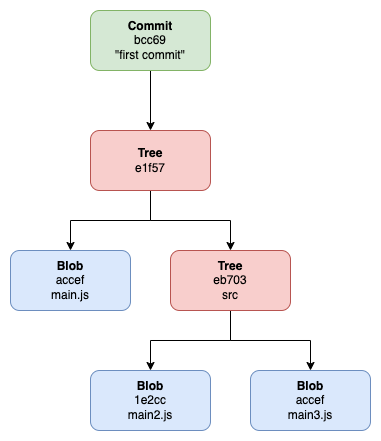
This is the fundamental way Git organizes and stores its data in objects. To simplify the concept, refer to the image below for a visual representation.
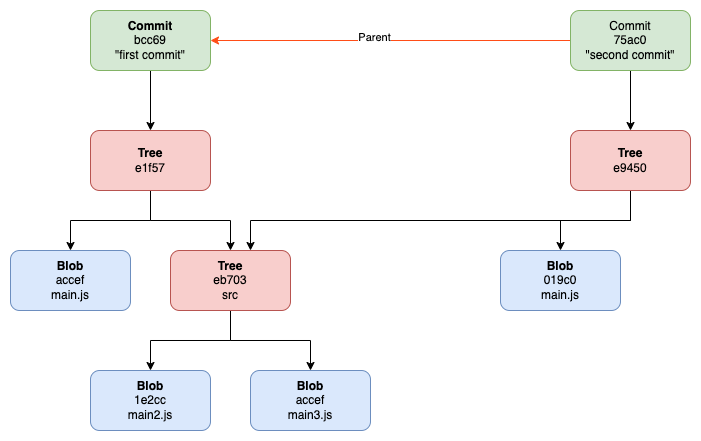
Time for a second commit?
What happens when we change the content of a file, and make a new commit? Before reading on further, pause for a while and think how git would store it.
Let's say we add an ! at the end of the line in main.js, that is console.log("Hello World"); is changed to console.log("Hello World!");.
Well, this change would mean a new blob will be created with a new SHA-1 hash.
Since we have a new hash, the tree no longer points to “accef”. This means the tree’s content is changed and so will its hash.
Almost ready to create a new commit object, and it seems like we are going to store a lot of data - the entire file system, once more! But that is not the case. Actually, most objects, specifically blob objects, haven’t changed since the previous commit.
So this is the trick - as long as an object doesn’t change, we don’t store it again. We only refer to them by their hash values. We can then create our commit object.

Since this commit is not the first commit, it has a parent — commit bcc69.
Summary
In this blog post, we dived into the inner workings of Git, exploring its fundamental components: blobs, trees, and commits.
We learned that a blob holds the contents of a file. A tree is a directory-listing, containing blobs and/or sub-trees. A commit is a snapshot of our working directory, with some meta-data such as the time or the commit message. We refrained from delving into more concepts, such as branches and tags, to keep the post concise.
Thanks for reading!
Subscribe to my newsletter
Read articles from Rishabh Chandel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by