Vectorization and its types
 Sakshi
SakshiTopics to be covered in the article:
a. What is vectorization
b. Importance of vectorization in machine learning
c. Implementation with and without vectorization
d. Vectorization Methods
What is vectorization
Vectorization as the name suggests is the process of converting the input data (text data) into vectors. It helps in the fast execution of the code. This technique has been used in multiple domains and now it’s used in NLP.
Instead of using loops explicitly, we can use highly optimizer libraries in python, java, c++, etc. To implement vectorization in machine learning we use the NumPy library.
Importance of vectorization in Machine Learning
In machine learning, we have supervised and unsupervised algorithms and in supervised we have classification and regression problems. When working on these algorithms we need to deal with the optimization of algorithm to get better results, i.e., the error is minimum.
An example of the optimization algorithm can be gradient descent.
Implementation with and without vectorization
for j in range(0,10):
f= f+w[j]*x[j]
t(0)
f+w[0]*x[0]
The for loop runs without vectorization. The loop iterates from index 0 to index 9. Starting from index 0, then index 1, and so on.
np.dot(w,x)
This function in NumPy is implemented with vectorization so that the system can get all the values of vectors w and x and it also multiples the corresponding values of w and x with each other. Now, the system takes the 10 numbers and adds them together instead of carrying out septate additions one after the other for all ten times.
Vectorization Methods
There are multiple methods of implementing vectorization, some of which are listed below:
1. Bag of words
2. TF-IDF
3. Word2Vec
1. Bag of Words
The “Bag of Words” (BoW) method is a popular technique used in natural language processing and information retrieval to convert textual data into numerical vectors. It represents a document as a “bag” (unordered set) of words, ignoring grammar and word order, while only considering the frequency of each word occurrence.
Let’s take a simple example to illustrate the BoW method. Consider the following two sentences:
Sentence 1: “The cat sat on the mat.”
Sentence 2: “The dog played in the park.”
To create a bag of words representation, we first need to identify all unique words in the corpus, which is the combined set of words from both sentences:
Unique words (9):
[“the”, “cat”, “sat”, “on”, “mat”, “dog”, “played”, “in”, “park”]
Now, we create a vector for each sentence, where each dimension in the vector corresponds to one of the unique words. The value of each dimension represents the frequency of that word in the respective sentence. If a word is not present in a sentence, its frequency will be zero.
For Sentence 1 and Sentence 2, the BoW vector would be:
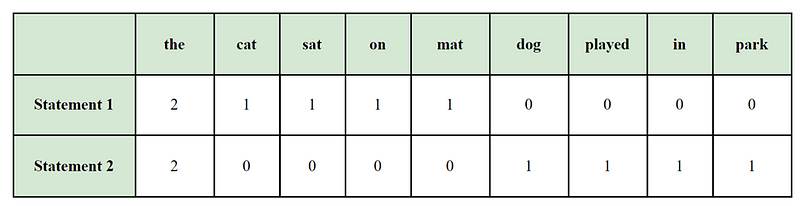
The BoW representation is beneficial in various NLP tasks such as sentiment analysis, text classification, etc. However, it has limitations, like disregarding word order and not capturing the semantic meaning of the text. To overcome some of these limitations, more advanced techniques like TF-IDF and word embeddings are often used.
2. TF-IDF
The TF-IDF (Term Frequency-Inverse Document Frequency) method is a popular technique used in NLP and information retrieval to represent textual data as numerical vectors. It helps to capture the importance of words in a document within a larger collection of documents.
TF-IDF takes into account two main factors:
the term frequency (TF),
inverse document frequency (IDF)
Term Frequency (TF): The term frequency measures how frequently a term occurs in a document. It is calculated by counting the number of times a term appears in a document and dividing it by the total number of terms in that document. The idea behind TF is that more frequent terms are generally more important for understanding the content of a document.

For example: “Cats are cute animals. Cats are great companions.”
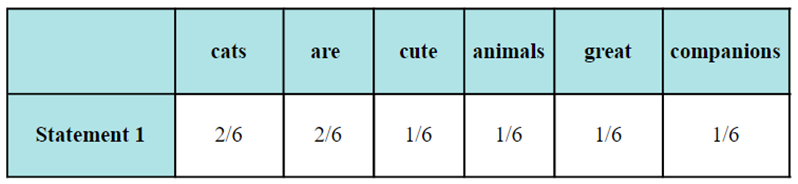
The term “cats” appears twice in this document, and the total number of terms is six. Therefore, the term frequency of “cats” in this document is 2/6 = 0.33.
Inverse Document Frequency (IDF): The inverse document frequency measures the rarity or uniqueness of a term across the entire document collection. It helps to highlight terms that are more distinctive and informative. IDF is calculated by taking the logarithm of the ratio between the total number of documents and the number of documents containing a specific term.

For example, if we have a collection of 1,000 documents and the term “cats” appears in 100 of those documents, the IDF for “cats” would be log(1000/100) = 1.
TF-IDF Calculation: The TF-IDF score is calculated by multiplying the TF and the IDF together. The resulting value represents the importance of a term in a specific document within the entire collection.
For example, if we calculate the TF-IDF score for the term “cats” in our document about cats, we multiply the term frequency (0.33) by the inverse document frequency (1) to get the TF-IDF score of 0.33.
This process is repeated for all the terms in a document, resulting in a numerical vector representation of the document based on the TF-IDF scores of its terms.
3. Word2Vec
Word2Vec is a popular method for vectorization that transforms words into numerical vectors, enabling machines to understand and process textual data. The approach is based on the idea that words with similar contexts often share semantic meanings, and thus, their vector representations should be close in a high-dimensional space. There are two main architectures used in Word2Vec: Continuous Bag of Words (CBOW) and Skip-gram. Let’s delve into each with examples:
CBOW: The CBOW model aims to predict a target word from its context words. It takes a window of surrounding words and tries to predict the middle word.
Here’s an example:
“The quick brown fox jumps over the lazy dog.”
Context: We’ll use a window size of 2, meaning two words to the left and two to the right of the target word.
For the word “fox”:
Context: [“quick”, “brown”, “jumps”, “over”]
Target: “fox”
For the word “over”:
Context: [“jumps”, “the”, “lazy”, “dog”]
Target: “over”
Skip-gram: The skip-gram model, on the other hand, takes a target word and tries to predict its context words. It tries to maximize the likelihood of predicting the context words given the target word. Here’s an example:
Target word: “lazy”
Context: Let’s consider a window size of 2 as well.
Predicted context words: [“the”, “dog”]
Target word: “lazy”
Predicted context words: [“lazy”, “jumps”]
Target word: “dog”
After obtaining the contexts and targets, Word2Vec learns the vector representations for each word using a neural network. The vectors capture semantic relationships between words. Words with similar meanings or appearing in similar contexts will have vectors that are close together in the high-dimensional space.
Once trained, these word vectors can be used for various NLP tasks like similarity comparison, document classification, sentiment analysis, and more. The power of Word2Vec lies in its ability to capture meaningful information from large amounts of unstructured text data, helping machines comprehend and analyze human language effectively.
Thank you for reading the article you can connect with me on Twitter.
Subscribe to my newsletter
Read articles from Sakshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sakshi
Sakshi
I am an associate UI engineer at Impetus Technologies. I usually read and write on ML and DL.