What's Wrong with Temporary Tables in PostgreSQL
 Aliaksei Kirkouski
Aliaksei Kirkouski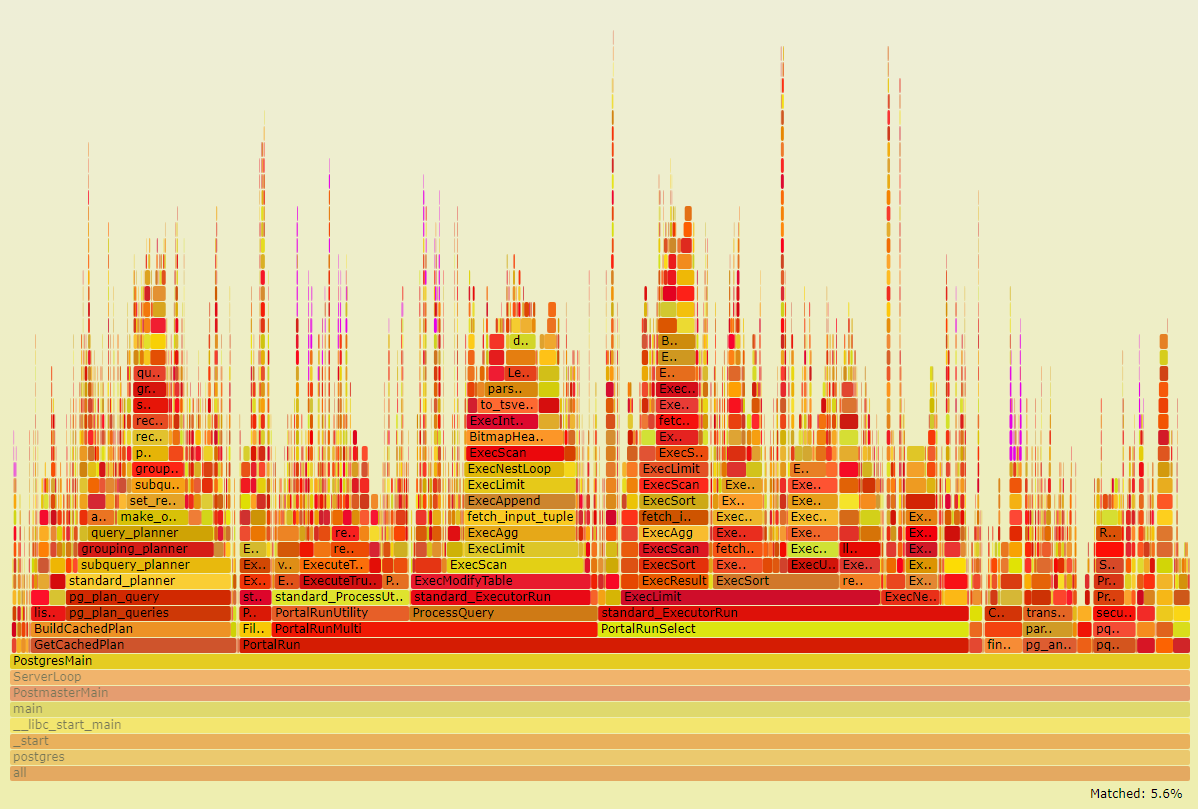
We have been using PostgreSQL as our main database for many years. During this time, it has proved to be a fast and reliable RDBMS. However, there is one problem in PostgreSQL that we have to face quite often. Unfortunately, the implementation of temporary table logic in it has a number of drawbacks that negatively affect system performance.
Temporary tables are most actively used by platforms in which the developer does not work directly with the database, and tables and queries are generated directly by the platform itself. We are developing one of such platforms.
In this article I will describe why you have to use temporary tables, what the problem is, and how to improve performance by customizing the operating system and PostgreSQL.
What is the problem
Temporary tables in PostgreSQL are implemented in much the same way as regular tables. Developers can be understood, because otherwise they would have to make two code branches for regular and temporary tables separately. This would greatly complicate the DBMS logic and add reliability and performance problems. On the other hand, the use cases of temporary tables are very narrow, and many mechanisms used for regular tables are redundant for temporary tables. In particular, they are guaranteed not to be used by multiple connections at the same time, are not subject to locks, do not require write reliability, etc.
As for regular tables, information about temporary tables is located in PostgreSQL system tables. In addition, for each table, one or more files are created on disk (by default, in the same folder as the files for regular tables).
One side effect of this implementation of temporary tables in PostgreSQL is transactional support. If the temporary tables were modified within a transaction, and the transaction is then rolled back, the temporary table will also be restored to its pre-transaction state. In most cases, this behavior is not really needed and also creates some overhead.
The problem is that temporary tables must be frequently purged. Doing it with DELETE ALL is bad because PostgreSQL uses MVCC for temporary tables as well, and deleting records in this model is a relatively slow process. Therefore, we have to use TRUNCATE.
TRUNCATE simply creates a new file on disk and does an UPDATE of the pg_class table. This is easily verified by doing a query like this one and seeing what happens on disk after each one:
CREATE TEMPORARY TABLE t0 (key0 integer);
SELECT relfilenode FROM pg_class WHERE relname = 't0';
TRUNCATE t0;
SELECT relfilenode FROM pg_class WHERE relname = 't0';
One file of the kind t0_9782399 will be created on disk first, and then another with the new relfilenode.
Also, after adding records to a temporary table, you have to ANALYZE it so that PostgreSQL knows the correct statistics of the data in it. ANALYZE, in turn, also modifies the system tables and accesses the disk (in the visibilitymap_count function).
With a large number of TRUNCATE and ANALYZE, two problems arise :
The pg_class table (and other system tables) becomes bloated. If pg_class is 30 MB after VACUUM FULL, it can grow to 1 GB in a couple of hours. Considering that system tables are accessed very often, increasing its size increases the CPU load. Plus the autovacuum of the pg_class table itself is often triggered for this reason.
New files are constantly created and old ones are deleted, which requires access to the file system. And everything would be all right, but in case of a large disk system load with constant buffer rotation, it starts to slow down users who normally perform actions that do not require disk access, although they already have all data in shared buffers. But TRUNCATE of temporary tables "stops" them waiting for disk access (although in fact their size does not exceed temp_buffers, and there is no sense to use the disk).
As a result, working with temporary tables (specifically in the DDL part) uses a significant part of processor time:
And direct access to the file system takes 13.5% of CPU :

Theoretically, all work with temporary files should take place inside the disk cache, and at least do not wait for IO access, and at most do not access the disk at all. However, firstly, disk caches are actively used for the main database as well, and secondly, even in asynchronous mode, from time to time there will still be writing, which creates additional IO operations. For the test we moved all the temporary tables to a separate disk, and there was quite a large write to the disk with almost no reads :


The problem is worsened by the fact that all files that are created for temporary tables are actually in one folder. Their number can reach several hundred thousand at certain times. Unfortunately, not all file systems (e.g. xfs) handle such a large number of files in a single directory well. At the same time, files are not just lying there, but are constantly being created and deleted at a tremendous rate.
Also, processes spend most of their time in LWLockAttemptLock, which is called from LockRelationOID.

In a normal situation, calls to LWLockAttemptLock are quite fast and do not affect performance much. However, this is a potential bottleneck and can lead to a very severe degradation of the whole database server. In particular, we have had this happen due to virtualization issues, because inside LWLockAttemptLock uses kernel functions for process synchronization. Once there was a situation when in PostgreSQL the number of concurrent processes in active status reached 150, among which 100 were locked by LWLock / LockManager on CREATE TEMPORARY TABLE and TRUNCATE queries.
Why to use them
We are often accused that we use temporary tables too much and we could do without them. Of course, we would love to get rid of them, but unfortunately, there are at least three situations when it is hard to think of another way.
Intermediate calculations
There are situations when you need to perform some complex calculations for a certain subset of objects. In this case, it is often most efficient to first write the object keys into a temporary table and then use it to calculate specific values using JOIN. You can, of course, always embed the original object subset filters in queries, but this can lead to repeating the same calculations, which would be less efficient.
Incorrect statistics
PostgreSQL has a relatively simple, yet fast, query planning algorithm. However, it has one major problem. It builds a plan, and then sticks to it, even if it turns out to be wrong. In the worst case, you may get a situation when PostgreSQL expects 1-2 records in the intermediate calculations, but in fact it turns out to be thousands of times more. As a result, Nested Loop execution leads to a huge complexity of the algorithm, which causes the process to hang with high CPU load. Unfortunately, PostgreSQL does not have the ability to specify hints like some other DBMSs. As a workaround, the lsFusion platform, when it sees a hung query by timeout, first cancels the query and then splits it into several queries using temporary tables. Unfortunately, it is very hard to determine where exactly PostgreSQL made a mistake, so the partitioning algorithm is heuristic. The algorithm first writes some intermediate data (for example, nested subqueries) into temporary tables by separate queries, and then these tables are used in the final query after ANALYZE. By doing so, PostgreSQL will already have the correct statistics of the intermediate computations, and the subsequent plan will be more accurate.
Storing changes
While working in the system, when a user makes some changes, they are not written to the database immediately, but only when the Save button is pressed. Only at this moment the transaction starts and the changes are directly published to the database with checking of constraints and recalculation of all dependent fields. However, before saving, all changes are stored in temporary tables. There are several reasons for this.
First, the costs associated with data transfer between the application server and the DBMS are reduced. For example, the user changed some data on the form - they are written to the temporary table, and at the moment of saving, an INSERT or UPDATE is simply executed from it to the main table.
Secondly, it simplifies the logic of calculations. For example, if it is necessary to calculate some parameter taking into account the changes, you can do SELECT SUM(COALESCE(<main table>.field, <temporary table>.field) ... FROM <main table> FULL JOIN <temporary table> ON ... GROUP BY ....
If you keep the changes on the application server (or on the client in general), you will have to transfer all the necessary data there and perform the corresponding calculations there as well. This will result in both greater memory consumption and duplication of the logic of calculating the values on the DBMS and the application server, if the same values have to be calculated in SQL queries. Besides, all the tables on our forms are built in the form of "dynamic lists". That is, only the "visible window" of data is transferred to the client for optimization purposes. Accordingly, for example, all the document lines necessary for calculating the data may simply not exist on the client and the application server.
Of course, this approach has its disadvantages. The main one is the significant complication of clustering and horizontal scaling. Since temporary tables in PostgreSQL are bound to connections, they have to be "assigned" to specific users. Accordingly, switching between servers is possible only with the transfer of temporary tables to a new server. However, in practice, vertical scaling is enough for now. Due to sufficiently optimal queries, our largest clients with several thousand concurrent users have enough resources of one database server with 48 cores (with HT - 96) and 512GB of memory.
Since usually the same temporary tables are required during operation, in order not to constantly create and delete tables, we "cache" them by purging them with a lighter TRUNCATE command. This reduces the load on the database because truncating a temporary table requires fewer resources, but it increases the number of concurrent files on disk (while the table is cached but not in use).
What to do
In Linux, there is one approach that can significantly reduce disk usage of temporary tables. It is to allocate a separate RAM disk for temporary tables. This does not require any changes in the program code, and the above procedure can be performed on a running database without stopping the DBMS or application.
PostgreSQL has the temp_tablespaces option, which defines the default tablespace in which all temporary tables will be created. If the value is empty, temporary tables are created next to the main database tables.
To implement our task, we first need to create a new tablespace specifically for temporary tables. Before that, we need to create the directory where the tablespace files will be stored. For example, let it be /mnt/dbtemp. After creating the directory, you need to set the access rights that PostgreSQL requires:
mkdir /mnt/dbtemp
chmod 700 /mnt/dbtemp
chown postgres:postgres /mnt/dbtemp
Next, go into psql and execute the following command :
CREATE TABLESPACE temp LOCATION '/mnt/dbtemp';
As a result, an empty directory like PG_13_202007201 will be created inside /mnt/dbtemp. As tablespace is used, directories for each database will be created in it, as well as the pgsql_tmp directory. In the last one, files will be created during the execution of SQL queries, if intermediate calculations did not fit into work_mem.
Theoretically, you can load the entire PG_13_202007201 directory into memory. However, then the work_mem parameter loses its meaning, because if it is exceeded, it will again be written to memory, not to disk. For this reason, we usually make a RAM disk exclusively for the required database, not for the whole catalog.
In order to make a catalog for the desired database appear, the easiest thing to do is to go into psql and run :
CREATE TEMPORARY TABLE mytemptable (key0 int8) TABLESPACE temp;
DROP TABLE mytemptable;
After that, a directory of the kind 936082, which is equal to the internal identifier of the database, will appear in the tablespace directory. It is this directory that we will load into memory. To do this, add the following line to /etc/fstab :
tmpfs /mnt/dbtemp/PG_13_202007201/936082 tmpfs rw,nodev,nosuid,noatime,nodiratime,size=1G 0 0
Then mount the RAM disk explicitly using the command :
mount /mnt/dbtemp/PG_13_202007201/936082
It is important to choose the right size of the RAM-disk. In the example above it is 1GB, but the value can be changed at your choice. You should remember that the size of the RAM disk is its limit, and as long as there is no data on it, the memory is not actually used. On the other hand, a large limit can result in either running out of memory or the operating system going into swap.
There is one more thing to keep in mind when working with temporary tables in PostgreSQL. If at the moment of INSERT INTO <temporary table> execution the RAM disk space runs out, the DBMS will throw an error, but the file will remain and the space will not be freed. After that, even TRUNCATE <temporary table> will throw an error, because this command must first create a new file, which will be impossible due to the lack of space. The only thing that can be done in such a situation is DROP TABLE <temporary table>. By the way, the lsFusion platform does all this automatically.
If everything was successful, the only thing left to do is to change the temp_tablespaces option in postgresql.conf :
temp_tablespaces = 'temp'
And to make it apply, in psql run :
SELECT pg_reload_conf();
Right after that all new temp tables will start to be created in memory, and after some time all will move there.
As a result, when analyzing perf, the time of ext4 function calls is reduced to 1.6%, while working with tmpfs is almost invisible :

Subscribe to my newsletter
Read articles from Aliaksei Kirkouski directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by