Llama2 From Scratch with Pytorch Lightning
 After Hours Research
After Hours Research
In our previous blog post, we built the Llama LLM with PyTorch Lightning, with Weights & Biases for experiment tracking and Hydra for configuration management.
Now, we turn our attention to Llama 2, the successor to Llama. Let's look at the differences:
Dataset: Llama2 benefits from a 40% increase in training data.
Context Length: Trained with a 4096 token context length, up from 2048.
Attention Mechanism: An architectural evolution from Multi-head Attention (MHA) to Grouped-Query Attention (GQA).
Apart from the switch to GQA, the architecture remains untouched. Thus, much of our Llama codebase remains applicable, sparing only the attention block.
Understanding the Grouped-Query Attention Block
Let's now see what the new Grouped-Query Attention block (GQALlamaBlock) looks like and break down the code:
class GQALlamaBlock(nn.Module):
def __init__(
self,
embedding_size: int,
context_len: int,
causal_attention: bool,
n_heads: int,
n_groups:int,
swiglu_d_multiplier: float
):
super().__init__()
self.embedding_size = embedding_size
self.causal_attention = causal_attention
self.n_heads = n_heads
self.n_groups = n_groups
assert self.n_heads % self.n_groups == 0, f"Number of heads ({self.n_heads}) must be divisable by the number of groups ({self.n_groups})"
self.group_size = self.n_heads // self.n_groups
assert self.embedding_size % self.n_heads == 0, f"Embedding size ({self.embedding_size}) must be divisable by the number of heads ({self.n_heads})"
self.head_dim = self.embedding_size // self.n_heads
self.R = get_rotary_matrix(context_len=context_len, embedding_dim=self.head_dim)
self.rms = RMSnorm(size=embedding_size)
self.ff_q = nn.Linear(embedding_size, embedding_size, bias=False)
kv_embedding_size = self.head_dim * self.n_groups
self.ff_k = nn.Linear(embedding_size, kv_embedding_size, bias=False)
self.ff_v = nn.Linear(embedding_size, kv_embedding_size, bias=False)
# In Llama paper swiglu_d_multiplier = 2/3 * 4
swiglu_size = int(swiglu_d_multiplier * embedding_size)
self.fc1 = nn.Linear(embedding_size, swiglu_size)
self.activation = SwiGLU(size=swiglu_size)
self.fc2 = nn.Linear(swiglu_size, embedding_size)
def forward(self, x):
input_shape = x.shape
q_resize = (x.shape[0], x.shape[1], self.n_heads, self.head_dim)
kv_resize = (x.shape[0], x.shape[1], self.n_groups, self.head_dim)
x_res = x
x = self.rms(x) # pre-normalization
query = self.ff_q(x).reshape(q_resize)
key = self.ff_k(x).reshape(kv_resize)
value = self.ff_v(x).reshape(kv_resize)
# Apply rotation to query and key, separatly for each head
R_matrix = self.R[:input_shape[1], :, :].to(query.device)
query_rot = torch.einsum('bhld,ldd->bhld', query.permute(0,2,1,3), R_matrix)
key_rot = torch.einsum('bgdl,ldd->bgdl', key.permute(0,2,3,1), R_matrix)
query_rot = query_rot.reshape(input_shape[0], self.group_size, self.n_groups, input_shape[1], self.head_dim)
score = torch.einsum('bsgld, bgdp->bsglp', query_rot, key_rot)
if self.causal_attention:
score += causal_mask(size=score.shape, device=score.device)
score = score / torch.sqrt(torch.tensor(self.head_dim))
attention = torch.softmax(score, dim=-1)
x = torch.einsum('bsgpl,bgld->bsgpd', attention, value.permute(0,2,1,3))
x = x.reshape(input_shape[0], self.group_size*self.n_groups, input_shape[1], self.head_dim)
x = x.permute(0, 2, 1, 3).reshape(input_shape)
x += x_res
x_res = x
x = self.rms(x)
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
return x + x_res
Initialization: The constructor sets up the block, ensuring the number of heads is divisible by the number of groups and the embedding size by the number of heads.
Matrices and Normalization:
get_rotary_matrixgenerates a rotary position embedding matrix, whileRMSnormis used for layer normalization, both carried over from Llama.Group-aware Feedforward (New!):
ff_q,ff_k, andff_vare linear layers for transforming inputs into queries, keys, and values, respectively. These are reshaped according to the number of heads and groups. The output size offf_qis \(d \cdot h\), andff_kandff_vare \(d \cdot g\), where \(d\) is the dimensionality of each head/group, \(h\) is the number of heads, and \(g\) is the number of groups.SwiGLU Activation: A SwiGLU-based feedforward network with a custom size determined by
swiglu_d_multiplieris employed.
The Forward Pass:
During the forward pass, the method reshapes queries, keys, and values, and applies the rotary embeddings separately to each head. This rotation aligns the attention mechanism with the relative position information.
Again, most components are the same as we sow in MHALlamaBlock in Llama. Let's focus on the main differences, all done with the magic of
reshape and torch.einsum!
Calculating Attention Scores:
query_rot = query_rot.reshape( input_shape[0], self.group_size, self.n_groups, input_shape[1], self.head_dim ) score = torch.einsum('bsgld, bgdp->bsglp', query_rot, key_rot)The first line reshapes the rotated query to prepare it for attention score calculation.
input_shape[0]is the batch sizeself.group_sizeis the size of each group within the heads. This is derived by dividing the total number of heads by the number of groups (n_heads / n_groups).self.n_groupsis the number of groups that the heads are divided into.input_shape[1]is the sequence length.self.head_dimis the dimensionality of each head.
This reshaping step is crucial because it aligns the data into a structure that reflects the grouping of attention heads. Each head within a group will contribute to a portion of the attention calculation, and this structure facilitates that process.
The second line calculates the attention scores using torch.einsum . The notation 'bsgld, bgdp->bsglp' describes how the tensors are combined.
bsgldcorresponds to the reshaped rotated queries tensor:bfor batch sizesfor the size of each groupgfor the number of groupslfor the sequence lengthdfor the dimension of each head
bgdpcorresponds to the rotated keys tensor:bfor batch sizegfor the number of groupsdfor the dimension of each headpfor the sequence length, which is the same aslbut is labelled differently to indicate a different role in this operation (here,pis the 'target' position in the sequence that each 'source' positionlis attending to).
When torch.einsum processes this operation, it does the following:
It aligns the rotated queries and keys based on the batch and group dimensions (
bandg).It then computes dot products between each query and key vector across the dimension
dfor each position in the sequence (lattending top).The result is a raw attention score tensor:
bsglp.
Applying Attention to Values:
x = torch.einsum('bsgpl,bgld->bsgpd', attention, value.permute(0,2,1,3))After applying the causal mask, the normalization and the softmax function to the scores, this
torch.einsumoperation applies the calculated attention to the values.
Using the same notation as the attention score calculation, bsgpl represents the attention weights.
bgldrepresents the value vectors, permuted to align with the attention weights:bfor batch sizegfor the number of groupslfor the sequence lengthdfor the dimension of each head
-> bsgpdindicates the resulting tensor's dimensions:bfor batch sizesfor the size of each groupgfor the number of groupspfor the sequence length (the position that received the attention)dfor the dimension of each head
After applying the attention, the tensor must be reshaped back to the original input dimensions to maintain the consistency of the model's layers.
x = x.reshape(
input_shape[0],
self.group_size*self.n_groups,
input_shape[1],
self.head_dim
)
The tensor is reshaped to collapse the sub-group and group dimensions (s * g) back into a single dimension representing all heads. input_shape[0] is the batch size, and input_shape[1] is the sequence length, both derived from the original input tensor. self.head_dim is the dimension of each head.
The next line:
x = x.permute(0, 2, 1, 3).reshape(input_shape)
First, reorder the dimensions of x to match the expected order for the next layers in the model (x.permute(0, 2, 1, 3)). .reshape(input_shape) then reshape the tensor to the original input shape, ensuring that the output of the attention block can be seamlessly integrated into the subsequent layers of the model.
Generation Examples
Right, now that we have our Llama2 model, let's use it for token generation! For that, let's compare some examples of token generation using the different sampling methods described in the Llama post, i.e. greedy, random sampling, top-k sampling, top-p sampling, and their variants including temperature scaling.
We can train our Llama2 model using python baby_llama/run.py model=llama2, this produces the following results:
Full Text, greedy:
[BOS]KING RICHARD III:
O Ratcliff, I have dream'd a fearful dream!
What thinkest thou, will our friends prove all true?[EOS]
Full Text, rnd_sampling:
[BOS]AUTOLYCUS:
TheWhen ravel spacious! therich of mine hath
chairs not appointed me in the blended of my post,
There and garland to the wronging testy of the din
of myHourly.[EOS]
Full Text, rnd_sampling_t:
[BOS]SICINIUS:
Come, what talk you
Of Marcius?[EOS]
Full Text, topk_sampling:
[BOS]CORIOLANUS:
It is a purposed thing, and grows by plot,
To curb the will of the nobility:
Suffer't, and live with such as cannot rule
Nor ever will be ruled.[EOS]
Full Text, topk_sampling_t:
[BOS]KING EDWARD IV:
So, master mayor: these gates must not be shut
But in the night or in the time of war.
What! fear not, man, but yield me up the keys;
ForSpit must be fear'd and thee,
And all those friends that deign to follow me.[EOS]
Full Text, topp_sampling:
[BOS]ROMEO:
Or I shall.[EOS]
Full Text, topp_sampling_t:
[BOS]BUCKINGHAM:
And, in good time, here comes the noble duke.[EOS]
Similar to the previous Llama model, we are only training for 10 epochs, using a small network (8 layers), hidden dimension (1024), context length (256) and training batch size (8). Additionally, here we are using 4 groups within GQA. You can check the wandb run to see all the configurations and generation examples during training for this experiment.
For this small example, we can't see a notable improvement in memory usage. But still, the number of parameters of the model is slightly smaller (233M of Llama vs 224M of Llama2) and we can see in the figure below that Llama2 (dandy-lake-72, purple) is using (slightly) less memory than Llama (hopeful-surf-62, brown).
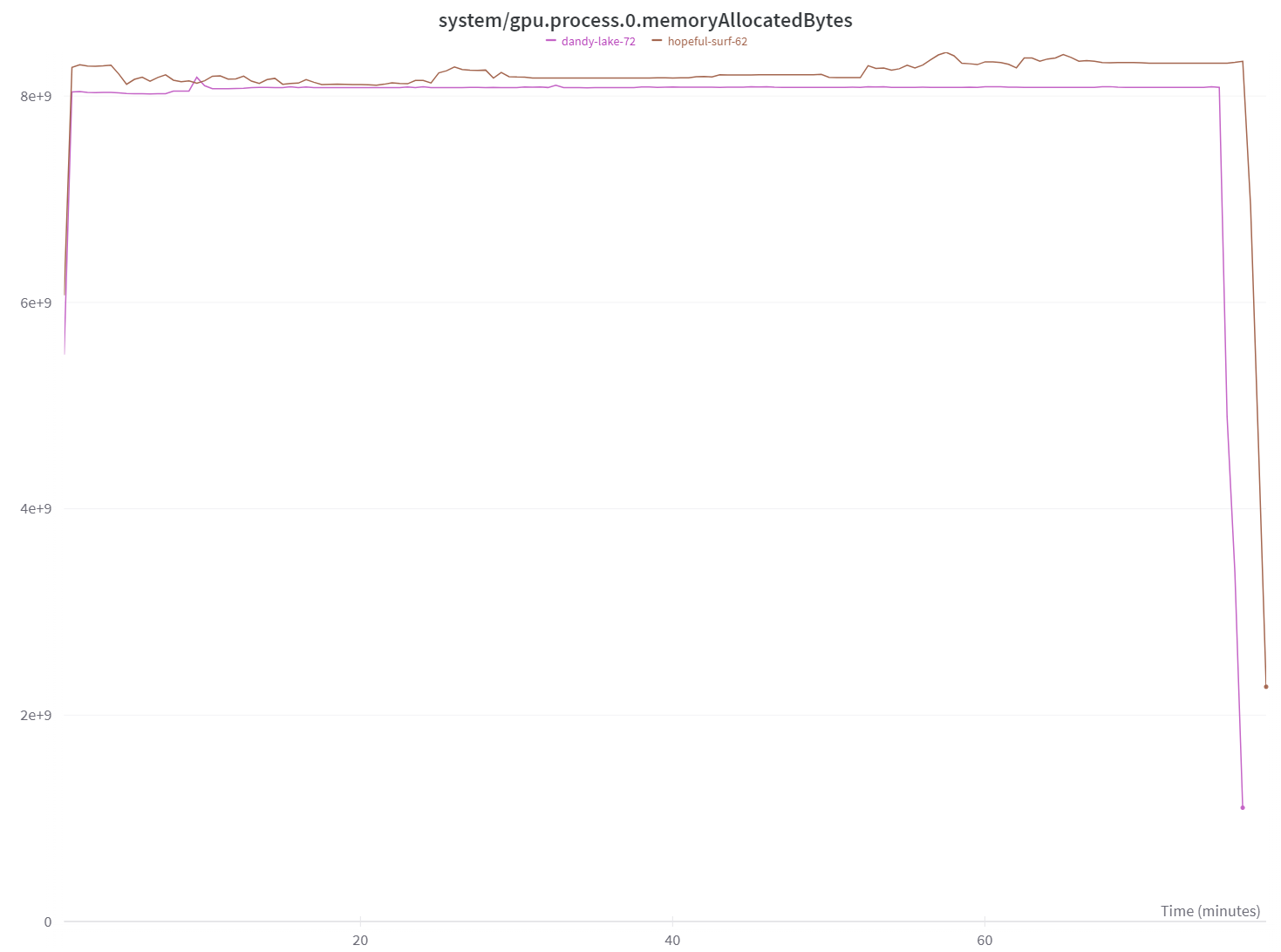
It should be noted that these improvements will scale with the model and that GQA's main advantage is to speed up inference.
Subscribe to my newsletter
Read articles from After Hours Research directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
After Hours Research
After Hours Research
After work-hours ML Research lab, composed of: Brad & Sara