Beginners Guide to Convolutional Neural Network
 Chiezie Ifunanya Eucharia
Chiezie Ifunanya Eucharia
Image Source: Unsplash
In my attempt to understand the convolutional neural network (CNN) alias ConvNet, I have read many articles and watched as many YT videos as possible. Here is my attempt to compile what I’ve learned. As much as possible, I’ll make this article explicit with the hope it helps someone out there to understand CNNs better.
First, let’s briefly explain the concept of neural networks.
I would like you to think of neural networks as the brain. Its architecture and function are similar to how the brain cells work. Comprised of neurons (nodes) that are interconnected, and send signals to one another. They get better at their function with every experience (training) by learning from what they did and didn’t do right. It is the heart of every deep learning framework such as the brain in every human and can also be referred to as the artificial neural network (ANN).
What is CNN?
Convolutional Neural Network (CNN) is a type of neural network that uses perceptrons and is used in areas such as supervised learning, computer vision tasks like video recognition, image classification and many more. CNN is widely used for image analysis because of its ability to learn spatial features from the input data. It performs very well in grid search through a method known as convolutional operation.
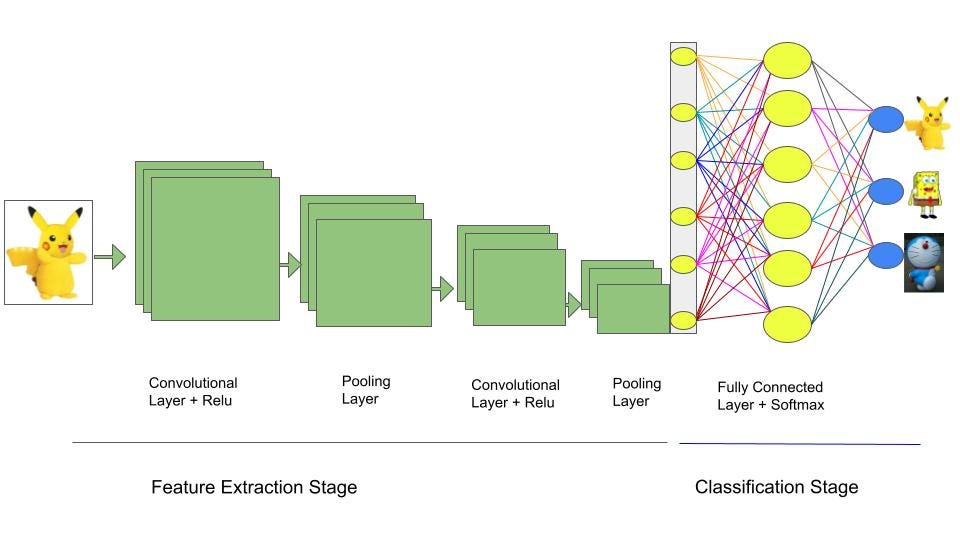
Fig 1: Convolutional Neural Network. Image Credit: Author.
The diagram above shows a convolutional neural network that takes a picture of a cartoon character as an input and classifies it either as a SpongeBob, Doraemon or Pikachu.
The CNN has three important layers — (1) the convolutional layer, (2) the pooling layer and (3) the fully connected layer. We will discuss each of them shortly.
- The Convolutional layer
This is the first layer and the core building block or foundation of a CNN. It contains a filter also known as kernel that has a random and fixed weight.
“Weight is a fancy way of explaining how the network decides the importance of each signal from a node. It is a random number that is initialized and is subsequently adjusted at each iteration until the network gets the possible best result.”
The kernel can be size 3x3, 5x5 or 7x7 and it must be smaller than the input image. The more convolutional layer stacked the better the network learns.
How does the convolutional layer work?
To extract the features, the kernel slides through the input image to produce a feature map a.k.a. activation map. At each slide, the dot product between the image and the initialised weight of the kernel at any position is calculated, and the output is known as the feature map.
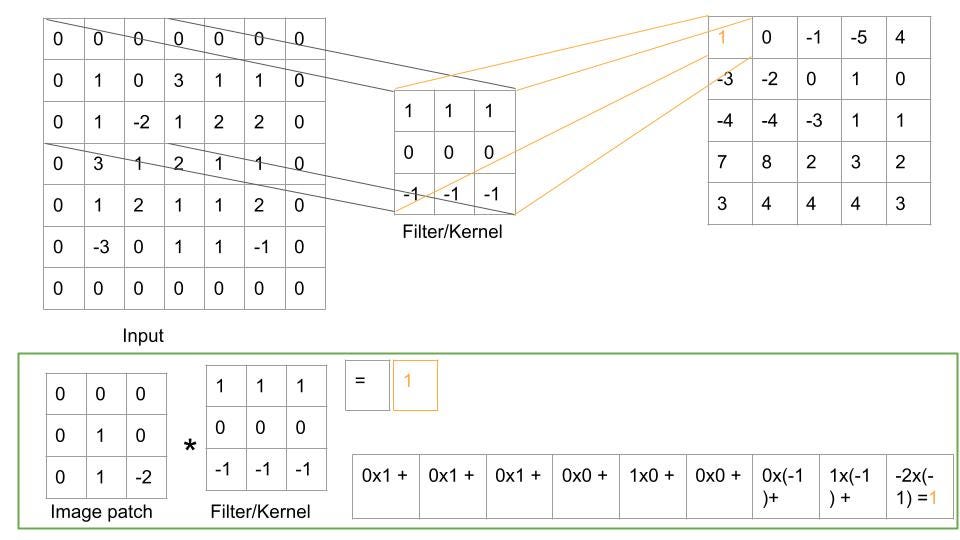
Fig 2: Convolutional Operation. Image Credit: Author.
What parameters do we need in the convolutional layer?
First, we need to set the number of filters. This is a hyperparameter that can be chosen randomly. Filters are used to detect specific features like edge, texture and any other learnable features. The more the filter, the more the depth of the feature to be extracted. However, this can increase the complexity of the network.
Likewise, we have to set the stride. This is how many pixels we want the filter to jump when sliding. Lastly, we need to specify how we wish to pad the input; Simply by adding zeros to the input. Padding is essential in controlling the spatial dimension of the activation map (the output), preserving information at the edges, and ensuring more accurate features are extracted.
We can decide to add zeros to the inputs (zero padding) which makes the output feature map have the same dimension as the input, or we can perform the convolution without padding (no padding), hence, the output will be smaller than the input. And in most cases, information at the edges is underrepresented.
The number of padding to be used is a factor of the input, kernel size and the desired output. It can be calculated as follows:
P = ((F — 1)/2)
P is the padding size, the number of pixels(0’s) to add at each side.
F is the filter size.
Similarly, the output size of the activation function is determined by the input size, filter size, number of slides and the padding size.
Output size = ((W — F + 2P)/S) + 1
W is the input volume/size
F is the filter/kernel size
P is the padding size
S is the number of slides.
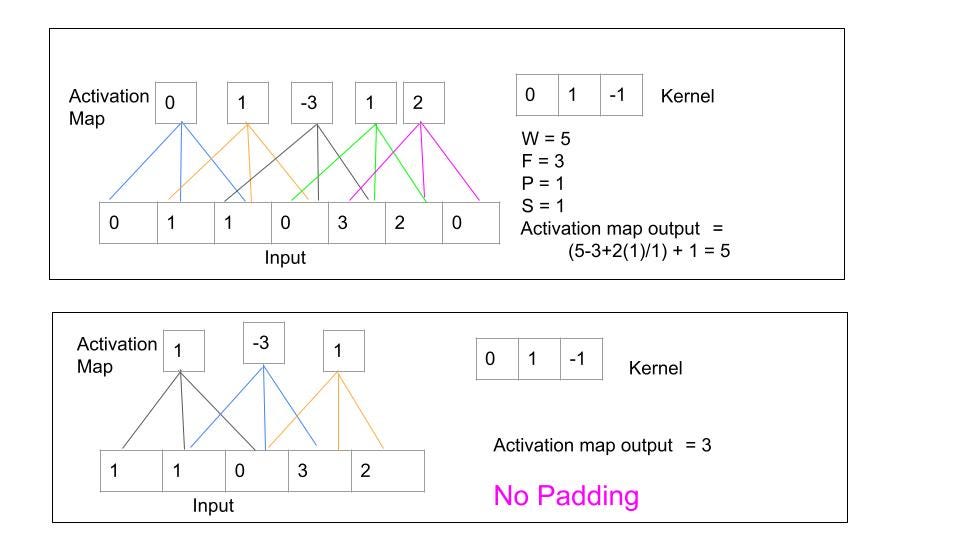
Fig 3: Convolutional Operation with Padding and No-Padding. Image Credit: Author.
To be continued….
Subscribe to my newsletter
Read articles from Chiezie Ifunanya Eucharia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Chiezie Ifunanya Eucharia
Chiezie Ifunanya Eucharia
I am a data scientist on a journey to constantly harness the unwavering power of data.