Build a Q&A App Using Lang-chain, Chroma and Unreal Speech in Python
 Code ninja
Code ninja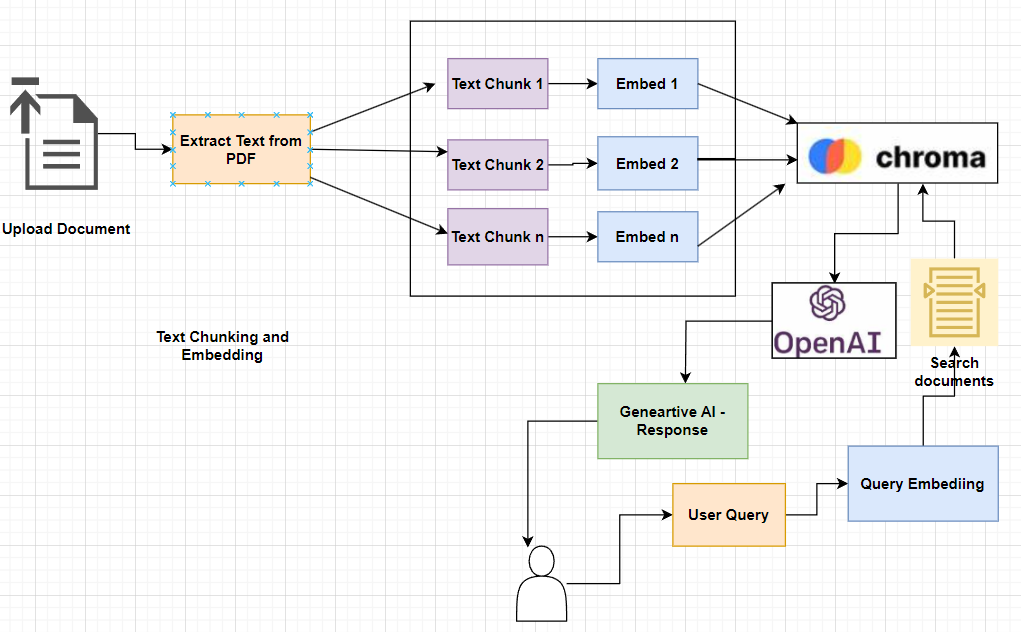
What is Langchain?
LangChain is an open-source library for building language model applications, notably those involving large language models like GPT-3 and GPT-4. It was created by Harrison Chase, a researcher and developer with a focus on artificial intelligence and language models. The library is designed to simplify and streamline the process of integrating large language models into various applications, making it easier for developers to leverage the capabilities of these advanced AI models.
The foundational groundwork for Langchain lies in the development of LLMs like OpenAI's GPT series. These models, built upon deep learning and transformer architectures, demonstrated unprecedented abilities in natural language understanding and generation. Their success paved the way for more practical and innovative applications.
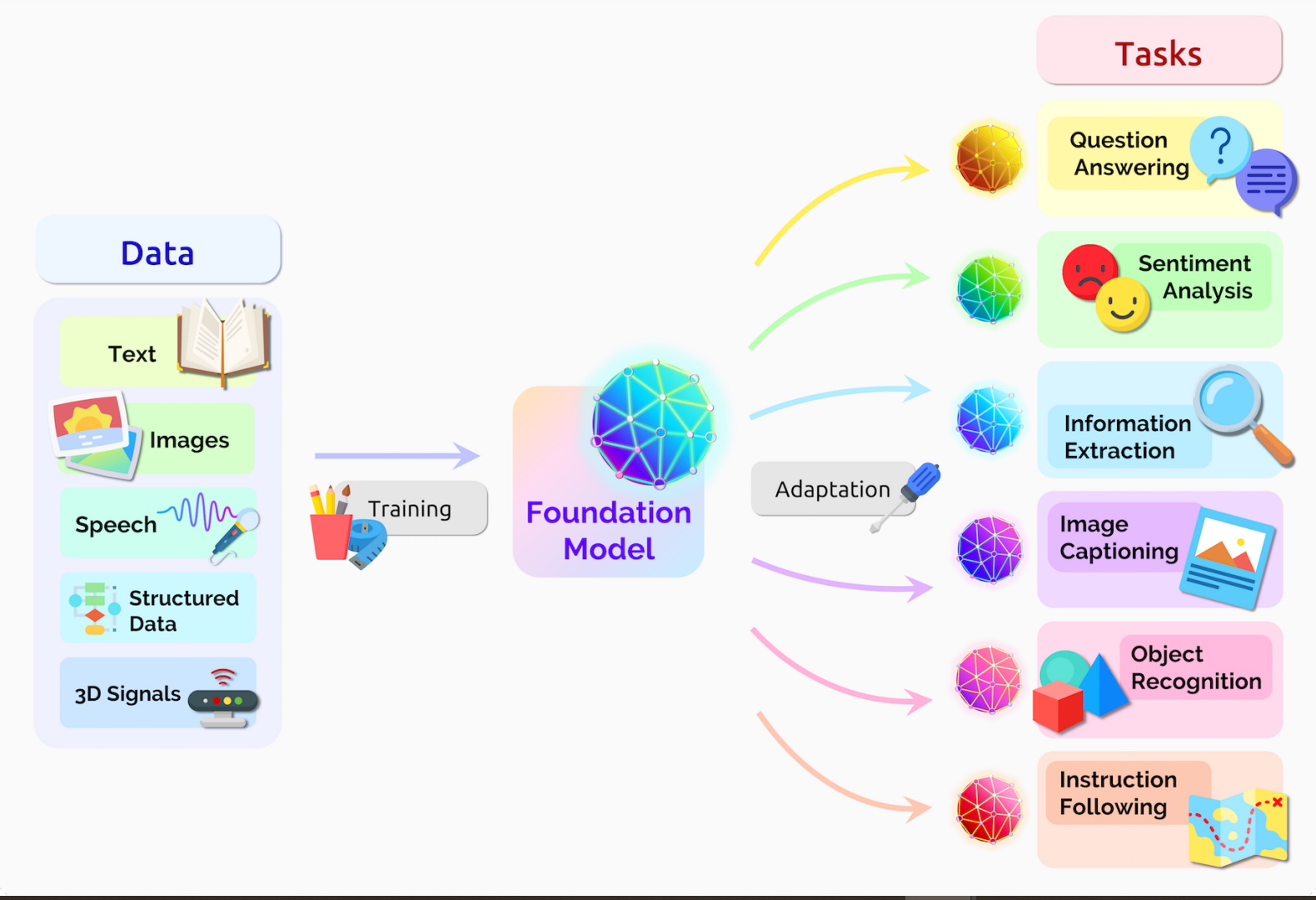
As LLMs like GPT-3 became more widely available, the demand for tools to integrate these models into applications grew. Developers sought ways to harness the power of LLMs for various purposes, from chatbots to content generation. However, integrating these models into existing systems posed challenges, such as handling API requests, managing response processing, and ensuring efficient use of model capabilities
To address these challenges, Langchain was developed. It provided a framework that simplified the integration of LLMs into applications. Langchain offered functionalities like handling tokenization, managing API interactions, and providing utilities for common tasks like question-answering and text completion. This made it easier for developers to focus on building the application logic rather than dealing with the complexities of model integration.
Being open-source, Langchain benefitted from community contributions. Developers and AI researchers contributed to its codebase, enhancing its features and making it more robust. This collaborative effort also meant that Langchain evolved alongside the rapidly advancing field of AI, adapting to new models and techniques as they emerged.
Langchain's impact is evident in how it has enabled a wide range of applications to harness the power of LLMs. From educational tools to business analytics, the library has made it feasible for developers to integrate advanced language understanding and generation capabilities into their software, broadening the practical use cases of AI
Understanding Text Embeddings
Text embedding is a technique used in the field of natural language processing (NLP) to represent words, phrases, or entire documents as vectors of numbers. The main goal of text embedding is to capture the semantic meaning of the text so that similar words or phrases are close to each other in the embedding space, while dissimilar ones are farther apart
Here's an overview of how text embedding works and why it's important:
Semantic Representation: Text embedding models are trained to understand the meaning of words in context. For example, the word "bank" would have different embeddings in "river bank" and "savings bank" due to the different contexts.
Dimensionality Reduction: Embeddings reduce the dimensionality of text data. Instead of representing a word by a one-hot vector with a dimension equal to the size of the vocabulary (which can be extremely large), embeddings represent words in a much smaller, dense vector space (e.g., 50 to 300 dimensions).
Model Training: There are various models for generating embeddings, such as Word2Vec, GloVe, and BERT. These models are trained on large text corpora to generate embeddings that capture syntactic and semantic word relationships.
Transfer Learning: Once a model is trained to create embeddings, it can be used on different NLP tasks, such as text classification, sentiment analysis, or machine translation. This is because the embeddings transfer the learned linguistic patterns to new tasks.
Improved Machine Learning Models: When used as input features for machine learning models, text embeddings help in improving the performance of NLP tasks because they carry significant semantic information.
In summary, text embeddings are a fundamental part of modern NLP, enabling computers to work with human language in a more meaningful and nuanced way. They form the backbone of many contemporary NLP applications and systems.
Project Overview
For us to better understand Langchain, we are going to be building a Q&A app in Python using OpenAI as our LLM and Unreal Speech to add a human-like voice. We are going to be using OpenAIEmbedding to create a text embedding before passing it to our vector store.
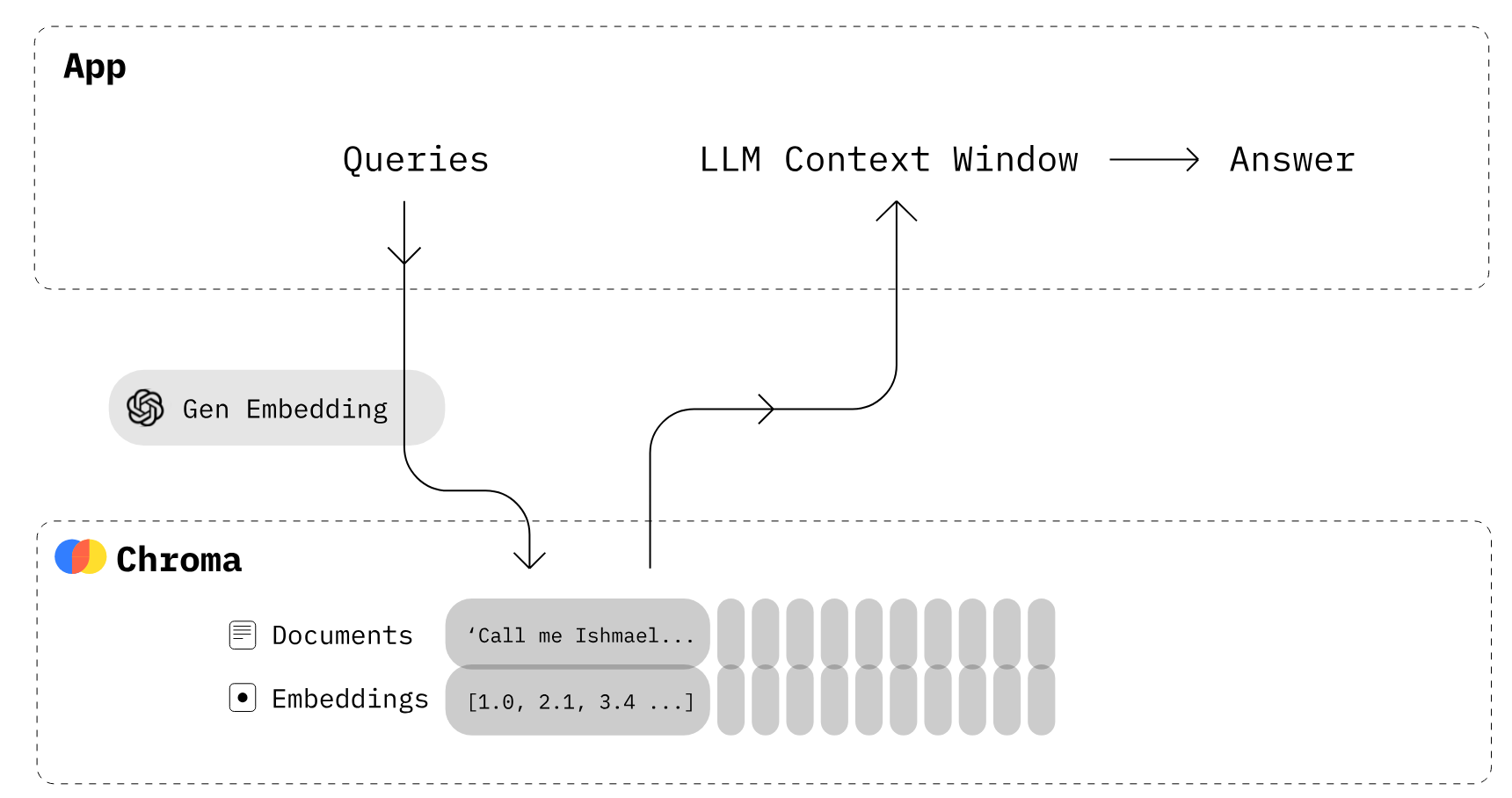
We are going to be using Chroma DB which is an open-source vector store designed primarily for storing and retrieving vector embeddings, which are essentially mathematical representations of data items in a high-dimensional space. This kind of database is particularly useful for applications that involve large language models (LLMs) because it can store the embeddings and associated metadata generated by such models. This makes it easier to utilize these embeddings for various tasks later on.
One of the key functionalities of Chroma DB is its ability to embed documents and queries, as well as to search through its database of embeddings efficiently. Advanced indexing methods like k-d trees or hashing in Chroma DB enable the quick retrieval of similar vectors from the database, which is crucial for developing applications that need to perform similarity searches or other analytics tasks that depend on understanding the relationships between different data points
In practical terms, using Chroma DB is akin to working with a relational database where you create collections (comparable to tables in relational databases) to store vectors. This allows you to manage the data effectively and provides the information to other models or use it as a standalone search tool. The lightweight nature of Chroma DB makes it an attractive option for developers looking to implement scalable and efficient solutions in data-heavy industries
Project Setup
Setting Up the Environment with dotenv
import os
from dotenv import load_dotenv
load_dotenv()
We start by importing the os module and load_dotenv function from dotenv. This setup allows us to read environment variables from a .env file, which is a secure way to manage sensitive data like API keys.
Initializing Embeddings and Speech API
from langchain.embeddings import OpenAIEmbeddings
from unrealspeech import UnrealSpeechAPI, play
embeddings = OpenAIEmbeddings()
speech_api = UnrealSpeechAPI(api_key=os.getenv('UNREAL_SPPEECH_APIKEY'))
Here, we are initializing OpenAI embeddings and the Unreal Speech API. The OpenAIEmbeddings class converts our texts into TextEmbedding, This TextEmbeddig is what would be parsed to our vector database. We are calling the UnrealSpeechAPI is initialized with an API key, enabling text-to-speech capabilities. To get your API held over to Unreal Speech sign in and navigate to the dashboard to get your API Key.
Loading and Splitting Documents
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
loader = DirectoryLoader('documents', glob="**/*.txt")
text_splitter = CharacterTextSplitter(chunk_size=2500, chunk_overlap=0)
documents = loader.load()
texts = text_splitter.split_documents(documents)
We are use DirectoryLoader to load text documents from a directory, and CharacterTextSplitter to split these documents into smaller chunks. This is essential for processing large documents efficiently. The glob parameter means it should get every document with the extension .txt in the documents directory.
Vector Storage and Retrieval with Chroma
from langchain.vectorstores import Chroma
# storing embedded text to chroma db
vecstore = Chroma.from_documents(texts, embeddings)
We are using Chroma an open-source vector database for storing embeddings, is used to store document vectors. It's created from the texts and embeddings, indicating its role in mapping text to numerical vectors for retrieval tasks.
Setting Up the Question-Answering Model
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type='stuff', retriever=vecstore.as_retriever())
We are setting up a retrieval-based QA (question-answering) model using LangChain's RetrievalQA class. It utilizes an OpenAI language model for processing and answering questions, and the previously created vecstore for retrieving relevant information.
The Query Function
def query(q):
try:
print("Query: ", q)
answer = qa.run(q)
audio_data = speech_api.stream(answer, 'Will')
play(audio_data)
print('Answer: ', answer)
except Exception as e:
audio_data = speech_api.stream(answer, 'Oops, An error occurred just occured!')
play(audio_data)
print("An error occurred: ", e)
query("What did Australia’s Minister emphasized on?")
The query function is the heart of this application. It takes a question, retrieves an answer using the QA model, converts this answer into speech using the Unreal Speech API, and then plays it. The example query in the code is about a statement made by Australia's Minister.
In conclusion
In essence, this Python code is a simple integration of text retrieval and processing with advanced text-to-speech capabilities. It's a fantastic example of how Python and its powerful libraries can be used to create advanced applications in natural language processing and AI.
Large language models (LLM) and Unreal Speech can be used to solve a variety of problem sets. Lang-chain makes it easier for you to build LLMs easily by providing several utilities you could use.
I hope this tutorial was impactful more amazing posts will be coming soon.
Further resources
Lang-chain Documentation visit the Langchain documentation to learn more
If you want to use a text-to-speech service, I highly recommend you check out Unreal Speech. It provides you with realistic voices that sound more human.
I recommend this post if you want to explore and see the best text-to-speech service you should be using on your next project: modern text-to-speech you need to tryout!
Subscribe to my newsletter
Read articles from Code ninja directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Code ninja
Code ninja
I am a software engineer, a researcher, a builder and AI enthusiasts