Non-Blocking Spring Boot Applications Using Kotlin Coroutines — Is It Worth It?
 Hossein Sadeghi
Hossein Sadeghi
Co-Authored with: Hadinajafi
In this article, we want to investigate how we can use Kotlin coroutines for creating non-blocking applications. Also, we will do a benchmark to see how much it improves the throughput of our application, Is it really worth it to bother implementing the app in a new way?
What is non-blocking?
Usually, I/O operations like network requests, and reading files from disk, block our execution threads and waits for the result. Non-blocking refers to programs, functions, and pieces of code, written in a way to avoid blocking threads. This way each thread can handle multiple requests concurrently, leading to improved performance and efficient use of resources.
In the Java world, non-blocking approaches like projectreactor, which is used by Spring WebFlux, and utilizes the reactive programming style to avoid blocks have been used for several years to develop non-blocking software. Kotlin introduced coroutines, suspending functions, and many features that can create cleaner non-blocking codes.
What are coroutines?
Coroutines are pieces of code whose execution can be suspended (e.g. when facing a blocking call). This way, it releases the thread running the code, and the application can reuse the thread for processing other requests. The suspended function can continue execution whenever the blocking call is unblocked (gets the result).
By using coroutines, we can write asynchronous codes in the familiar sequential style which is easier to read and understand. Even error handling is the same style with throwing exceptions and we don't need to use different sophisticated structures for handling them.
Use cases of coroutines
In every application, we have certain calls that block our execution. For example, database calls that we have in backend applications or HTTP requests. They block the execution until we receive the result. To tackle this problem we usually create new threads. For backend applications, we spin up a pool of threads and each thread is responsible for processing one request, so we don't care about blocking in the big picture. But threads are not the most efficient solution always. They are not cheap and we have a limited amount of them in the system. In addition, blocking a thread just for waiting for a result doesn't feel so right, does it?
By using Kotlin coroutines, we can improve the performance of the application drastically.
In the next section, we will demonstrate the implementation of the coroutines version of the app, if you are not interested and want to see the comparison sooner, jump to the benchmark!
Sample Application - unRealEstate
Here, we will implement an imaginary RealEstate listing website called unRealEstate. We will implement some simple create and read operations with Spring Boot in three approaches: blocking, non-blocking using reactive streams, and non-blocking using coroutines. At the end, we will benchmark and compare them.
For demonstration purposes, we will go through the steps for creating just a few parts of the coroutine version. As a reference, you can view the GitHub repository for complete implementations of all three methods. Let's go!
First things first, create the project
Let's create a new project. Use Spring Initializr, select "Kotlin" language, "Gradle - Kotlin" build tool, Java 17, add dependencies: ["Spring Web", "Spring Data R2DBC", "MariaDB Driver"], and generate!
Create The First Entity: Property
As in unRealEstate, we want to sell properties, let's create a sample entity called Property which includes a few basic properties:
import org.springframework.data.annotation.Id
import org.springframework.data.relational.core.mapping.Table
@Table(name = "properties")
class Property(
val ownerName: String,
val state: String,
val city: String,
val address: String,
val price: Long,
val description: String,
val agentId: Long,
) {
@Id
var id: Long? = null
}
Repository Layer: Accessing data source
As said earlier, here we use R2DBC to access the database, so you can inject R2dbcEntityTemplate in your constructor.
import kotlinx.coroutines.reactor.awaitSingle
import org.springframework.data.domain.Page
import org.springframework.data.domain.PageImpl
import org.springframework.data.domain.Pageable
import org.springframework.data.r2dbc.core.R2dbcEntityTemplate
import org.springframework.data.relational.core.query.Criteria.where
import org.springframework.data.relational.core.query.Query
import org.springframework.stereotype.Repository
import reactor.core.publisher.Mono
import reactor.kotlin.core.util.function.component1
import reactor.kotlin.core.util.function.component2
@Repository
class AgentRepository(private val entityTemplate: R2dbcEntityTemplate) {
suspend fun save(agent: Agent): Agent {
return entityTemplate.insert(agent).awaitSingle()
}
suspend fun getPage(pageable: Pageable): Page<Agent> {
val itemsMono = entityTemplate.select(Agent::class.java)
.matching(Query.empty().limit(pageable.pageSize).offset(pageable.offset))
.all()
.collectList()
val totalMono = entityTemplate.select(Agent::class.java).count()
val (items, total) = Mono.zip(itemsMono, totalMono).awaitSingle()
return PageImpl(items, pageable, total)
}
suspend fun findById(id: Long): Agent? {
return entityTemplate.selectOne(
Query.query(where("id").`is`(id)),
Agent::class.java
).awaitSingle()
}
}
Here, all the methods are "suspending", but the R2DBC methods return reactive objects like Mono<T> (for a single result) and Flux<T> for multiple results. For queries with a Mono result, we use awaitSingle extension method from kotlinx.coroutines.reactor to convert the result to suspending. For Flux ones, we collect all entries as a List with collectList, the result of this method is again Mono so we can use awaitSingle.
Another point is, that in the getPage method, we used Mono.zip to combine two Mono objects into one, so that we wait for them together, not one after the other. Therefore we have a better performance.
Service
You can see here, that by using suspendable functions, our service layer is familiar and the same with the blocking way, we only need to add suspend keyword to methods. You can see just a sample method here:
suspend fun addProperty(
agentId: Long,
ownerName: String,
state: String,
city: String,
address: String,
price: Long,
description: String,
): PropertyDTO {
val agent = agentRepository.findById(agentId) ?:
throw IllegalArgumentException("Agent not found")
var property = Property(
ownerName = ownerName,
state = state,
city = city,
address = address,
price = price,
description = description,
agent = agent,
)
property = propertyRepository.save(property)
return PropertyDTO.fromProperty(property)
}
Controllers
The same thing with the services goes for controllers:
@PostMapping("/properties")
suspend fun createProperty(input: CreatePropertyInput): PropertyDTO {
return unRealEstateService.addProperty(
agentId = input.agentId,
ownerName = input.ownerName,
state = input.state,
city = input.city,
address = input.address,
price = input.price,
description = input.description,
)
}
…and that's it! Let's see how it performs!
Benchmark
We implemented the same APIs with three approaches to see how they perform in these scenarios:
Creating agents (insert into the database)
Creating properties (fetch agent from the database and insert property to the database)
Get the first page of the list of properties (fetch the page and total count from the database)
1. Create Agent Entities
In this scenario, we examine the performance of the applications when creating agents. It's just a POST request with one CREATE query on the database.
Throughput
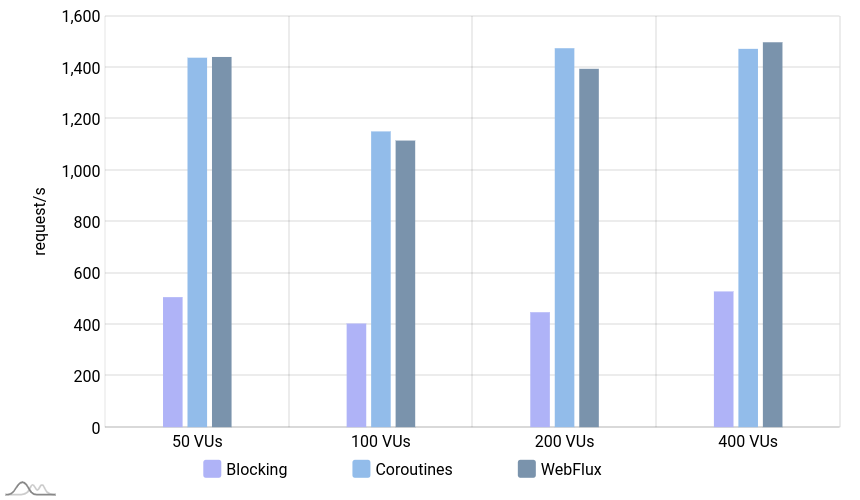
As you can see in the chart, the non-blocking applications performed 2 to 3 times better than the blocking application.
Latency
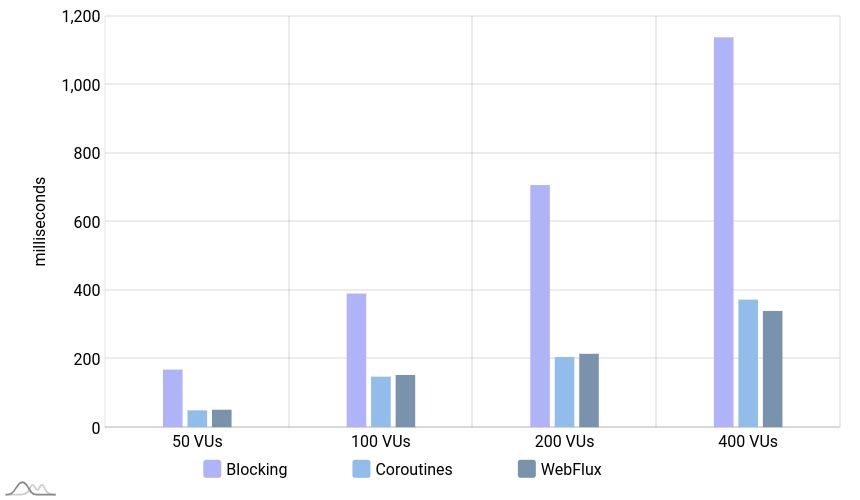
Here, by increasing the number of users, the latency of the system goes up. In non-blocking applications, with 400 virtual users, the duration of 1 request is still less than 400 milliseconds. However, the blocking application needed more than 1 second to serve some requests.
2. Get Agents Entities
This scenario is a GET request to get a page of the agents list. It runs two SELECT queries to the database, one for getting 1st page of size 10, and another one for the total agents count.
Throughput
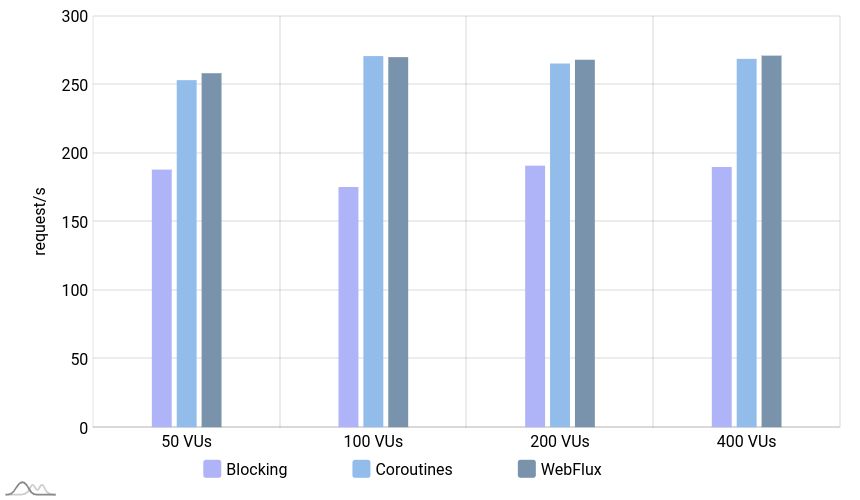
In this scenario, the blocking application performed much better than before and got very close to non-blocking applications. But still, the non-blocking applications performed around 1.5 times better in all conditions.
Latency
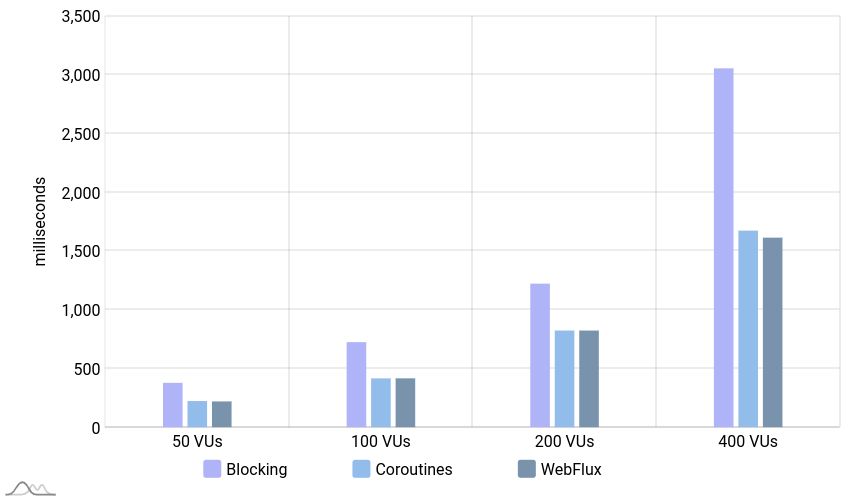
Request duration 95th percentile. Lower is better.
The latency of these 3 applications is close in this case, but once the number of users passes the number of available threads (200), the latency of the blocking application increases drastically.
3. Create Properties Entity
In this scenario, we create a new entity which is called Property which has a relationship to an Agent. It’s a POST request that gets the property info and the agent id. First fetches the agent, and then creates the property. So it’s a combination of SELECT and INSERT queries.
Throughput
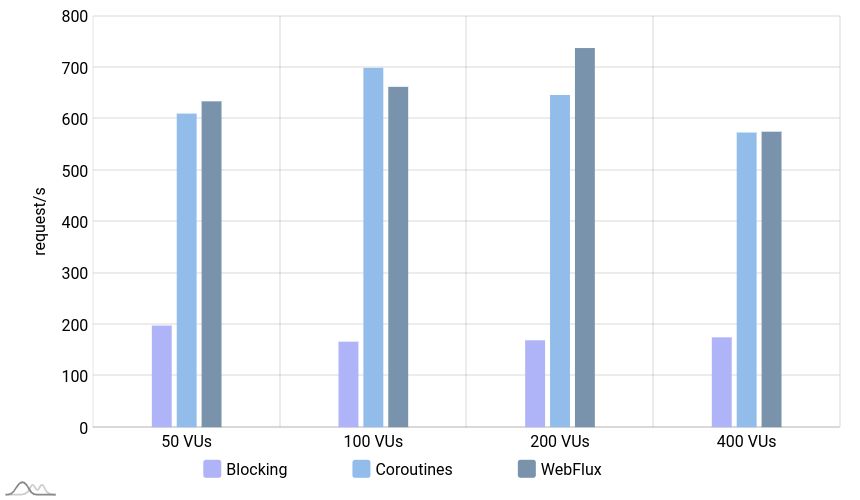
Here, we have a mixture of INSERT and SELECT queries performed on the database, and the non-blocking applications performed 3 to 4 times better than the blocking application.
Latency
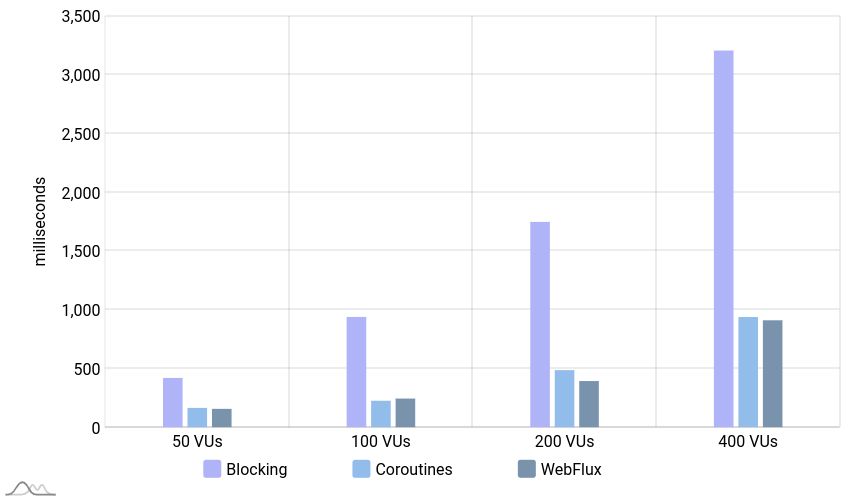
The latency of the blocking application is also high and very different from non-blocking applications in this scenario.
Conclusion
As we saw in the benchmarks, non-blocking solutions can improve the performance of our applications remarkably and we can have lower latency and higher throughput using the same system resources.
Also, by utilizing suspending functions, the way we write the code is old, familiar, and easy to reason about sequential code, and there’s no huge difference between wiring blocking code and non-blocking code anymore.
So why not use it?
Resources
- GitHub Repository (projects, database, and benchmarking codes)
Subscribe to my newsletter
Read articles from Hossein Sadeghi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by