Exquisite Exposition of Word Embeddings
 Atrij Paul
Atrij Paul
What is Word Embedding ?
In Natural Language Processing , word embedding is a term used for the representation of words for text analysis , typically in the form of real valued vectors that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning . Thus capturing the semantic meaning of the words in the phrase or the sentence.
In the any NLP pipeline word embedding is the feature engineering layer, that enables better representation and understanding of textual information for the models to train on. We need these because our machine learning and deep learning models do not understand text , they understand numbers.
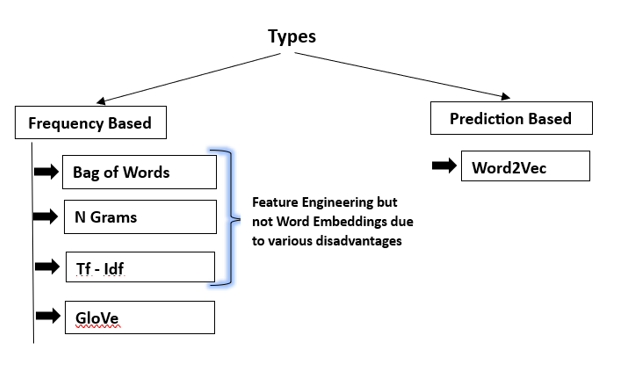
Word Embeddings have two types :-
Frequency Based
Prediction Based
Few Meanings
Corpus : The complete dataset of texts.
Vocabulary : The number of unique words present in the corpus
Document : Each individual set of words in the dataset (can be a sentence or a group of sentences)
Frequency Based Techniques
Bag of Words
Bag of words is an important NLP technique used mainly for Text Classification. It cannot capture the semantic meaning of the sentences and also disregards the ordering of the words which is an important aspect when using Deep Learning models like that of RNNs and LSTMs . Because of these reasons this is not a Word Embedding technique.
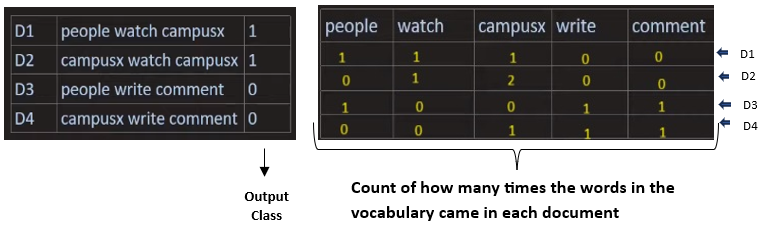
Main Intuition – The document of the same classes will have same words in similar frequencies.
Advantages – Easy to understand
Disadvantages – Sparsity (many zeros leading to overfitting) , Out of Vocabulary(If test set contains any word outside training vocabulary then it is ignored) , Order of words not maintained( thus no Sequence to Sequence operation can be performed) ,Almost no capturing of Semantic information.
NGrams
This is another NLP technique which is mainly used in tasks of Language Modelling. In this technique we take contiguous sequence of N words from the document to form the vocabulary. Then the count of each sequence in a particular document is used as the real vector for that document. Bag of Words is just a UniGram and with larger sentences we can design Bigrams , Trigrams , Quadgrams and many more……This is also not a Word Embedding technique due to huge dimensionality.
Eg : Bigram(using the dataset used in Bag of Words)

Advantages – Captures Semantic Information ( with large variations in vectors over small changes , leads to large angular difference in vector space) , Easy Implementation
Disadvantages : Dimensions increases with increasing number of N (leading to slow processing) , Out of Vocabulary(cannot tackle new words in test data).
Tf-Idf (Term Frequency-Inverse Document Frequency)
Tf-Idf which stands for Term Frequency-Inverse Document Frequency is a NLP technique which is generally used for Information Retrieval systems like that in search engines. The product of Tf and Idf is calculated for each document’s vocabulary. This cannot capture the semantic meaning thus it is not a Word Embedding.
Term Frequency - This measures the frequency of a term (word) within a document. It signifies how often a term occurs in a document relative to the total number of words in that document. Essentially, it reflects how important a term is to a document.

Inverse Document Frequency - This evaluates the significance of a term across the entire corpus. It quantifies how rare or common a term is across multiple documents. Terms that appear frequently across many documents receive a lower IDF score, while terms that are more unique or specific to certain documents receive a higher IDF score.

Why do we take logarithm ?
Suppose if a word is very rare then without logarithm it’s IDF will have a huge value and TF value ranges from 0 to 1 . Thus when such high IDF gets multiplied by TF , the value of TF gets overshadowed .
Advantages : Helps in Information Retrieval.
Disadvantages : Sparsity(leads to overfitting) , Out of Vocabulary , Huge Dimensions , Cannot capture the semantic meaning.
Prediction Based Technique
Word2Vec
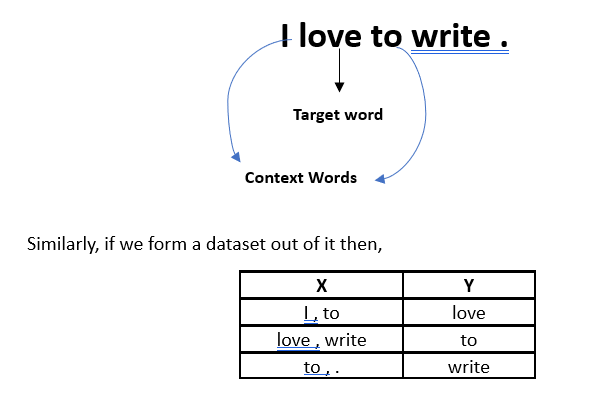
Word2Vec is a popular unsupervised deep learning technique where we find Word Embedding by making the model learn over a continuous vector space. Word2Vec most importantly captures the local context to generate word embeddings. It uses neural networks like that of Skip Gram and CBOW(Continuous Bag of Words) to find the embeddings , which are the weights of a specific layer in the neural network . These neural networks are designed to predict the target words from the context word and as a by product the word embeddings are found .
Skip-gram: Predicts context words given a center word. It aims to learn word representations that are good at predicting the context words surrounding a target word. Used mainly when the corpora is large.
Continuous Bag of Words (CBOW): Predicts a target word based on its context words within a window. It tries to predict a target word using the surrounding context words. Used mainly when the corpora is small.
CBOW and Skip-Gram Neural Neural Networks,
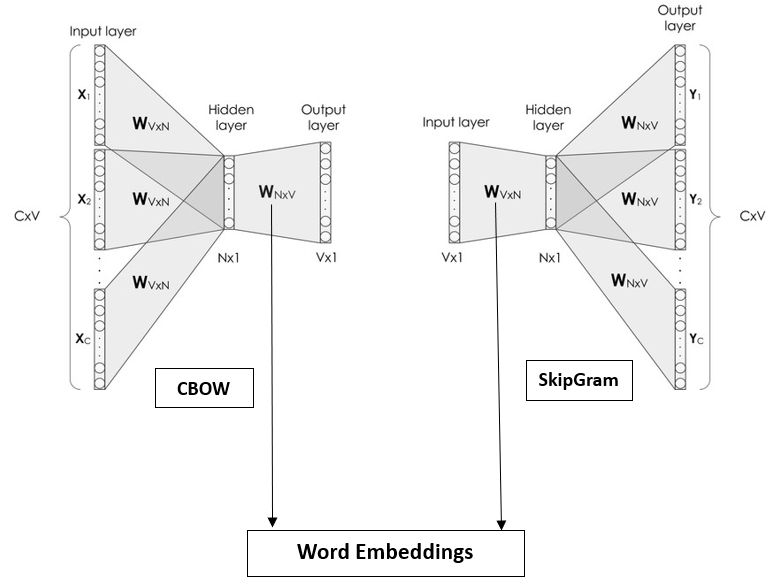
Here ,
X1, X2, X3 , Y1, Y2, Y3 are the One Hot Encoded vectors of the context words(here there are 3 context words thus three input and outputs)
In CBOW – Target word is output
In SkipGram – Target word is input and context words are output.
In both of them the dimensions of the hidden layer forms the dimension of the Word Embeddings.
In the output layer Softmax activation function is used .
Word2Vec is a word embedding technique because the embeddings formed are Dense vectors(most of the weight values of neural network are non zero) and it can effectively capture the semantic meaning in the text .
Word2Vec can be used in sentiment analysis , Named Entity Recognition , machine translations and many more tasks.
Frequency Based Technique
GloVe (Global Vectors)
It is the best of both worlds. GloVe is an unsupervised learning algorithm designed to create high quality word embeddings generated based on the statistical information of the co-occurrence matrix. The algorithm aims to learn word embeddings by minimizing the difference between the dot product of word vectors and the logarithm of their co-occurrence probabilities. It uses least square optimisation as the cost function. It also focuses on the global aspect instead of capturing the local aspect in the data. With the help of the co-occurrence pattern it can capture the semantic relationship.
It is mainly used when there is a very large corpora of data. Technically it can be used as the word embedding for any NLP task for a good result .
What is co-occurrence matrix?
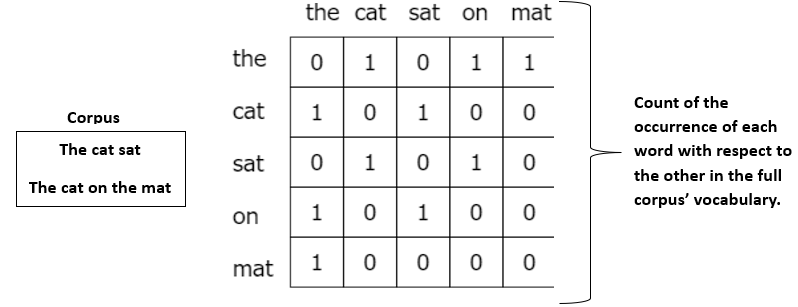
Intuition :-
Xij = Number of times the word j appears in the context of the ith word.
P(j|i) = Xij / Xi = Probability of jth in the context of the ith word.
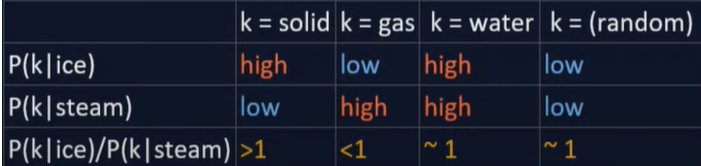
Here ,
K = context word.
Why we take ratio?
The probabilities value can be either very huge or very less thus becomes of no use to us and also do not show any relation as such between words. So, we take their ratio which describes the relation between words by showing their value greater, lesser or equal to 1.
Appropriate function
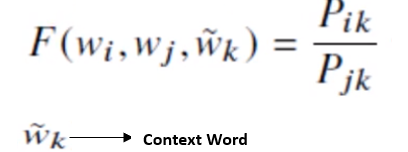
But using 3 vectors in a function will be complicated.
So,

Thus, now it is reduced to a function of 2 vectors
But the next problem is that RHS is scalar, how to relate LHS and RHS.
We do,
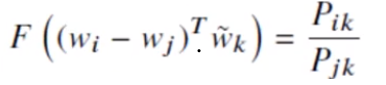
Here we take the Dot product to take everything in sync. Dot product gives the cosine of the vectors and thus their relation and the result of dot product is a scalar.
Transpose is done for dimension matching.
Applying law of Homomorphism we get,
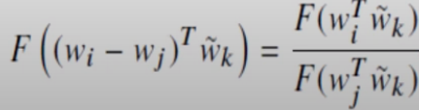
Now we compare the numerators,

After research this function was found to be an Exponential function.
After applying Exponential function we get,
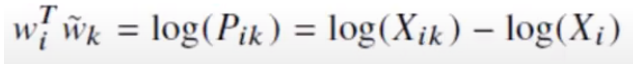
Xi being constant thus log of that will also be constant. So, we convert that to biases
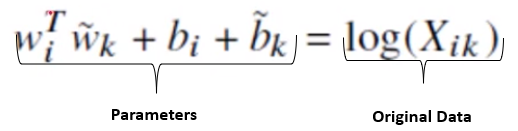
Cost Function
Previously in Word2Vec we saw that it was using Softmax Activation function but Softmax Activation is a very expensive operation to perform.
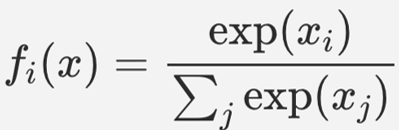
So , here in GloVe we use Linear Regression’s MSE(Mean Squared Error) as the cost function and it turns out to be :-
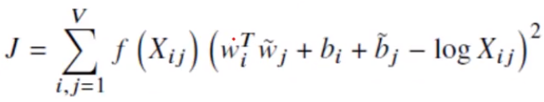
Why f(Xij) and what is it’s definition ?

Thus it gives rise to a graph like,
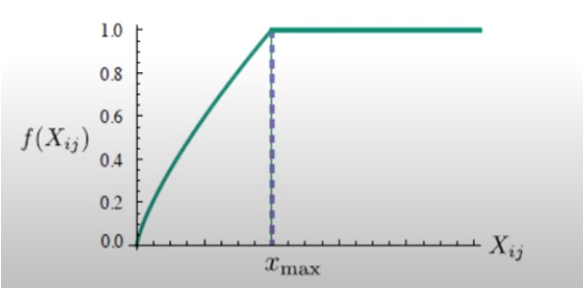
Why use GloVe?
It gives rise to dense word embedding vectors thus less chances of overfitting from sparsity.
The use of Co-occurrence matrix gives the model to have a global view and tasks which demands such global view must have GloVe in them.
It is very fast as one of the most optimized cost function is used , thus making the computation fast.
It can properly capture the semantic information in the text by having an indepth usage of vector space.
It even keeps the frequency based aspect of the words in the text.
As it is deep learning based approach thus it develops features against which it shows the word vectors and we do not have to think about selecting the feature, the number of feature depends on the number of neurons in the hidden layer.
Conclusion
These are some of the major and popular Word Embedding and feature engineering techniques in the field of NLP. There are also some other more sophisticated Word Embedding techniques like the most revered Word Embedding technique known as BERT(Bidirectional Encoder Representations from Transformers) . It is not like the traditional word embedding like GloVe, Word2Vec but it produces contextual word embeddings. Well BERT is a huge arena and it needs another complete blog just dedicated to it.
Subscribe to my newsletter
Read articles from Atrij Paul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Atrij Paul
Atrij Paul
I am an Artificial Intelligence and Machine Learning enthusiast who loves to share his knowledge with people. My speciality lies mainly in Natural Language Processing and Image Processing. I love to learn in public and is always open to learn new things . I am very passionate and confident about the potential of Artificial Intelligence and is always experimenting with new techniques . I am eager to apply AI in various other technologies like those of AR, VR and in various other platforms wherever possible. #learn in public #share knowledge #gain knowledge always and from everything