Node.js: Basics of Stream
 Giver Kdk
Giver KdkTable of contents

Problem Statement
Imagine we need to transfer a large file from a user's computer to a server. We can surely transfer the file directly at a time but that demands a high network bandwidth. It's not suitable for normal network connections. What should we do then?

Let's welcome Stream!
Assume a stream is flowing water in a pipe and the water is the data. So, the stream is a flow of continuous data. We can read/write big data by dividing it into smaller chunks which helps to increase the app's performance.
A chunk of source data is stored in a buffer memory and passed to its destination. Likewise, all other chunks are passed similarly until the entire data gets transferred.
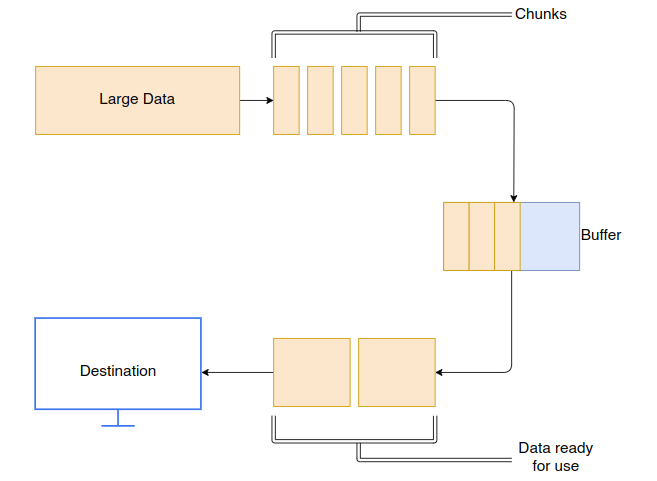
At first, the data is divided into small chunks(size can vary according to data) and stored in the buffer one by one.
When the buffer reaches a specified threshold(no need to be full), it sends the collected data for processing/use.
The buffer is now empty and ready to store other chunks of data.
The flow of data parts during this process is what we refer to as the Stream.
Types of Stream
There are 4 types of streams:
Readable Stream
It's a data flow that can be read. A stream created from a file for reading is a readable stream because it's a flow of data that can only be read. The HTTP request can be treated as a readable stream.
Writable Stream
It's a data flow that can be written. A stream created from a file for writing is a writable stream because it's a flow of data that can only be written. The HTTP response can be treated as a writable stream.
Duplex Stream
It's a data flow where we can both read and write.
Transform Stream
It's a stream that can be modified when reading/writing.

Stream Examples
Let's read a big file using the readable stream. The logic is that we read small chunks of the file and write them into the browser while we are reading those chunks. We will use the 'createReadStream()' method from the 'fs' module whose syntax is:
creatReadStream(path, {flag, encoding, start, end, highWaterMark});
const fs = require("fs");
// Creates a stream object for specified file
const myStream = fs.createReadStream("./big-file.txt");
// 'data' event is fired whenever data chunk is available
myStream.on("data", (result) => {
console.log(result);
});
Here, the 'myStream' is an EventEmitter in itself. So, we can listen to events using it.
The 'data' event is fired whenever a chunk of data is ready to be processed.
So, all the data from the file is printed chunk by chunk every time the data event fires.
The output of this code looks like this according to the file content:
<Buffer 54 68 69 73 20 69 73 20 6c 69 6e 65 20 31 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 32 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 33 0a 54 68 69 73 20 ... 65486 more bytes>
<Buffer 20 6c 69 6e 65 20 33 37 30 33 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 33 37 30 34 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 33 37 30 35 0a 54 68 69 ... 65486 more bytes>
<Buffer 69 73 20 6c 69 6e 65 20 37 33 34 34 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 37 33 34 35 0a 54 68 69 73 20 69 73 20 6c 69 6e 65 20 37 33 34 36 0a 54 ... 47772 more bytes>
These 3 buffer values are chunked file data. The default chunk size is 64KB which can also be changed manually. We are getting the buffer values instead of text because we didn't set the encoding type. Let's set it:
const myStream = fs.createReadStream("./big-file.txt",
{
encoding: "utf8",
highWaterMark: 10000
});
Here, the 'highWaterMark' property is used to set the chunk size in bytes.
Or, we can simplify the syntax as follows to get the text output:
const myStream = fs.createReadStream("./big-file.txt", "utf8", 10000);
Now, let's see an example of reading a big file using a readable stream and writing that data using a writable stream.
const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
const myStream = fs.createReadStream("./big-file.txt", "utf8", 10000);
// Readable stream is connected to writtable stream
myStream.on("open", (result) => {
// Stream is written using 'pipe' as a response
myStream.pipe(res);
});
myStream.on("error", (err) => {
res.end(err);
});
});
server.listen(5000);
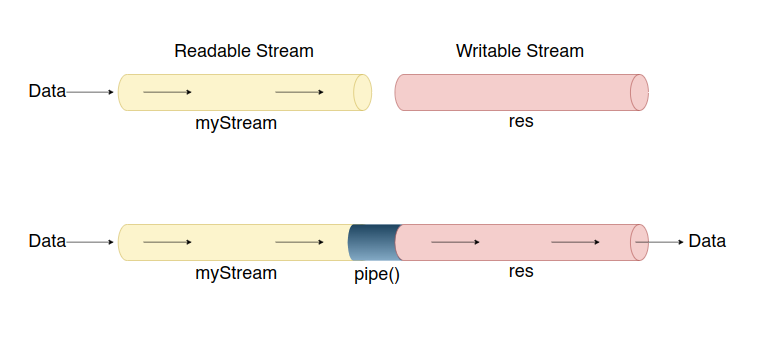
In the above HTTP server setup, when the server is created, we create a Readable Stream.
Then we use the
myStream.pipe(res)to display the file data in the browser. The myStream(Readable Stream) is a pipe with flowing water and the HTTP response res(Writable Stream) is another type of pipe with no water. Now, the 'pipe()' method is like a pipe connector that connects these water pipes.So basically, the 'pipe()' method connects a Readable and Writable Stream. Then, the data from the readable stream goes to the writable stream.
Finally, we use the 'error' event for error handling.
myStream.pipe(res) runs multiple times. This causes the previous data chunk to be overwritten by the current data chunk in the res stream which results in incomplete data being displayed in the browser.
That's all about the basics of the Stream in NodeJS. You made it to the end!
Subscribe to my newsletter
Read articles from Giver Kdk directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Giver Kdk
Giver Kdk
I am a guy who loves building logic.