How to use LLMs for real-time alerting
 Bobur Umurzokov
Bobur Umurzokov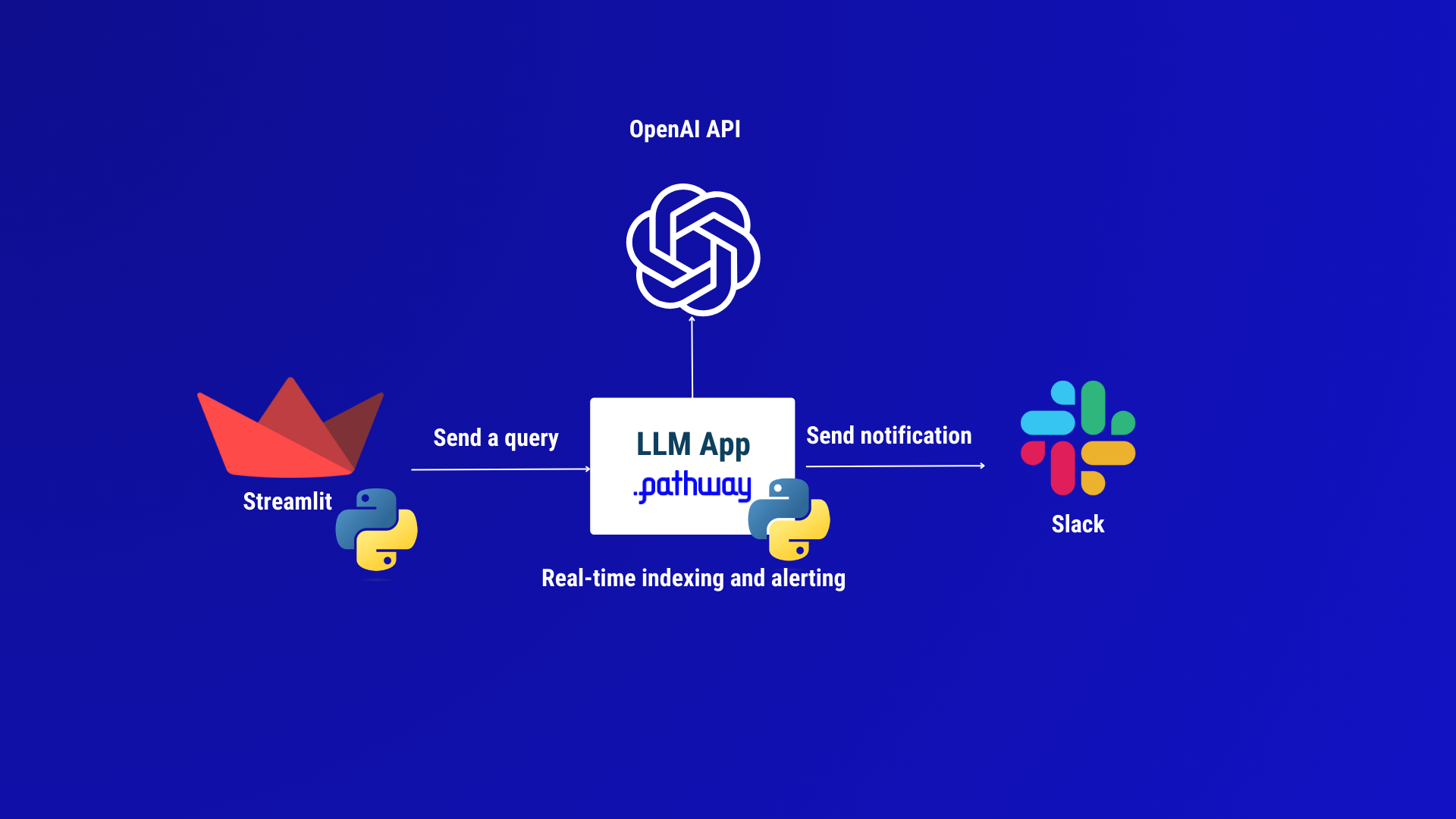
Real-time alerting with Large Language Models (LLMs) like GPT-4 can be useful in many areas such as progress tracking for projects (e.g. notify me when coworkers change requirements), regulations monitoring, or customer support (notify when a resolution is present). In a corporate setting, teams often collaborate on documents using Google Docs. These documents can range from project plans and reports to policy documents and proposals.
This guide shows you how to build a Large Language Model (LLM) application that provides real-time Slack alerts about changes to Google documents that you or your team care about.
The program that we will create answers questions based on a set of documents. However, after an initial response is provided, the program keeps on monitoring the document sources. It efficiently determines which questions may be affected by a source document change, and alerts the user when a revision - or a new document - significantly changes a previously given answer.
The basic technique of feeding chunks of information from external documents into an LLM and asking it to provide answers based on this information is called RAG - Retrieval Augmented Generations. So, what we are doing here is real-time RAG with alerting 🔔.
Worried that deadlines for a project change, and you are not in the loop?
You set the alert once and don’t need to worry about data synchronization ever again!
The architecture of our alerting application
Our alerting app will have a Streamlit UI used to define new alerts. It will synchronize documents from a Google Drive data source, and send alerts to Slack. For document processing and analysis, we rely on a free Python library called Pathway LLM-App, which then allows us to run our alerting app in a Docker container. This is a standalone application, except that it needs to call into a Large Language Model (LLM) to understand whether your document changes are relevant to the alert. For the sake of simplicity of launching, we do not host our own open-source LLM but rely on OpenAI API integration instead.
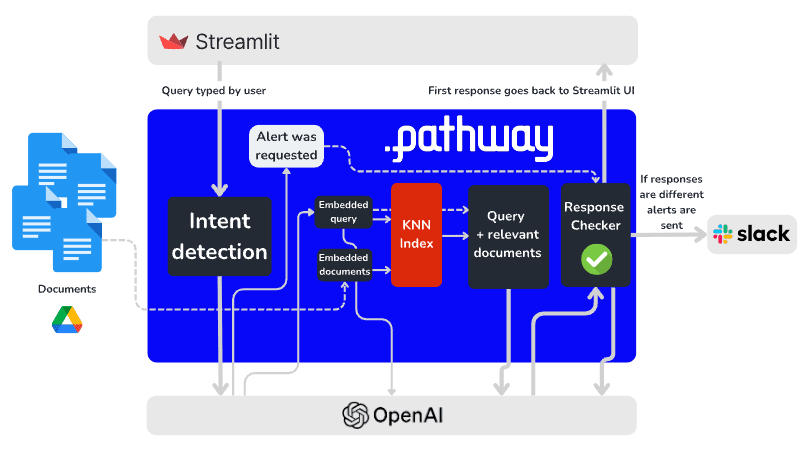
Let’s break down each component in the above architectural diagram and understand the role of various components:
Making an always up-to-date vector index of Google Drive documents: The system accesses documents stored in Google Drive and monitors them for changes using the Pathway connector for Google Drive. Next, all documents inside a chosen folder are parsed (we support native Google Docs formats, Microsoft’s docx, and many others) and split into short, mostly self-contained chunks that are embedded using the OpenAI API and indexed in real-time using the Pathway KNN index.
Answering queries and defining alerts: Our application running on Pathway LLM-App exposes the HTTP REST API endpoint to send queries and receive real-time responses. It is used by the Streamlit UI app. Queries are answered by looking up relevant documents in the index, as in the Retrieval-augmented generation (RAG) implementation. Next, queries are categorized for intent: an LLM probes them for natural language commands synonymous with notify or send an alert.
Alert Generation and Deduplication: Pathway LLM-App automatically keeps the document index up to date and can efficiently update answers whenever significant documents change! To learn more, please see our indexing tutorial. However, sometimes a change in a source document is non-consequential, a colleague might for example fix some typos. To prevent the system from sending spurious alerts, we use pw.stateful.deduplicate. The deduplicator uses an LLM “acceptor function” to check if the new answer is significantly different.
Finally, relevant alerts are sent to Slack using a Python callback registered using pw.io.subscribe.
Our goal today: alerts for marketing campaigns
We focus on an example where we would like to have real-time alerts for significant changes or updates in marketing campaigns. This system can monitor various aspects such as content changes, campaign performance metrics, audience engagement, and budget alterations. Real-time alerts enable marketing teams to respond quickly to changes, ensuring campaigns remain on track and are optimized for performance.
After successfully running the Google Drive Alerts with the LLM app,
Either go to Streamlit and try typing in “When does the Magic Cola campaign start? Please notify me about any changes.”
GIF

Or send a curl to the endpoint with
The response we will get is something like “The campaign for Magic Cola starts on December 12, 2023” based on the document you have in your Google Drive folder. The app also activates an alert for future changes.
Then you go to the folder called “Product Marketing” and open the document called “campaign-cola” in Google Drive, modify the line with the “Campaign Launch” and set the date to “January 1st, 2024”. You should receive a Slack notification immediately “Change Alert: The campaign for Magic Cola starts on July 1st, 2024”.
Depending on captured changes in real-time and predefined thresholds (like a certain percentage drop in click-through rate or a significant budget overrun), the system triggers an alert.
You can also try setting up a new document with revised information about the campaign date, and see how the system picks up on pieces of information from different source files. As we will see later, we can adjust how the system reacts to different pieces of information through a technique called “prompting”.
For example, you can explain to the LLM, in natural language, how it should best reply if it sees a conflict between information seen in two different places.
The same solution can be applied for monitoring the marketing campaign across different platforms including content management systems, social media tools, and email marketing software.
Tutorial - Creating the app
The app development consists of two parts: backend API and frontend UI. The full source code can be found on the GitHub repo.
Part 1: Design the Streamlit UI
We will start with constructing Streamlit UI and create a simple web application with Streamlit. It interacts with an LLM App over REST API and displays a chat-like interface for the user sending prompts and notifying the user when an alert is activated. The main page of the web app is set up with a text input box where users can enter their queries. See the full source code in the server.py file.
...
prompt = st.text_input("How can I help you today?")
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
...
We manage a chat history using Streamlit's session state. It displays previous messages and adds new ones as they are entered.
...
if prompt:
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
for message in st.session_state.messages:
if message["role"] == "user":
st.sidebar.text(f"📩 {message['content']}")
...
When the user enters a prompt, the above script adds it to the chat history to maintain different chats for each user.
...
url = f"http://{api_host}:{api_port}/"
data = {"query": prompt, "user": "user"}
response = requests.post(url, json=data)
if response.status_code == 200:
response = response.json()
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error(
f"Failed to send data to Discounts API. Status code: {response.status_code}"
)
...
This prompt will be sent to the LLM App via REST API. It also includes basic error handling for the API response, checking the status code, and displaying an error message if the call is unsuccessful.
Part 2: Build a backend API
Next, we develop the logic for the backend part where the app ingests Google Docs in real-time, detects changes, creates indexes, responds to user queries, and sends alerts. See the full source code in the app.py file.
def run(
*,
data_dir: str = os.environ.get(
"PATHWAY_DATA_DIR", "./examples/data/magic-cola/local-drive/staging/"
),
api_key: str = os.environ.get("OPENAI_API_KEY", ""),
host: str = "0.0.0.0",
port: int = 8080,
embedder_locator: str = "text-embedding-ada-002",
embedding_dimension: int = 1536,
model_locator: str = "gpt-3.5-turbo",
max_tokens: int = 400,
temperature: float = 0.0,
slack_alert_channel_id=os.environ.get("SLACK_ALERT_CHANNEL_ID", ""),
slack_alert_token=os.environ.get("SLACK_ALERT_TOKEN", ""),
**kwargs,
)
Everything that happens in the main run() function accepts several parameters, many of which have default values. These include paths OpenAI API keys (api_key), server configuration (host, port), model identifiers (embedder_locator, model_locator), and Slack channel ID where alerts are sent (slack_alert_channel_id) and Slack token (slack_alert_token) to secure authenticate with the Slack.
Building an Index
Next, the app reads the Google Docs files from the path specified in the data_dir and processes them into documents. These documents are chunked, flattened, and then enriched with OpenAI embeddings. A K-Nearest Neighbors (KNN) index is created using these embeddings.
files = pw.io.gdrive.read(
object_id="FILE_OR_DIRECTORY_ID",
service_user_credentials_file="secret.json",
)
documents = files.select(texts=extract_texts(pw.this.data))
documents = documents.select(
chunks=chunk_texts(pw.this.texts, min_tokens=40, max_tokens=120)
)
documents = documents.flatten(pw.this.chunks).rename_columns(doc=pw.this.chunks)
enriched_documents = documents + documents.select(
data=embedder.apply(text=pw.this.doc, locator=embedder_locator)
)
index = KNNIndex(
enriched_documents.data, enriched_documents, n_dimensions=embedding_dimension
)
Query Processing
Next, we add a function to set up an HTTP connector to receive queries. Queries are processed to detect intent using the OpenAI Chat completion endpoint and prepare them for response generation. This includes splitting answers and embedding the query text.
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
model = OpenAIChatGPTModel(api_key=api_key)
query += query.select(
prompt=build_prompt_check_for_alert_request_and_extract_query(query.query)
)
query += query.select(
tupled=split_answer(
model.apply(
pw.this.prompt,
locator=model_locator,
temperature=temperature,
max_tokens=100,
)
),
)
query = query.select(
pw.this.user,
alert_enabled=pw.this.tupled[0],
query=pw.this.tupled[1],
)
query += query.select(
data=embedder.apply(text=pw.this.query, locator=embedder_locator),
query_id=pw.apply(make_query_id, pw.this.user, pw.this.query),
)
Responding to Queries
The processed user queries are used to find the nearest items in the KNN index we built. A prompt is built using the query and the documents retrieved from the index. The OpenAI model generates responses based on these prompts. Finally, the responses are formatted and sent back to the UI using the response_writer.
query_context = query + index.get_nearest_items(query.data, k=3).select(
documents_list=pw.this.doc
).with_universe_of(query)
prompt = query_context.select(
pw.this.query_id,
pw.this.query,
pw.this.alert_enabled,
prompt=build_prompt(pw.this.documents_list, pw.this.query),
)
responses = prompt.select(
pw.this.query_id,
pw.this.query,
pw.this.alert_enabled,
response=model.apply(
pw.this.prompt,
locator=model_locator,
temperature=temperature,
max_tokens=max_tokens,
),
)
output = responses.select(
result=construct_message(pw.this.response, pw.this.alert_enabled)
)
response_writer(output)
Sending Alerts
The below code filters responses that require alerts. A custom logic (acceptor) is used to determine if an alert should be sent based on the content of the response. Alerts are constructed and sent to a specified Slack channel.
responses = responses.filter(pw.this.alert_enabled)
def acceptor(new: str, old: str) -> bool:
if new == old:
return False
decision = model(
build_prompt_compare_answers(new, old),
locator=model_locator,
max_tokens=20,
)
return decision_to_bool(decision)
deduplicated_responses = deduplicate(
responses,
col=responses.response,
acceptor=acceptor,
instance=responses.query_id,
)
alerts = deduplicated_responses.select(
message=construct_notification_message(
pw.this.query, pw.this.response, add_meta_info(data_dir)
)
)
send_slack_alerts(alerts.message, slack_alert_channel_id, slack_alert_token)
Execution
This is a place where all magic happens. The function ends with a call to pw.run, indicating that this is part of a data pipeline that runs continuously. Optionally, we also enable a real-time monitoring feature.
pw.run(monitoring_level=pw.MonitoringLevel.NONE)
How to run our application
Step 0. Your checklist: what we need to get started
A running Python environment on MacOS or Linux
A Google account for connecting to your own Drive
- Before running the app, you will need to give the app access to Google Drive folder, please follow the steps provided in the Readme.
(Optional) A slack channel and API token
For this demo, Slack notification is optional and notifications will be printed if no Slack API keys are provided. See: Slack Apps and Getting a token
If no Slack token is provided, notifications will be printed.
Step 1. Get started with LLM-App and test out the ready example
Next, navigate to the repository:
Almost there!
Step 2. Get the app running
Edit the
.envfile with the instructions provided in the Readme.We need to execute
pythonapp.py, follow the instructions in Running the project to get the app up and ready!
What is next
As we have seen in the example of the marketing campaign demo, real-time alerts with LLMs keep the entire team updated on critical changes and help teams stay agile, adjusting strategies as needed. LLM App’s alerting feature can also be used for monitoring model performance when LLMs can occasionally produce unexpected or undesirable outputs. In cases where LLMs are used for processing sensitive data, real-time alerting can be useful for security and compliance too.
Consider also visiting another blog post on How to build a real-time LLM app without vector databases. You will see a few examples showcasing different possibilities with the LLM App in the GitHub Repo. Follow the instructions in Get Started with Pathway to try out different demos.
About the author
Visit my blog: www.iambobur.com
Follow me on LinkedIn Bobur Umurzokov
Subscribe to my newsletter
Read articles from Bobur Umurzokov directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bobur Umurzokov
Bobur Umurzokov
𝐖𝐡𝐨 𝐈 𝐚𝐦 Bobur is a developer advocate and speaker specializing in software and data engineering. With over 10- years of experience in IT, he blogs about open-source technologies and the community around them. 𝐖𝐡𝐚𝐭 𝐈 𝐝𝐨 I work with companies at different scales to build awareness, drive adoption, and engage with the community for your developer-targeted products. I also create inspiring content, design, and code use cases, projects, and demo apps to boost learning your product.