Optimising Celery Performance: A Guide to Load Testing with Locust.io
 Bjoern Stiel
Bjoern Stiel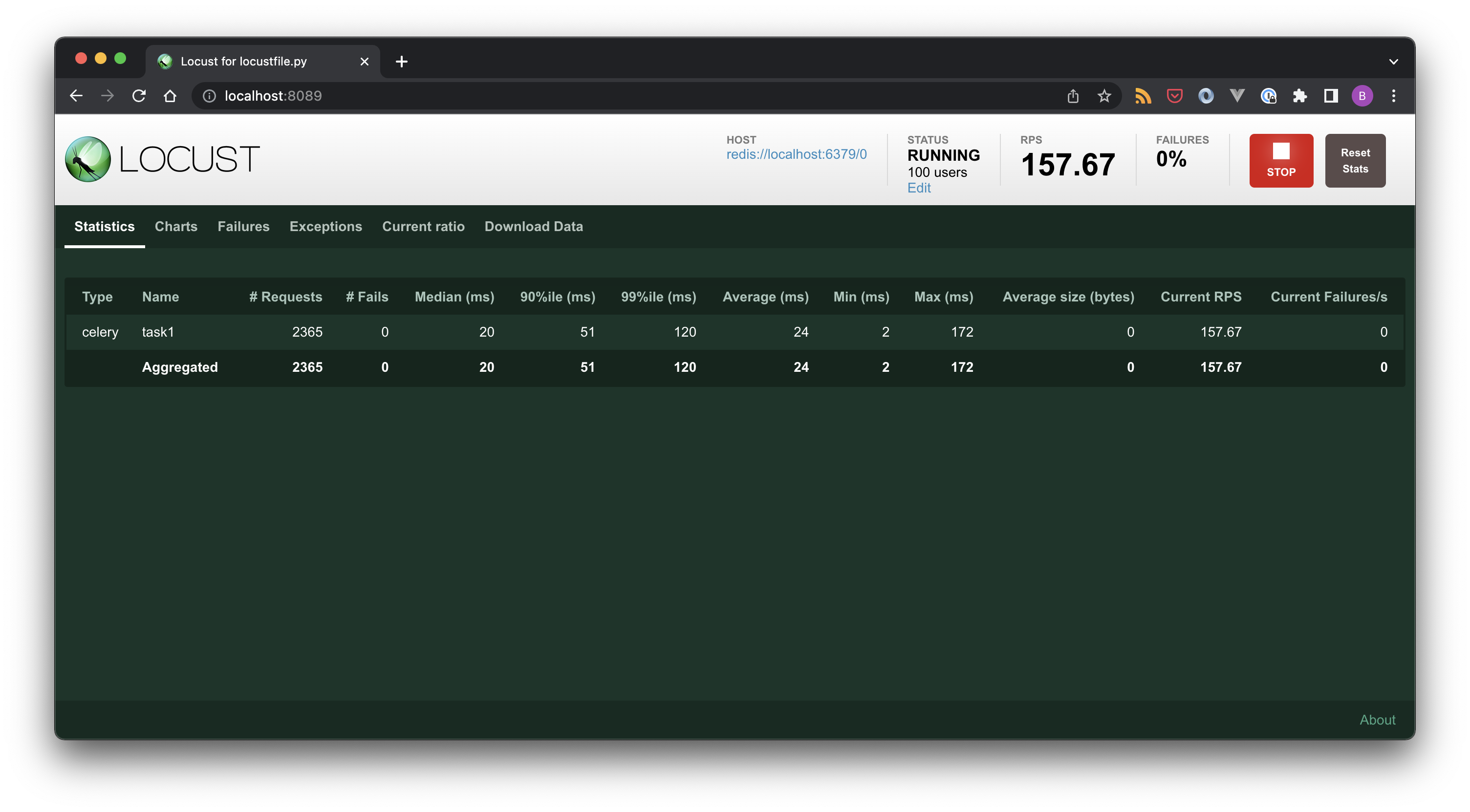
Load testing is a way to determine the capacity, stability and response times of your application.
During a load test, some specialised load testing software simulates demand on your app by spawning concurrent users and collects metrics such as response times and error rates.
These metrics show you a picture of how many concurrent requests your application can handle and help you identify and address bottlenecks.
Locust
Locust is an open-source, Python-based load-testing tool. Locust is scriptable, developer-friendly and includes an easy-to-use web user interface. Locust (version 2.15.1) requires Python 3.7 or newer. Install the locust package with pip and verify your locust installation:
$ pip install locust
$ locust -V
First steps with Locust
Similar to Python unit tests, Locust test cases are scripted in plain Python code and go into a special file,locustfile.py. Let's say we wanted to load-test an app that exposes these two REST endpoints:
GET /GET /users
# loucstfile.py
from locust import HttpUser, task
class APIClient(HttpUser):
@task
def test_home(self):
self.client.get("/")
@task
def test_users(self):
self.client.get("/users")
A Locust test class always inherits fromlocust.User. In this case, I use the specialisedlocust.HttpUser, which provides support for HTTP-based load tests. I write one method for each endpoint. Save to locustfile.py and start Locus like so:
$ locust --host=http://localhost:8000 --users=50 --spawn-rate=10 --autostart
Locust runs the two test cases APIClient.test_home and APIClient.test_users against http://localhost:8000/ and http://localhost:8000/users respectively, spawning 10 new users per second (spawn-rate) until it reaches a total number of 50 concurrent users.
The two tests are picked at random, resulting in a 50/50 distribution. This this can be configured by applying different weightings per test method.
Head over to the Locust web UI at http://localhost:8089 which provides several metrics as well as manual control parameters.
Locust and Celery
You can use Locust to run load tests against anything, including Celery. Unfortunately, Locust does not come with Celery battery included, so some customisation is required. Essentially, we need to code up the Celery equivalent of the locust.HttpUser.
The trick is to wrap the Celery client so we can pass information to Locust about the Celery task's name, start and end time and task exceptions.
# locustfile.py
import time
import datetime
import ssl
from celery import Celery
from locust import User, between, task, events
@events.init_command_line_parser.add_listener
def _(parser):
"""
Additional command line/ui argument for Celery backend url.
"""
parser.add_argument("--backend", type=str, env_var="LOCUST_CELERY_BACKEND", default="", required=True, include_in_web_ui=True, help="Celery backend url")
class CeleryClient:
"""
CeleryClient is a wrapper around the Celery client.
It proxies any function calls and fires the *request* event when they finish,
so that the calls get recorded in Locust.
"""
def __init__(self, broker, backend, task_timeout, broker_pool_limit, request_event):
kwargs = {
"broker": broker,
"backend": backend,
"broker_pool_limit": broker_pool_limit
}
# support SSL/TLS redis broker
if broker.startswith("rediss://"):
kwargs["broker_use_ssl"] = {"ssl_cert_reqs": ssl.CERT_NONE}
# support SSL/TLS redis backend
if backend.startswith("rediss://"):
kwargs["redis_backend_use_ssl"] = {"ssl_cert_reqs": ssl.CERT_NONE}
self.client = Celery(**kwargs)
self.task_timeout = task_timeout
self._request_event = request_event
def send_task(self, name, args=None, kwargs=None, queue=None):
options = {}
if queue:
options["queue"] = queue
request_meta = {
"request_type": "celery",
"response_length": 0,
"name": name,
"start_time": time.time(),
"response": None,
"context": {},
"exception": None,
}
t0 = datetime.datetime.utcnow()
try:
async_result = self.client.send_task(name, args=args, kwargs=kwargs, **options)
result = async_result.get(self.task_timeout) # blocking
request_meta["response"] = result
t1 = async_result.date_done
except Exception as e:
t1 = None
request_meta["exception"] = e
request_meta["response_time"] = None if not t1 else (t1 - t0).total_seconds() * 1000
self._request_event.fire(**request_meta) # this is what makes the request actually get logged in Locust
return request_meta["response"]
class CeleryUser(User):
def __init__(self, environment):
super().__init__(environment)
self.client = CeleryClient(
broker=environment.host,
backend=environment.parsed_options.backend,
task_timeout=environment.stop_timeout,
request_event=environment.events.request)
class CeleryTask(CeleryUser):
@task
def test_task1(self):
self.client.send_task("task1")
@task
def test_task2(self):
self.client.send_task("task2")
The magic happens around the request_event variable which is exposed via the environmentproperty, which in turn is available on the locust.User class.
The idea is to capture essential information like start time, end time, exception and response and pass them off to Locust via a set of keyword arguments:
self._request_event.fire(
request_type="celery",
response_length=0,
name=...,
start_time=...,
response_time=...
response=...,
context={},
exception=...)
Remember that Celery tasks are asynchronous by design. Here, async_result.get(...) explicitly waits for the task to finish so we can capture the response and response time as well as any exception. This blocks the simulated Celery user that Locust spawns.
However, Locust "spawns" exactly one greenlet per simulated user. This means that a greenlet that waits for a Celery task to finish, does not block any other concurrent greenlet.
Timeouts
By default, async_result.get(...) does not time out. You can use the command line option --stop-timeout to set a task timeout in seconds. It depends on your Celery settings and task configuration (eg soft and hard time limits) whether you want to perform the load test with a timeout.
For example, if you want a task to be recorded as failed after 30 seconds, use a 30-second timeout:
$ locust --host=http://localhost:8000 --users=50 --spawn-rate=10 --stop-timeout=30 --autostart
The source code to run Locust against Celery is available on Github.
Do you load-test your Celery cluster? I would love to hear from you. Leave a comment below 👇 or drop me an email: bjoern.stiel@celery.school.
Subscribe to my newsletter
Read articles from Bjoern Stiel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by