PY3. Pandas - Data Manipulation and Analysis
 Debjoty Mitra
Debjoty Mitra
Introduction
Python's Pandas package is used to manipulate data collections. It offers tools for data exploration, cleaning, analysis, and manipulation. Wes McKinney came up with the name "Pandas" in 2008, and it refers to both "Panel Data" and "Python Data Analysis.”
How to Install Pandas
To install Pandas, first, make sure that Python and Pip is already installed in your system. If they are installed, then you can install Pandas just by running this command on the command line.
>> pip install pandas
You can use other Python distributions like Spyder or Anaconda where pandas are already installed.
Write your first code using Pandas

To use Pandas in our code, first, we have to import it. Here we are importing pandas as pd. Here, pd is an alias for panda.
Series
A series in pandas is like a column in a table that can hold data like a one-dimensional array of any type. To create a Pandas series, we can write this code:
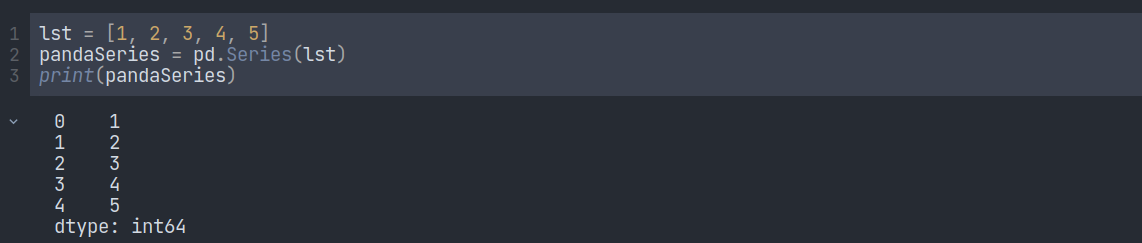
Here we have used a method called Series() to convert a list into a series. After that, we can print the series using print() function. If we observe the output, we will see that there are 5 rows and 2 columns. In the end, it shows the data type of the elements in the list that we have converted into a series. The first column is the column of labels. If nothing else is specified, the values are labeled with their index number. The first value has an index of 0, the second value has an index of 1, etc. This label can be used to access a specified value.

Now, it's clear that we can use the labels as an index and access a specific value using it. The fun thing is, that we can name our own labels using the index argument.

After creating our labels, we can access an item by referring to the label like we access a dictionary value using the key:

Key/Value Objects as Series
You can also use a key-value object, like a dictionary when creating a series.
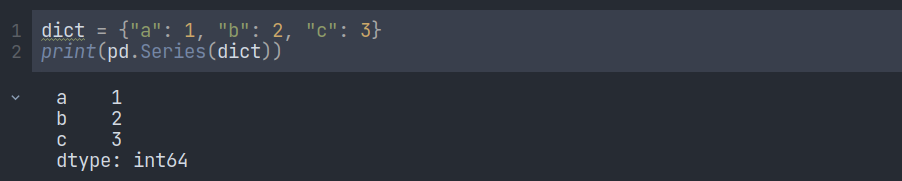
Use the index option to specify only the words you wish to be included in the Series, leaving out the rest of the words in the dictionary.

Now let's see what happens when we add two series.
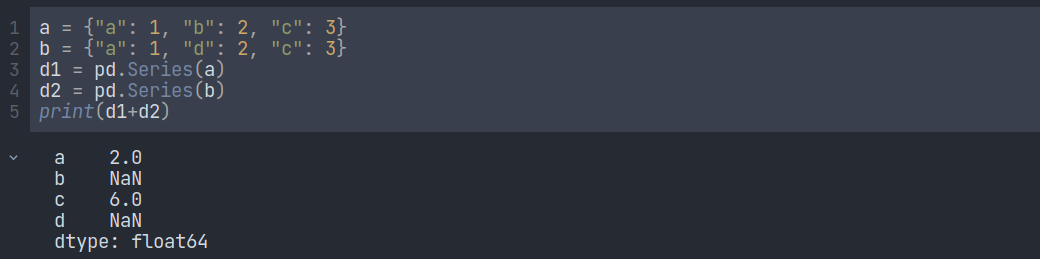
It is creating a new series by adding the same labeled data together and converting them into floats. If the same index is missing, then the output will be NaN.
DataFrames
A Pandas DataFrame is a 2-dimensional data structure, like a 2-dimensional array, or a table with rows and columns. To understand it better, first, let’s compare it with the pandas series.
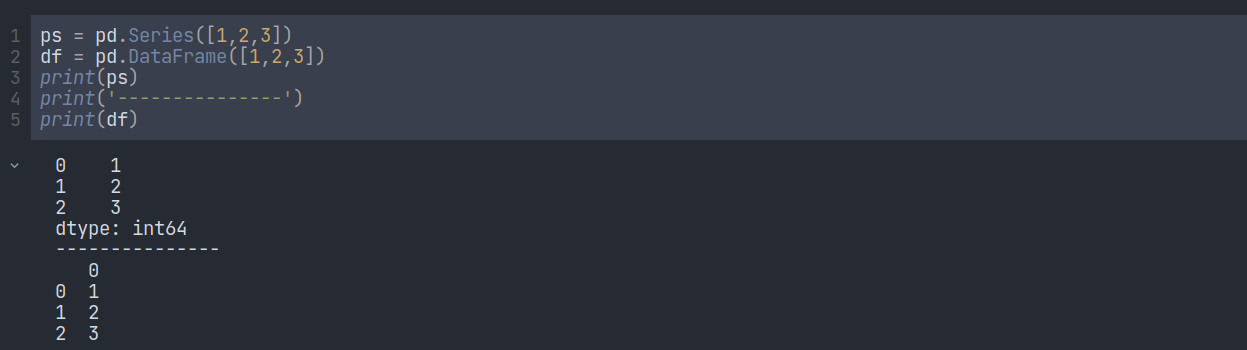
The first visible difference here is that a series has a specific data type, but a data frame doesn’t.
Dictionary and Data Frame
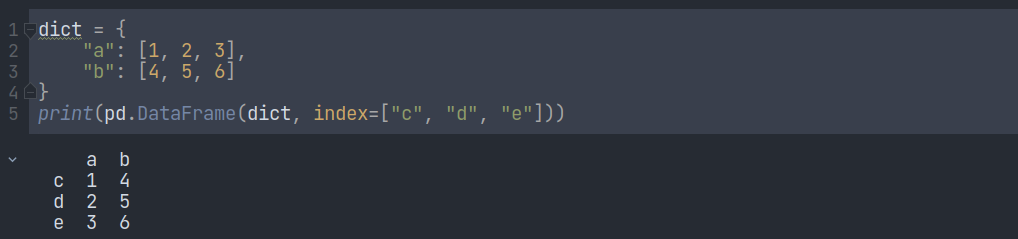
Here we can see that the keys of the dictionary are used as the titles of the columns, and the lists are the data of the columns. Now, what is happening here is that we are passing a list and it is creating a data frame. It also defines its index and column names on its own. If we want to use our own name as an index or column name, we have to pass it as an argument through the DataFrame() method.
Generate Data Frame
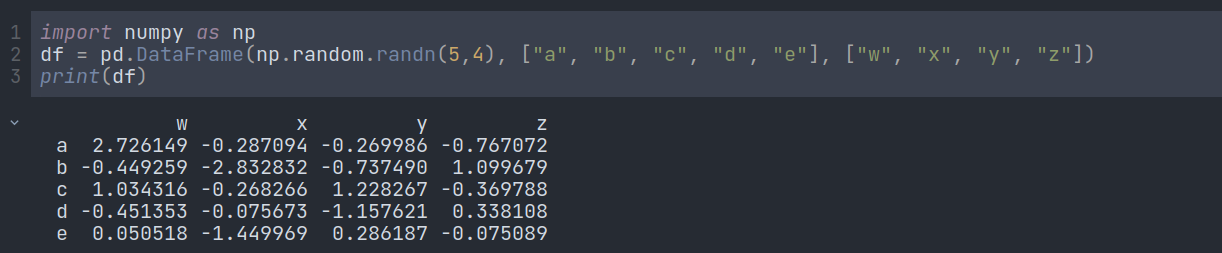
In the example above, we are passing a 2D array, index, and column name. After that, the DataFrame() method automatically allocates the index and column name.
Selection and Indexing
Firstly, DataFrame columns are just Series:

Now, let’s learn the various methods to grab data from a DataFrame
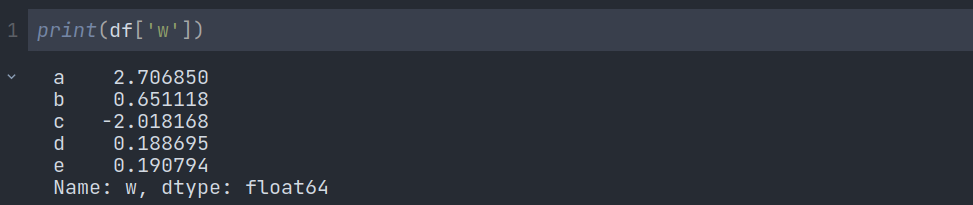
We can grab any column by using the column name. To access multiple columns, we have to pass a list of column names like this:
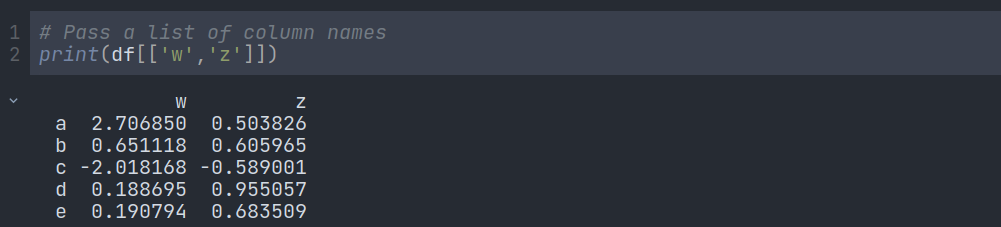
We can also use the SQL Syntax but it is not recommended as it creates confusion:
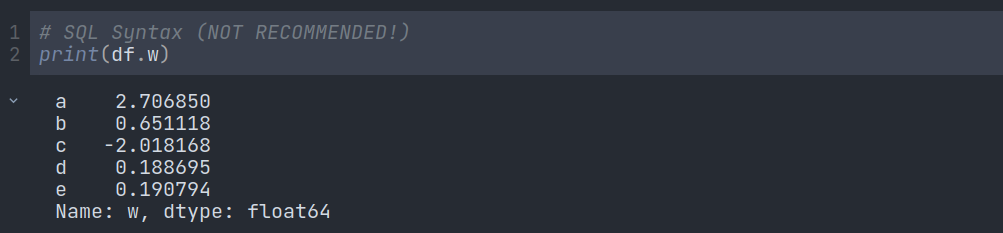
Creating a new column:
We can add a new column to our DataFrame like below. We can assign either an Array or Series to define the new column. In the example below, we are adding two columns, which are basically two series, and assigning a new column named ‘new’:
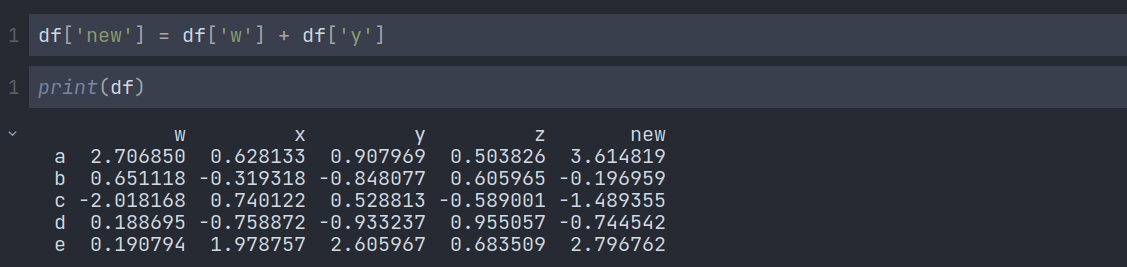
Removing Columns
We have to use.drop() a method to drop a column or row. Here axis=0 means row and axis=1 means column. We have to mention it if we want to remove the column. The default value is 0.
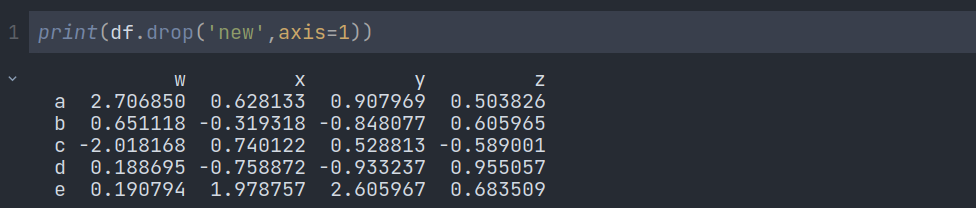
But there is a problem. If we try to print df again, we will see that column new is still there.
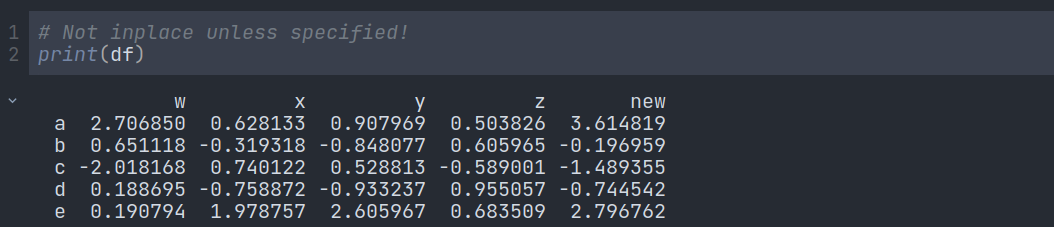
But why? Because to remove the column completely from the DataFrame, we have to use the inplace attribute. The Python developers kept that feature so that we do not have to face unwanted data loss.
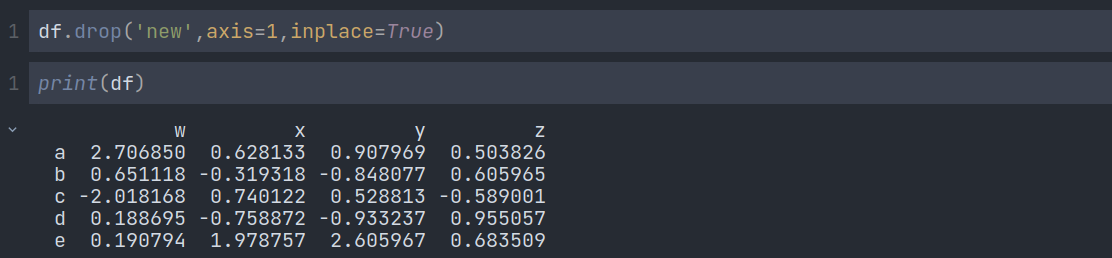
Congratulations! The new column is completely removed from the data frame. We can also drop a row by changing the axis from 1 to 0:

Locate Rows
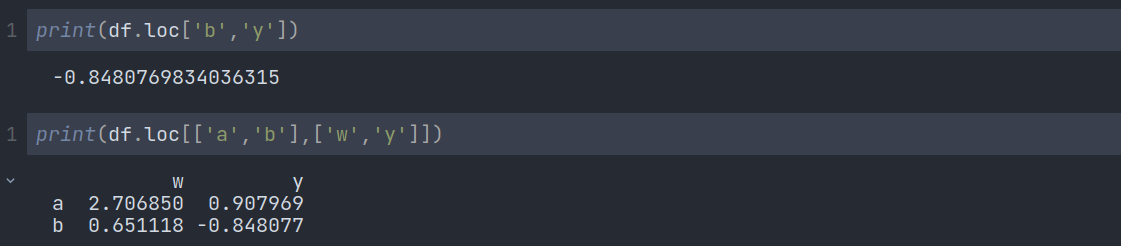
We already know that a data frame is like a table with rows and columns. If we want to display or store a specific row, we have to use the loc method:

Alternatively, you can choose based on position rather than the label using iloc:

We can also select a subset of rows and columns by the following method:
Conditional Selection
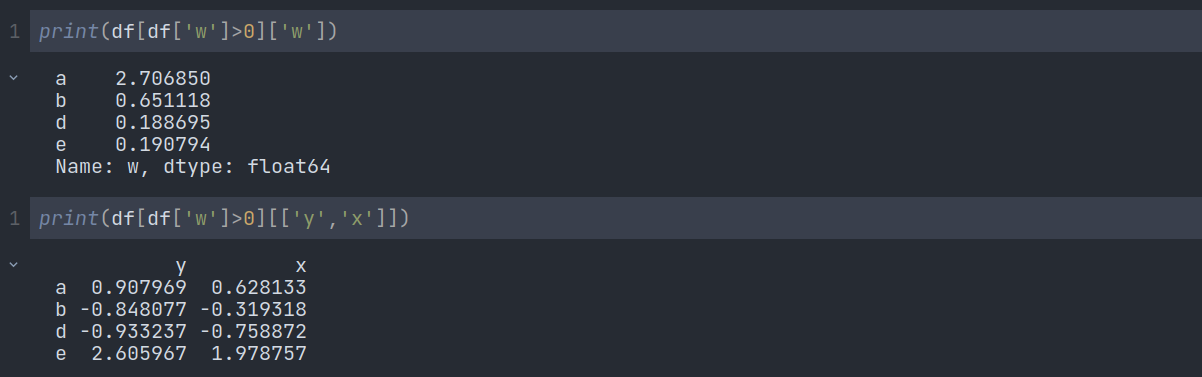
An important feature of pandas is conditional selection using bracket notation, very similar to Numpy:

Here we can see a truth table based on the conditions we have given. When a cell satisfies our conditions, it's giving True. Otherwise, it's giving false. Now, if we want to print the value instead of true or false, we can write our code like this:

Now, it is printing only the values that satisfy our conditions.
What if our condition is only based on a specific column and we want to print the values according to the data of that column? In that case, we have to mention that specific column using this notation:

For printing a specific column of our new filtered data frame, we just have to mention this like this:
For two conditions, you can use | and & with parenthesis:

More Index Details Let's discuss some more features of indexing, including resetting the index or setting it to something else. We'll also talk about index hierarchy!
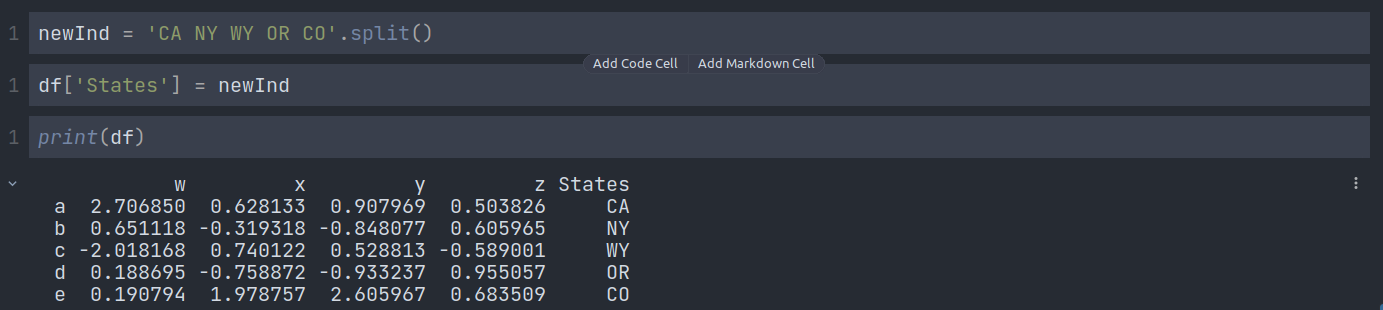
By using the .split() function, we can create a new column. It will create a list, and then we will create a new column using that:
We can also set an existing column as an index by using the set_index() method and passing the name of the column through it:

Again, we have to use the inplace argument if we want to make the change permanent.
Missing Data
Let's show a few convenient methods to deal with missing data in pandas:
First, let’s create a new data frame using a dictionary:

Here what we are doing is, we are intentionally putting some nan data to our data frame and assuming that those are missing data.
If we want to remove those missing values from our data frame, there is a method called .dropna(). It will remove all the rows that contain at least one missing data point. We can use the asix argument if we check the missing data column-wise.
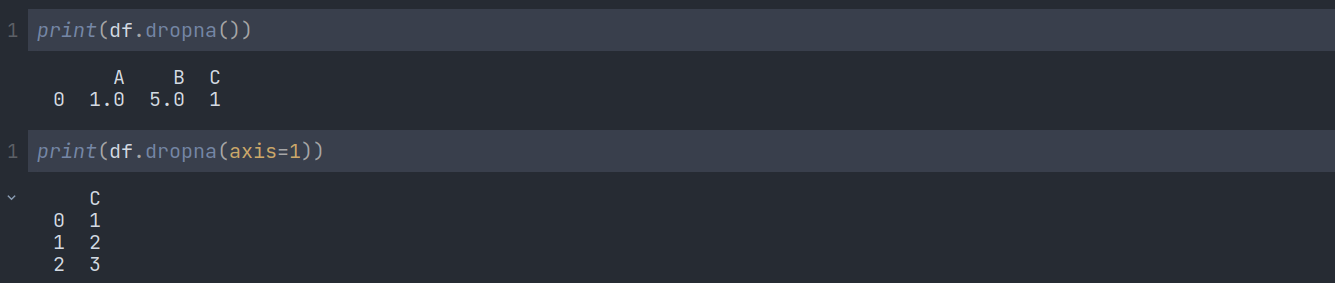
We can use the thresh attribute if we need to keep some missing values by mentioning how many missing values we will consider:

Here, thresh=2 means - keep only the rows with at least 2 non-NA values.
If we want to fill our missing values with something else, we have to write our code like that by using the .fillna() method:

Sometimes we have to fill in our missing data using a mean value. For that, we can code like this:

Groupby
Groupby allows you to group together rows based on a column and perform an aggregate function on them. Here aggregate function means a function that takes some data and returns it as the sum of those data or the mean value of those data.
Firstly, let us create a data frame using a dictionary:
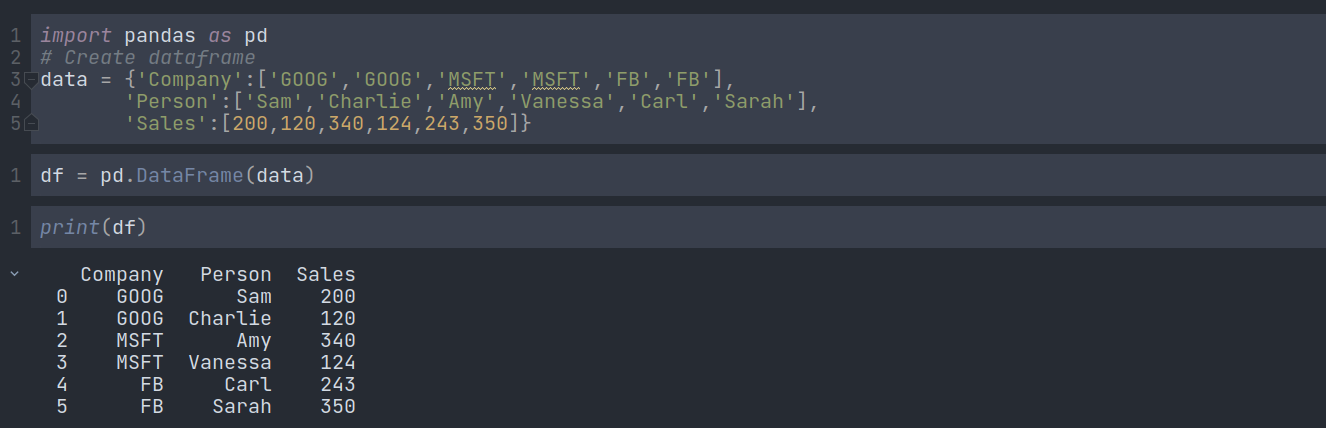
Now you can use the .groupby() method to group rows together based on a column name. For instance, let's group based on company. This will create a DataFrameGroupBy object:

You can save this object as a new variable:

And then call aggregate methods on the object:

Here, we are using the variable to call aggregate methods on the object. We can also do this directly like this:

More examples of aggregate methods:

You can also do things such as max and min.


Some other useful aggregate functions that you may find yourself doing are things such as count which just counts the number of instances or columns. In this case, it was able to return the person column because it's able to count how many instances of a person occur in that column or company. So we have two people and they have two sales each and that makes sense.

One last useful thing I want to show you with groupby is the describe() method and that gives you a bunch of useful information all at once.

And if you don't like this format, you can actually transpose this. So, you can say something like:

So, whatever format you like better you can describe to that and then you can actually just call column names of this if you're just interested in a single column.

Subscribe to my newsletter
Read articles from Debjoty Mitra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by