APEX_STRING.SPLIT, Pipelined Functions, and Pickler Fetches
 Martin Giffy D'Souza
Martin Giffy D'SouzaWell that's a loaded title! Most developers may not know what each term means and as such this article will break down each item then group it all together.
apex_string.split
apex_string.split allows you to split a delimited string into rows (similar procedures exists for numbers and clobs).
select s.column_value
from apex_string.split('emp,dept', ',') s
;
COLUMN_VALUE
------------
emp
dept
Pipelined Functions
Pipelined functions are PL/SQL functions that "pipe rows" and are selectable as a table in a SQL. apex_string.split is a pipelined function. Oracle Base has a great article all about pipelined table functions which you're encouraged to read and learn more about.
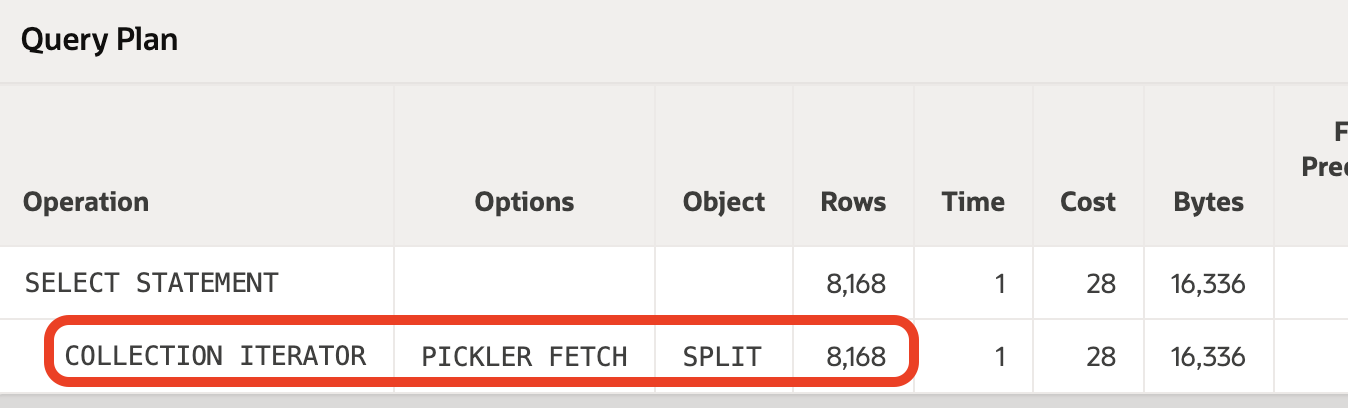
Pickler Fetch
You may have seen COLLECTION ITERATOR PICKLER FETCH in an Oracle explain plan but never understood what they are. Martin Widlake has a great post about this here. TL;DR Oracle is processing something of unknown number of rows and needs to provide the optimizer with a number of rows. It defaults to 8168 rows.
apex_string.split, Pipelined Functions, and Pickler Fetches
Putting it altogether now. When using apex_string.split in your queries you could be introducing a performance problem without even realize it. The following example highlights this.
-- Create a large table
-- This may take a while to run
create table all_objs as
select object_name
from all_objects
;
-- If using SQL Dev Web run the next three all at the same time
alter session set optimizer_capture_sql_plan_baselines=true;
select ao.object_name
from all_objs ao
join apex_string.split('EMP,DEPT',',') s on 1=1
and s.column_value = ao.object_name
;
select plan_table_output
from table(dbms_xplan.display_cursor(null,null,'typical'))
;
SQL_ID cq8vm0pb4jacn, child number 0
-------------------------------------
select ao.object_name from all_objs ao join
apex_string.split('EMP,DEPT',',') s on 1=1 and s.column_value =
ao.object_name
Plan hash value: 1741181693
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 112 (100)| |
|* 1 | HASH JOIN | | 13550 | 529K| 112 (1)| 00:00:01 |
| 2 | JOIN FILTER CREATE | :BF0000 | 8168 | 16336 | 29 (0)| 00:00:01 |
| 3 | COLLECTION ITERATOR PICKLER FETCH| SPLIT | 8168 | 16336 | 29 (0)| 00:00:01 |
| 4 | JOIN FILTER USE | :BF0000 | 46481 | 1724K| 82 (0)| 00:00:01 |
|* 5 | TABLE ACCESS STORAGE FULL | ALL_OBJS | 46481 | 1724K| 82 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("AO"."OBJECT_NAME"=VALUE(KOKBF$))
5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"AO"."OBJECT_NAME"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"AO"."OBJECT_NAME"))
The plan from the example above highlights that the overall cardinality estimate is 13550 rows.
If you know the approximate number of items in the apex_string.split then a SQL hint can be applied to the query to tell the optimizer what to expect. The following demo highlights this. Using the previous example, it is a known fixed list of two items.
select
-- Note "s" refers to the table alias below
/*+ cardinality (s, 2) */
ao.object_name
from all_objs ao
join apex_string.split('EMP,DEPT',',') s on 1=1
and s.column_value = ao.object_name
;
select plan_table_output
from table(dbms_xplan.display_cursor(null,null,'typical'));
SQL_ID 80h36ywn1rjjn, child number 0
-------------------------------------
select -- Note "s" refers to the table alias below
/*+ cardinality (s, 2) */ ao.object_name from all_objs ao join
apex_string.split('EMP,DEPT',',') s on 1=1 and s.column_value =
ao.object_name
Plan hash value: 1741181693
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 111 (100)| |
|* 1 | HASH JOIN | | 3 | 120 | 111 (0)| 00:00:01 |
| 2 | JOIN FILTER CREATE | :BF0000 | 2 | 4 | 29 (0)| 00:00:01 |
| 3 | COLLECTION ITERATOR PICKLER FETCH| SPLIT | 2 | 4 | 29 (0)| 00:00:01 |
| 4 | JOIN FILTER USE | :BF0000 | 46481 | 1724K| 82 (0)| 00:00:01 |
|* 5 | TABLE ACCESS STORAGE FULL | ALL_OBJS | 46481 | 1724K| 82 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("AO"."OBJECT_NAME"=VALUE(KOKBF$))
5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"AO"."OBJECT_NAME"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"AO"."OBJECT_NAME"))
-- Cleanup
drop table all_objs;
The key difference in this that the optimizer now expects 3 rows (in the HASH JOIN row) instead of 13550! When doing more complex joins this can really improve performance.
In an APEX form where the user may be selecting a several objects I tend to use orders of magnitude estimate (ex: 10, 100, 1000) for a hint.
A few key notes about SQL hints:
Just because you can doesn't mean you should. Use then when necessary (and in the above example it is justified as the optimizer has no way of knowing the expected number of rows)
Good intro article about SQL hints by David Njoku here
Subscribe to my newsletter
Read articles from Martin Giffy D'Souza directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by