Database Design Gone Better
 Deon Slabbert
Deon Slabbert
In the previous article, we created a spreadsheet acting as a database. This poorly designed database invited insert, update and delete anomalies. We also looked at the problems that null values can cause. In this article, we will attempt to remedy some of the issues we have with this poor excuse of a database.
The official name for fixing the design is called Database Normalization. I find most of the explanations of normalization confusing and sometimes conflicting, so I will just talk you through the process without getting technical at all.
We will start with the following version of the database:
| Row # | Name | Department | Job Title |
| 1 | John Smith | IT | Programmer |
| 2 | Peter King | Information Technology | Network Administrator |
| 3 | Jane Peters | IT | DBA |
| 4 | Sue Jenkins | I.T. | Database Administrator |
| 5 | J. Smith | IT | Programmer |
| 6 | Peters, Jane | InfoTech | D.B.A. |
| 7 | Jenkins, S | IT | Databse Administrator |
| 8 | Bob Hansen | IT |
First Iteration - Cleanup
During this iteration, we removed the duplicates, Jane Peters & Sue Jenkins, leaving us with the following version of the database:
| Name | Department | Job Title |
| John Smith | IT | Programmer |
| Peter King | Information Technology | Network Administrator |
| Jane Peters | IT | DBA |
| Sue Jenkins | I.T. | Database Administrator |
| J. Smith | IT | Programmer |
| Bob Hansen | IT |
Second Iteration - Identification
In the previous article, we determined that John Smith and J. Smith were, in fact, two different people. So we need a way to distinguish between the two, especially if J. Smith also turns out to be a John. The way we differentiate between rows is to ensure that each row in our database is unique. We accomplish this by giving each row a unique key. We call this a Primary Key.
So, by adding a primary key to each row, we end up with the following version of our database:
| ID | Name | Department | Job Title |
| SMI001 | John Smith | IT | Programmer |
| KIN001 | Peter King | Information Technology | Network Administrator |
| PET001 | Jane Peters | IT | DBA |
| JEN001 | Sue Jenkins | I.T. | Database Administrator |
| SMI002 | J. Smith | IT | Programmer |
| HAN003 | Bob Hansen | IT |
Naming Conventions
If you look at the ID column carefully, you will see some naming convention happening here. We use the first three characters of the employee's last name and append 001 to the first and 002 to the second employee with the same three last name characters. For example, my last name is Slabbert, and my family and I will be SLA001, SLA002, SLA003 & SLA004. And James Sladowski will be SLA005, and so on.
So is this naming convention a good one, and does it serve any purpose other than uniquely identifying a row in our database? Sometimes they serve a secondary goal. For example, during my days as a pharmacist, we used a dispensing application that used naming conventions for identifying items. For example, paracetamol came in tablets, capsules, and liquids and was identified with PAR100, PAR200, and PAR300, respectively.
However, these naming conventions have several shortcomings. What about a drug called paraldehyde? Paraldehyde is administered via intramuscular injection. Will it be identified as PAR400 in the dispensing application? What if there is a paracetamol injection, which by the way, there isn't? We cannot allow two items to have the same primary key.
The first lesson to learn when assigning IDs to rows is to be careful to give it any secondary purpose. The rule of thumb is that an ID means nothing more than uniquely defining a row. That way, there is no confusion.
Replacing our current naming convention of IDs with simple numbers solves that problem and renders the following version of the database:
| ID | Name | Department | Job Title |
| 1 | John Smith | IT | Programmer |
| 2 | Peter King | Information Technology | Network Administrator |
| 3 | Jane Peters | IT | DBA |
| 4 | Sue Jenkins | I.T. | Database Administrator |
| 5 | J. Smith | IT | Programmer |
| 6 | Bob Hansen | IT |
Third Iteration - Atomicity
The rule is a simple one. Each column value must be atomic. Thus, each column contains a single value, not a set of values. Have a look at the Name column:
| ID | Name |
| 1 | John Smith |
| 2 | Peter King |
| 3 | Jane Peters |
| 4 | Sue Jenkins |
| 5 | J. Smith |
| 6 | Bob Hansen |
Here we have three values: Last Name, First Name, and Initials. Thus our Name column is not Atomic. Let’s fix it:
| ID | Last Name | First Name | Initials | Department | Job Title |
| 1 | Smith | John | J | IT | Programmer |
| 2 | King | Peter | P | Information Technology | Network Administrator |
| 3 | Peters | Jane | JS | IT | DBA |
| 4 | Jenkins | Sue | S | I.T. | Database Administrator |
| 5 | Smith | Judy | J | IT | Programmer |
| 6 | Hansen | Bob | BJ | IT |
Immediately, we have a much better database design that dictates how the employee's name gets captured. Replacing a single Name column with three columns allows for much flexibility. For example, we can sort the data by Last Name:
| ID | Last Name | First Name | Initials | Department | Job Title |
| 6 | Hansen | Bob | BJ | IT | |
| 3 | Peters | Jane | JS | IT | DBA |
| 1 | Smith | John | J | IT | Programmer |
| 5 | Smith | Judy | J | IT | Programmer |
| 2 | King | Peter | P | Information Technology | Network Administrator |
| 4 | Jenkins | Sue | S | I.T. | Database Administrator |
We can sort the data by First Name:
| ID | Last Name | First Name | Initials | Department | Job Title |
| 6 | Hansen | Bob | BJ | IT | |
| 3 | Peters | Jane | JS | IT | DBA |
| 1 | Smith | John | J | IT | Programmer |
| 5 | Smith | Judy | J | IT | Programmer |
| 2 | King | Peter | P | Information Technology | Network Administrator |
| 4 | Jenkins | Sue | S | I.T. | Database Administrator |
We can filter the data by the Last Name Smith:
| ID | Last Name | First Name | Initials | Department | Job Title |
| 1 | Smith | John | J | IT | Programmer |
| 5 | Smith | Judy | J | IT | Programmer |
We can do automated emails, for example, that address John Smith with “Dear John” and computerized pay slips that address the same person as “J Smith.” I think you get the picture.
Fourth Iteration - Divide and Conquer
Now we need to address the Departments and Job Titles. We do not want all this duplication of data, so we create separate tables for these two columns, each with their unique IDs.
So we have a Departments table:
| ID | Name |
| 1 | Finance |
| 2 | HR |
| 3 | Sales |
| 4 | IT |
And we have a Job Titles table:
| ID | Name |
| 1 | Programmer |
| 2 | Network Administrator |
| 3 | Database Administrator |
| 4 | Representative |
Again, as you can see, the ID columns use numeric values. Sometimes, databases use things such as postal codes or zip codes and social security numbers for ID numbers. But, not all countries use postal codes in the same way. If I am not mistaken social security numbers are specific to Americans. Also, what if a country decided to change the postal code system because they ran out of numbers? Yip, that happens. The world ran out of IPv4 addresses hence the new IPv6 system.
By the way, I do not say that all Primary Keys should be numerical values. I say that the value should not have any business meaning besides indicating a unique row. For example, you can use an alpha-numeric system such as ABC123, ABC124, ..., ABC999, ABD000. Just do not give it a business meaning as well.
An insurance system I built in the '90s assigned policy numbers that consisted of 4 parts, like so: 123/345/12345/0694 which meant:
123 is the product
345 is the broker code
12345 is the policy number
0694 is the inception month and year (June 1994)
Guess that happened when a new broker with code 1000 joined. Guess what happened when policy no 100000 needed to be loaded. And guess who had to go and fix the mess after they had been warned for years that it is a bad idea to give primary keys business meaning?
So, finally, we replace the Department column with DepartmentID and the JobTitle column with JobTitleID:
| ID | LastName | FirstName | Initials | DepartmentID | JobTitleID |
| 1 | Smith | John | J | 4 | 1 |
| 2 | King | Peter | P | 4 | 2 |
| 3 | Peters | Jane | JS | 4 | 3 |
| 4 | Jenkins | Sue | S | 4 | 3 |
| 5 | Smith | Judy | J | 4 | 1 |
| 6 | Hansen | Bob | BJ | 3 | 4 |
Now we learn that there are three other departments apart from IT. We also understand that Bob is a Sales Representative, not IT, as the database initially indicated.
We call these new ID columns Foreign Keys. A foreign key in one table refers to the primary key of another table. Remember this! For example, the DepartmentID column is a foreign key in the Employee table and refers to an entry that matches the primary key in the Department table.
Last Integration - Make it Pretty
Lastly, we want to make things easy for the users of this database, and after a little effort we came up with the following version of our Employee database:
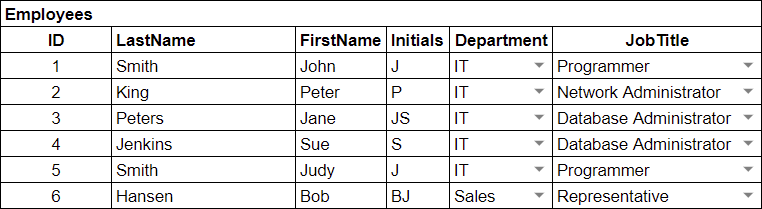
We now have a nice-looking front with dropdown options for the Department and Job Title columns:
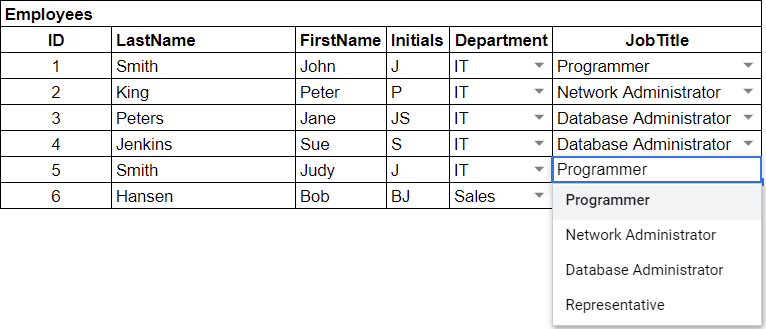
Also, say for example, that we decided to change IT to InfoTech (which is a terrible idea by the way):
| ID | Name |
| 1 | Finance |
| 2 | HR |
| 3 | Sales |
| 4 | InfoTech |
This single change will result in our whole database to be updated immediately and automatically:
| ID | LastName | FirstName | Initials | Department | JobTitle |
| 1 | Smith | John | J | InfoTech | Programmer |
| 2 | King | Peter | P | InfoTech | Network Administrator |
| 3 | Peters | Jane | JS | InfoTech | Database Administrator |
| 4 | Jenkins | Sue | S | InfoTech | Database Administrator |
| 5 | Smith | Judy | J | InfoTech | Programmer |
| 6 | Hansen | Bob | BJ | Sales | Representative |
Conclusion
Not too bad for a day’s work, is it? Although still a spreadsheet, we have a much better organized and unambiguous database. All rows are unique, all columns are atomic, and lookup tables are used where possible.
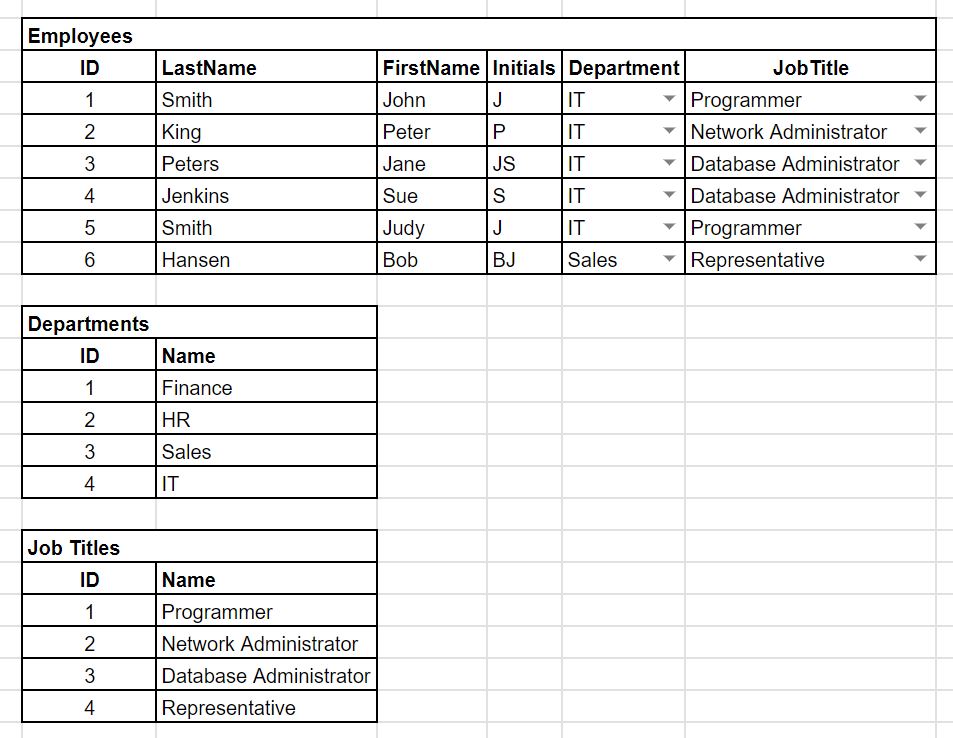
Now it is time to grow up, move away from the mighty spreadsheet, and play with the adults. So, see you next time when we start learning about real databases!
Subscribe to my newsletter
Read articles from Deon Slabbert directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Deon Slabbert
Deon Slabbert
I am a fullstack software developer with 35 years experience building enterprise applications for the financial sector and have a passion for learning & teaching others the tools of the trade