Aligning LLMs: Approaches and the Importance of Alignment in LLMs
 Aniz Bin Nowshad
Aniz Bin Nowshad
As a person who is quite passionate about advances in the realm of Large Language Models (LLMs), I thought of taking a seminar on the topic of Alignment in LLM, which is by far one of the hottest topics in Gen AI. Aligning LLMs with human preference is one of the hot topics and a pivotal factor in ensuring the effectiveness and ethical application of these powerful AI systems
In this article, I will be talking about the importance, Approaches, Challenges, and my take on it. The article mainly consists of my Seminar headings.
All you need is Alignment

All you need is Alignment was my title for the Seminar. Sounds interesting?? So first of what does ALIGNMENT mean exactly? Before moving on to alignment let me give a brief introduction to LLMs.. Ya i mean you all know, .. just for a reason..
Large Language Models (LLMs)
LLMs, foundational machine learning models utilizing deep learning algorithms for natural language processing, undergo training on extensive datasets of text and code. This training equips them with the capability to generate high-quality text, translate languages, and produce diverse creative content. Academic institutions and major tech companies such as OpenAI, Microsoft, and NVIDIA typically undertake the pre-training of these models, involving months of dedicated training and substantial computational resources.
Ya, that's like the definition that I found on the Internet 😅.no offense and this is how I would like to describe LLM,
Imagine these super-smart machines called LLMs, which learn all about language and text by reading lots of stuff like books, articles, and even computer code, lots of like millions of them. They get so good at it that they can write amazing stories, translate languages, and even come up with all sorts of cool ideas! Big universities and tech companies spend months teaching these LLMs, using lots of computer power to make them super smart.
These LLMs are like language superheroes, ready to change the way we talk to computers and how we create stuff. But, sometimes they might say things that don't quite sound like how a person would say to them, which can cause some problems. Making sure that they talk and write in a way that's fair and accurate is important if we want to use their superpowers in the right way."
And that's where Alignment comes in.
Aligning of LLMs
As the name, Alignment is basically about aligning LLMs 😅. Like making sure these language superhero machines ( which I had mentioned), the LLMs, understand us humans well. Alignment in LLMs is all about teaching them to say and write things that match up with what we want and like. It's like helping them speak our language and think like us, so we can have really good conversations and work together. When we get this right, it means the LLMs can be even more amazing and helpful, making our lives better with their super-smart abilities.
Essentially, it's about teaching machines to think and communicate in ways that resonate with Humans, making their outputs more useful and relatable.
Why is Alignment important?

Large Language Models (LLMs) are like super smart tools for understanding and generating human-like text. They can write well, translate languages, and be creative. But sometimes, even though they're really good, they can make mistakes or say things that aren't quite right. This can cause problems like spreading wrong information, making biases worse, and making people trust these smart tools less.
Making sure that LLMs match what people want is super important to use them in a good way. When LLMs match with what people like, they are more likely to:
Be Right: They give correct and reliable information, not stuff that's made up.
Be Fair: They don't make existing biases worse; they treat everyone fairly.
Be Safe: They don't say things that could hurt or upset people; they promote positive and respectful conversations.
Getting LLMs to match with people isn't just a tech problem; it's a tough challenge that needs a good understanding of how people talk and what they like. Scientists are trying different ways, like teaching them more after they're trained, using rewards and punishments, and learning from how people act. Each way has its strengths and weaknesses, and scientists are figuring out the best ways to make sure LLMs are really in sync with what people want.
Why does it matter?
So for that let us take some examples into account :
#1: Imagine you ask an LLM to create a story about a dog. It starts off well, describing a typical day for the dog. However, as the story progresses, the LLM unexpectedly adds that the dog is flying and breathing fire. This sudden change from reality is an example of hallucination in LLM-generated content.
#2: Hallucinating news.
In this context, "hallucinating news" refers to the generation of news articles or reports by LLMs that appear to be factual but are actually based on false or nonexistent information. This kind of content lacks a basis in reality and can be misleading or harmful if mistaken for truth.
this is HALLUCINATION!

where these models generate content that seems true yet lacks a basis in reality. It's like a very realistic dream that disappears when you wake up. This can be extremely dangerous if proper measures are not taken.
So what can be a solution to this problem 🤔🤔
A solution
The key to addressing this issue lies in alignment. We align LLMs with reality, giving them the ability to distinguish between genuine information and pure fiction.
Through careful adjustments and incorporating user input, we steer these models to produce content that is imaginative yet firmly rooted in reality. This alignment guarantees that the outputs are not only captivating but also trustworthy.
Aligning LLMs helps bridge this divide, ensuring that the language they generate is logical, contextually accurate, and in line with human intentions. There are various steps involved, and one of them is we substantiate the LLMs with evidence and a knowledge base.
Approaches
Making sure that large language models (LLMs) match up with what people want involves using different methods and techniques. The following are just some of the methods.
Reinforcement Learning in Human Feedback (RLHF)
Fine-tuning
Chain of Thoughts (Prompt Engineering)
RAG
Reinforcement Learning in Human Feedback (RLHF)
RLHF, or Reinforcement Learning from Human Feedback, is like teaching a robot to do a cool dance. First, you show the robot some dance moves and tell it which ones are good. Then, the robot practices those moves and gets better at them. Finally, it learns to come up with its own awesome dance moves, all while making sure it's dancing in a way that everyone loves.
So, RLHF involves a three-step process where the robot learns from human feedback and practices, and then fine-tunes its moves. By involving humans in the training process, RLHF helps create super-smart robots that can dance in a way that everyone enjoys.
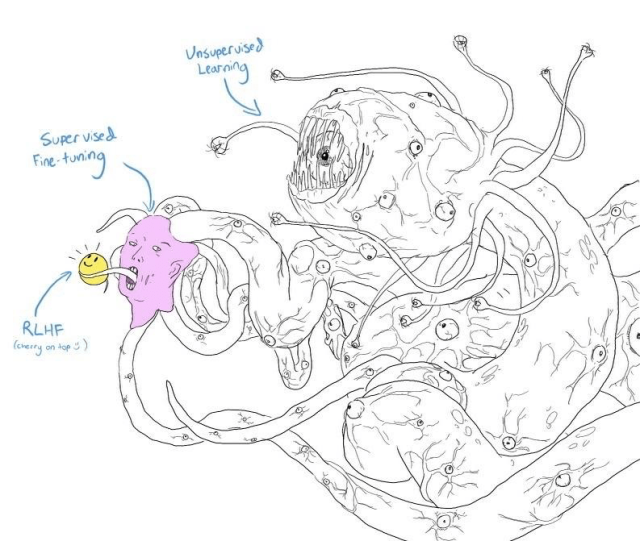
Moving on to the technical side :
RLHF, or Reinforcement Learning with Human Feedback, is a three-step process to train LLMs:
Supervised Fine-tuning: LLM learns from a large dataset using traditional supervised learning techniques.
Reward Model Training: Human feedback is used to train a reward model, based on preferences for model-generated responses.
RL Fine-tuning: The reward model guides LLM through reinforcement learning to generate responses aligned with human preferences.
Moving on to fine-tuning in general:
Fine Tuning
Fine-tuning is like giving a smart helper a bit of extra training for a specific job. Imagine you have a helper who's good at understanding lots of things, like books and websites. This helper is quite smart but not an expert in any one thing.
Now, when we fine-tune the helper, we give it some special practice using a smaller set of information just for the job we want it to do better. It's like a focused training session to make the helper really good at that specific task. We don't make the helper start from scratch; instead, we help it get even better by adjusting its settings based on what it already knows.
So, if your smart helper is already good at understanding things and you fine-tune it with information about, let's say, medicine, it becomes really skilled at understanding medical stuff. It's like turning your smart helper into a super-smart assistant for medical tasks!

Some fine-tuning approaches :
Parameter-Efficient Finetuning(PEFT): In contrast to conventional fine-tuning PEFT aims to achieve similar performance to full fine-tuning but with significantly reduced computational and storage costs. It achieves this by freezing some of the pre-trained model's layers and only fine-tuning the last few layers specific to the new task. This approach decreases the number of parameters requiring training, making the process more efficient.
Sequential Fine-Tuning: This approach involves training a language model on one task, and then incrementally refining it for related tasks. For example, a model trained on general text could be sequentially fine-tuned on medical literature to improve its performance in medical text understanding.
LIMA: LIMA stands for "Less Is More for Alignment" and proposes a novel approach to model training. Traditionally, language models undergo two stages of training: unsupervised pretraining and fine-tuning to specific tasks and user preferences. LIMA challenges this conventional approach by suggesting that most knowledge and skills of models are acquired during unsupervised pretraining.
To know more about LIMA refer to the research paper: LIMA
Chain of Thoughts (CoT)
The CoT method trains LLMs by prompting them to provide explanations for their responses, encouraging reasoning and improving the model's accuracy.
So it is like Picture this, CoT is like teaching a chatty robot to be not just smart but also a bit of a show-off. Here's the play-by-play:
Step 1: Robot Brainstorming Time! (Generating Responses) Our robot buddy is asked a question, and it goes wild coming up with different answers. Think of it like a brainstorming session but with circuits and algorithms.
Step 2: Humans Take the Stage! (Collecting Human Feedback) Now, we, the humans, step in as the superstar judges. We look at all the robot's answers and decide which one we like the most or if we have an even cooler idea. It's like a talent show for robots!
Step 3: Robot Learning Mode! (Adjusting the Model's Policy) The robot pays attention to our feedback. It's like saying, "Okay, humans, you've spoken! Let me tweak my style a bit." The robot adjusts its playbook to make sure it gives answers that we'll love next time. 😄
So, in a nutshell, CoT is the secret ingredient that turns our robot buddy into a genius entertainer. It's not just about being smart; it's about being the life of the party with explanations that make us go, "Aha, that makes sense! 🥳🥳
To know more, refer: CoT
Retrieval Augmented Generation (RAG)
RAG combines traditional text generation with a retrieval mechanism, allowing the model to generate text while also retrieving relevant information from an external knowledge source (like a database or document set).
RAG is like giving a super-smart storyteller access to a huge library. It lets the storyteller not only come up with amazing tales but also look up real facts from the library to make the stories even better.
As the go-to method for exploring enterprise data with generative AI, RAG seamlessly integrates vector databases and large language models.
Apart from its main job, RAG has extra perks. By connecting a big language model to a set of real, checkable facts, the model is less likely to accidentally use the wrong info. This lowers the chance of the model sharing secret data or making up false stories.
To know more, refer: to RAG
Conclusion
In conclusion, the development and alignment of Large Language Models (LLMs) represent a significant advancement in natural language processing. However, ensuring their alignment with human preferences and mitigating issues such as hallucinations are crucial for their responsible and effective use. Various approaches in aligning LLMs offer promising methods to achieve this alignment and enhance the capabilities of LLMs. As these technologies continue to evolve, it is essential to prioritize alignment to foster trust, accuracy, and ethical use of LLMs in diverse applications.
This is a survey which contains Research Papers on LLMs: LLM Survery
The article provides only limited information on the subject of LLMs and alignments. I've documented my knowledge on the topic to the best of my ability, using my maximum knowledge and learning. However, there may be errors in my understanding, and I welcome corrections.
Subscribe to my newsletter
Read articles from Aniz Bin Nowshad directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aniz Bin Nowshad
Aniz Bin Nowshad
I am a computer engineer and Designer. I design code develop create take photos and Travel. As a computer engineer as well as a designer, I enjoy using my obsessive attention to detail, my unequivocal love for making things that change the world. That's why I like to make things that make a difference.