Data Version Control (DVC) - the why and how - beginner guide
 Debasis
Debasis
What is version control and why do we need it? Is there any time in your life where you would have thought - 'I wish if I can go back and change something ?' It could be a relationship, a fight or something as small while cooking a dish. I for sure have thought many a times. Life doesn't give us a button using which we can go back but luckily in coding world we have, thanks to Marc Rochkind at Bell Labs. This is version control.
One of the major pain point for the industry is not using version control which has lead to significant losses. Think of version control as keeping a copy of something you are working on at intervals of time as we go along making changes and when something goes wrong we can fall back to a previous version. Or if we wanted to know what all changes have we made historically, there is always an answer. Isn't it a life saver?
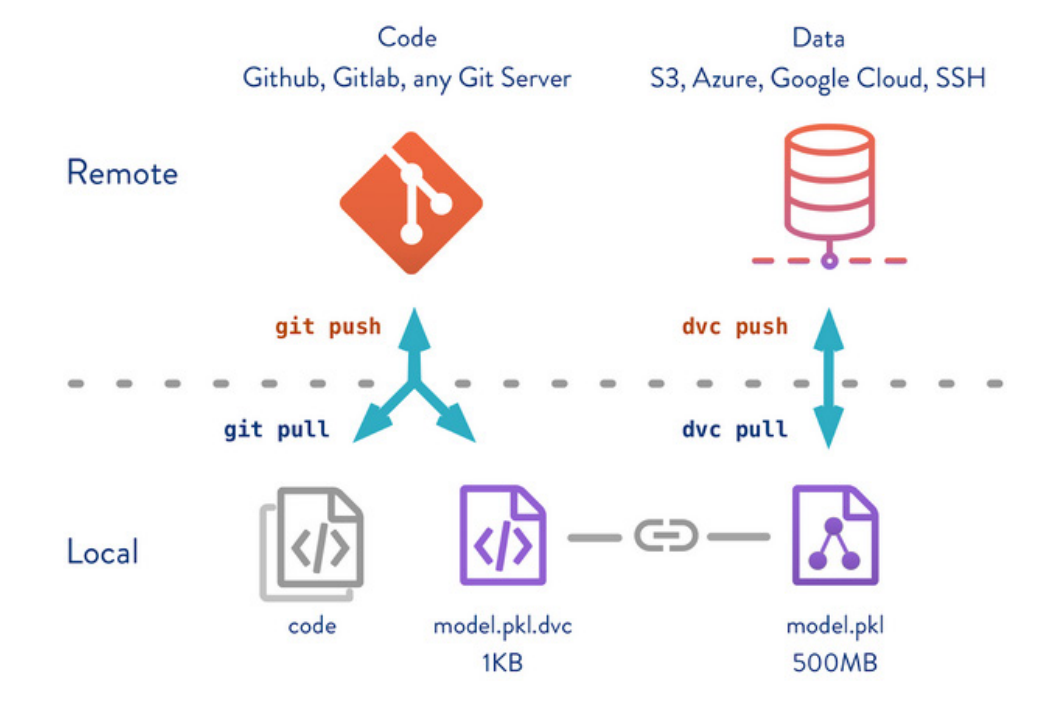
Now coming to DVC, but before that let me give you my experience why DVC is important. When I started coding, GIt and Github were major tools that was to be used to version and save codes. There are of great help and one of the best products the software industry can ever have. But when it comes to Data Science industry there is a big flaw with only using Git. In software industry, code and the few parameters are the most important thing and only these needs to be versioned and saved. But with Data Science code is just one part. It has two other major pillars to it. They are the Data (used by the code) and the Model (generated by the code and data).
So, think for a while if we are working on a ML model and we use different data and different stages to create different models. For example something as ChatGPT. It's developers will be using huge data which changes rapidly and create newer models. While in the process of creating new GPT models if the team kept on overwriting the code , data and models then what will happen? Suddenly if the newest model gives very bad outputs to customer queries then will there be a way to go back to previous code, model which was doing better? Or suppose the developer wanted to know a previous model was developed on which data , will there be a way to fetch that? If we were only using github then we only have the code but there is no way to link the model and data that was used to a previous model.
This is where DVC comes into picture. It works along with Git and brings in a feature to save and version the model and data with the code, making sure we can track all these three major parts anytime we want. This is what the Data Science world needed.
Basic steps of setting up and using DVC for ML project
Prerequisites
We need to have these installed in the system
STEP 1 : Initializing a project
git init
dvc init
The above two command inside the chosen directory initializes git and DVC in our project. Now we are ready to track our data and models.
STEP 2: Add a dataset to the project
Now suppose we have or create a folder named 'data' which has all the data in it. Use the below code to start tracking the folder.
dvc add data
This command creates a .dvc file (here it will be data.dvc) which stores information about the added folder/file. This acts as a placeholder for the original data for purpose of Git tracking. This step also adds the data to cache folder under .dvc folder
STEP 3: Remove from Git tracking if the file/folder is already tracked by Git
If the dvc add folder/file is already tracked by git then below code will help emove the tracking from it as data from now on will be tracked by dvc
git rm -r --cached 'data'
git commit -m "stop tracking data"
STEP 4: To start tracking changes with git
git add data.dvc .gitignore
git commit -m "Added data"
data.dvc is the data registry file and .gitignore file would include the data folder that is to be ignored by it's tracking system.
STEP 5: Storing and Saving
Now we have a registry of the data changes in .dvc file . It's time for data to be saved in remote. Before pushing data to a remote we need to set it up using below command. Data will be stored to this location from cache folder which dvc ha created in our local system. We can add any remote bucket here.
mkdir temp
dvc remote add -d myremote temp
STEP 6: Uploading Data
Now that a storage remote is configured we push the data to it.
dvc push
We would also want to Git track any code changes that lead to data change always (git add, git commit and git push).
To know the status of data tacking
Use the below command to check for status of data. If there is any modification. It is similar as git status.
dvc status
STEP 7: After any further changes to code
After this if any further changes are done to the data then use the below command
dvc commit
dvc status
dvc push
dvc commit will update the .dvc file to tack any changes by git. It also updates the cache folder under dvc. Also always after this we need to update Git to track the data registry and code changes(git add, git commit and git push)
Note: 'dvc add' seamlessly tracks datasets, models and large files by specifying the target that you want. As an alternative to it for data taht's already tracked, 'dvc commit' adds all the change to files or directories already tracked by the DVC without having to name each taget.
We can never underestimate the importance of versioning and with DVC and Git we are rest assured that everything in Data Science is tracked so that we neer have to say 'Wish I could go back and change'.
Sources:
Subscribe to my newsletter
Read articles from Debasis directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by