Feature Extraction in NLP
 Saurabh Naik
Saurabh Naik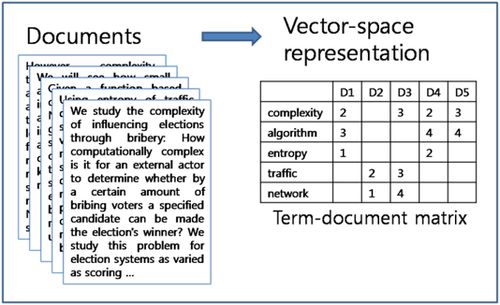
Introduction:
Natural Language Processing (NLP) is a fascinating field that involves the interaction between computers and human language. One crucial step in the NLP pipeline is feature extraction. It transforms raw text data into a format that machine learning algorithms can understand. Feature extraction is essential for building effective models in tasks like sentiment analysis, text classification, and language translation.
Techniques for Feature Extraction in NLP:
a) One-Hot Encoding
Intuition:
One-hot encoding represents each word in the vocabulary as a unique binary vector. Each vector has a length equal to the vocabulary size, with only one element set to 1 corresponding to the index of the word.
Example:
Consider the sentence: "Machine learning is fascinating." The one-hot encoding for this sentence would represent each unique word with a binary vector.
Python Code:
from sklearn.preprocessing import OneHotEncoder
corpus = ["Machine learning is fascinating."]
encoder = OneHotEncoder()
one_hot_encoded = encoder.fit_transform(corpus).toarray()
print("One-Hot Encoded Representation:")
print(one_hot_encoded)
Advantages:
Simple and easy to understand.
Preserve the uniqueness of each word.
Disadvantages:
High-dimensional sparse vectors can be computationally expensive.
Ignores word semantics and relationships.
b) Bag of Words (BoW)
Intuition:
The Bag of Words model represents a document as an unordered set of words, ignoring grammar and word order. It creates a frequency distribution of words in the document.
Example:
Consider the sentence: "NLP is transforming the world." The Bag of Words representation would count the occurrences of each word in the sentence.
Python Code:
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["NLP is transforming the world."]
vectorizer = CountVectorizer()
bow_representation = vectorizer.fit_transform(corpus).toarray()
print("Bag of Words Representation:")
print(bow_representation)
Advantages:
Simple and efficient.
Preserves word frequency information.
Disadvantages:
Ignores word order and semantics.
The resulting matrix can be large and sparse.
c) N-grams
Intuition:
N-grams are contiguous sequences of n items from a given sample of text or speech. In the context of NLP, these items are usually words.
Example:
For the sentence "NLP is transforming the world," the bigram representation would include pairs of consecutive words like ("NLP", "is"), ("is", "transforming"), and so on.
Python Code:
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["NLP is transforming the world."]
vectorizer = CountVectorizer(ngram_range=(1, 2))
ngram_representation = vectorizer.fit_transform(corpus).toarray()
print("N-gram Representation:")
print(ngram_representation)
Advantages:
Captures local word patterns.
Provides more context information.
Disadvantages:
Increases feature dimensionality.
Prone to data sparsity.
d) TF-IDF (Term Frequency-Inverse Document Frequency)
Intuition:
TF-IDF measures the importance of a word in a document relative to its frequency across multiple documents. It gives more weight to rare words that are distinctive to a document.
Example:
Consider two sentences: "Machine learning is fascinating" and "Natural language processing is fascinating." TF-IDF would assign higher weights to the word "Machine" in the first sentence and "Natural" in the second sentence.
Python Code:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ["Machine learning is fascinating.", "Natural language processing is fascinating."]
vectorizer = TfidfVectorizer()
tfidf_representation = vectorizer.fit_transform(corpus).toarray()
print("TF-IDF Representation:")
print(tfidf_representation)
Advantages:
Considers the importance of words.
Reduces the impact of common words.
Disadvantages:
Sensitive to document length.
May not capture word semantics effectively.
e) Custom Features
Intuition:
Custom features involve extracting specific information tailored to the problem at hand. These could include features like sentiment scores, part-of-speech tags, or domain-specific indicators.
Example:
For sentiment analysis, a custom feature could be the sentiment score of the document using a pre-trained sentiment analysis model.
Python Code:
from textblob import TextBlob
def custom_sentiment_feature(text):
blob = TextBlob(text)
return blob.sentiment.polarity
corpus = ["NLP is amazing!", "I dislike NLP."]
custom_features = [custom_sentiment_feature(text) for text in corpus]
print("Custom Features (Sentiment Scores):")
print(custom_features)
Advantages:
Tailored to the specific task.
Can capture domain-specific information.
Disadvantages:
Requires domain expertise for effective feature design.
May not be transferable to different tasks.
Conclusion:
Feature extraction is the cornerstone of NLP, translating raw text into a format suitable for machine learning models. Each technique discussed—One-Hot Encoding, Bag of Words, N-grams, TF-IDF, and Custom Features—has its unique advantages and disadvantages. The choice of technique depends on the specific requirements of the NLP task at hand. Experimenting with different methods and understanding the intricacies of each empowers data scientists to extract meaningful features and unlock the full potential of their NLP models.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com