Exploring RFA & Hashnode API
 Bernice Choy
Bernice Choy
As of Aug 2024, the
https://hashnode.com/rfapage andhttps://hashnode.com/api/ideasno longer exists.Hence, this article's resource is no longer relevant. RIP 🪦
The Why
How I stumble upon the idea
At the start of my technical blogging journey, I was patient (or crazy) enough to look through all the Request for Articles (RFA) to source ideas.
One of them was "A filter in RFA using tags and categories to find relevant requests".
My Motivation
This RFA caught my attention as the current means of looking through the RFA is to go through the infinite scrolling of pagination for a specific RFA post. Scrolling through once is fine, but subsequent search becomes cumbersome to do so.
For my convenience of viewing the full list of RFA without going through the infinite pagination, I decided to create a utility script to do just that. Also, this tinkering session becomes a ✨double activity✨ for me to explore the Hashnode API.
TL;DR
You can get the source codes and execute the script directly. Please refer to the README for setup instructions here
Caveats
I am using the session cookies stored in a file named
cookie.txt, which is a quick and dirty way to replicate the logon session 😬In the event you accidentally committed your session cookie file due to it not being named as
cookie.txt, please refer to the official Github documentation to terminate the current session(s)
Tool Overview
Objectives
I aim to implement the following features in my utility script
Retrieve RFA ideas
Retrieve tags of the submitted posts for RFA idea
- Count the frequency of tags used
Tech Stack
I will be sticking to what I am familiar with. Below is what I am using to create the utility script
NodeJS
Axios
Hashnode API
Implementation
Side Note
I started this experiment way back in May 2022 before going on hiatus for a prolonged period, there have been some changes
The previous endpoint I used was
https://hashnode.com/api/feed/rfa. When I got back to working on this experiment, it looked like the endpoint had been updated tohttps://hashnode.com/api/ideas.I will be using the new and current endpoint instead.
Emulate Logon
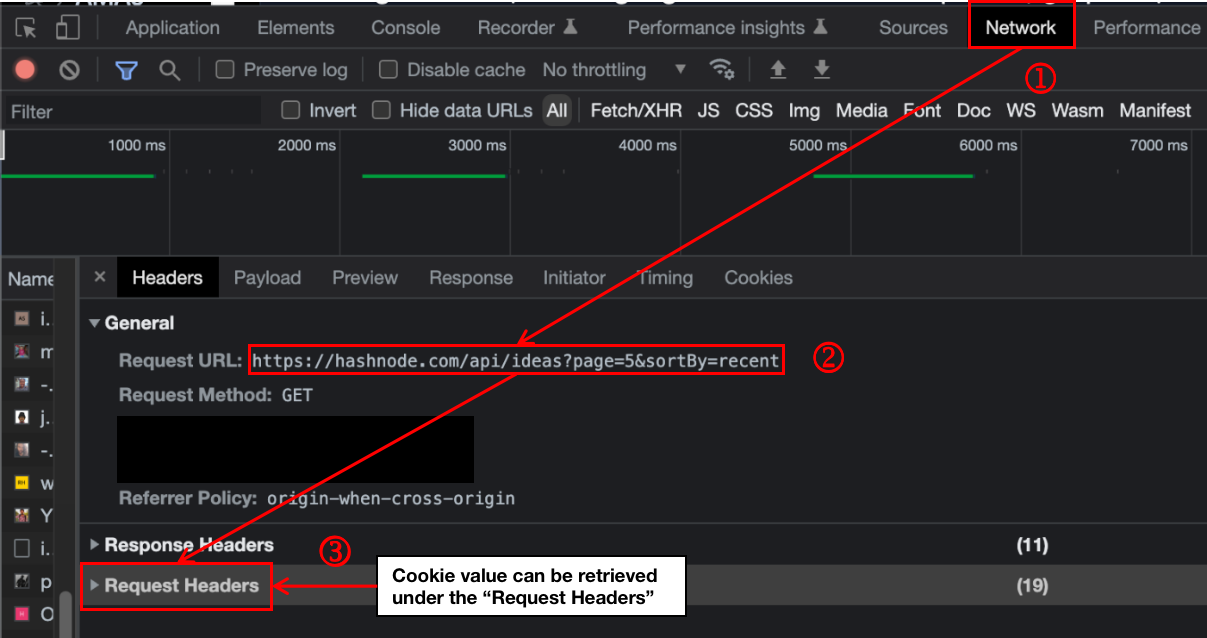
I am emulating logon by retrieving the value (hn-cookie-username) in the session cookie from the browser.
The session cookie will be stored in a file cookie.txt and its content will be loaded into the request header.
While it's probably the least ideal way, I didn't want to do anything too complicated since the scripts will be executed on my local machine.
Retrieving RFA ideas
The requests submitted by users are called ideas.
Initial Exploration I started by analysing the requests via the browser Developer console when accessing the URL https://hashnode.com/rfa.
You will only see a
GETrequest to/rfafor the initial request.As you scroll down the RFA page, you will start seeing requests being made to the endpoint https://hashnode.com/api/ideas?page=2&sortBy=recent as the ideas are being dynamically loaded to be displayed.
Observations & Considerations
- As I play around with different page numbers, e.g. https://hasnode.com/api/ideas?page=3&sortBy=recent, it seems that the next 10 ideas will be loaded for each pagination.
- Considering that I won't know the number of available pages, I decided to use recursion to iterate through the paginations until no items are detected for the particular page number.
Retrieve tags of the submitted posts for RFA idea
The JSON response returned from the endpoint will contain the respective RFA ideas and their submitted posts.
Observations & Considerations
I recognized the following patterns in the items in the response:
If a user has been deactivated, the
usernamefield will be null.Each article has a unique slug used to differentiate itself.
Users using the default Hashnode domain will have the following convention for their blog -
username.hashnode.devUsers that have custom domain names will be reflected in the domain field
Below is a sample of the submitted post in JSON format:
"publication": {
"domainStatus": {
"certIssued": true,
"ready": true
},
"_id": "SOME_RANDOM_IDENTIFIER",
"username": "USERNAME",
"domain": "CUSTOM_DOMAIN_NAME",
"urlPattern": "simple"
}
Using Hashnode API
From the submitted posts, you won't be able to find the tags. Hence, there is a need to rely on the Hashnode API to retrieve the article's associated tags.
As part of the Axios request to Hashnode API, I did a simple count and tracked the frequency of usage in a Map() object.
Hashnode API provides documentation regarding the schema and what can be queried. The query is in GraphQL format.
The general query format is
{
post(
slug: "<ARTICLE_SLUG>"
hostname: "<USER_HASHNODE_DOMAIN>"
) {
tags {
name
}
}
}
Example: I queried one of my previous articles
{
post(
slug: "dev-retro-2022-nuggets-of-wisdom"
hostname: "bernicecpz.hashnode.dev"
) {
tags {
name
}
}
}
It will show the following output for the associated tags

Artefacts
You can refer to the
sample-outputsfolder in the source code for the complete JSON results here
The utility script will save the outputs into JSON files as listed below:
ideas.json: The list of RFA ideas and their submitted posts, along with the associated tags. Sort the RFA idea by upvotes in descending ordertags.json: The tags used for the submitted posts and the number of times it is used, in descending order

Formatting outputs
The content of the JSON file may get too big to be formatted within an IDE (e.g. Visual Studio Code). You may need to rely on the command line to do so.
For Linux/MacOS You can use the CLI jq to format the JSON file via vim vi
# Go into vim editor mode
vi <filename.json>
# Use jq to format the JSON
:$!jq .
# Save and quite
:wq
For Windows, you can use PowerShell to format the JSON file.
# You can do a in-place formatting by referring to the JSON file itself when you use Set-Content
# -Depth option is required to allow the formatting to parse through the nested levels
Get-Content <filename.json> | ConvertFrom-Json | ConvertTo-Json -Depth 100 | Set-Content <filename.json>
Food for Thought
Observations
From the tags, it seems like there is a notable inclination of readers wanting to find out more about
Programming languages such as JavaScript, Python and Node.js
Front-end development for both mobile and web
- Frameworks such as React and Flutter
Miscellaneous topics ranging from challenges to general advice

Caveats
As an article can be added to multiple RFA ideas, there may be duplicated submitted posts across the RFA ideas.
Similarly, multiple tags can be added to the article. Hence, there is likely to be double counting for tags as well.
I was doing some sampling to test the article's URL validity. Some pages would return 404, indicating that they may have been removed. I verify the article URL by referring to the user's domain sitemap for comparison.
Conclusion
Perhaps I have taken too long to conceptualise and develop this utility script. It feels like not many people are utilising the RFA space very often anymore, due to little changes in the generated outputs.
This is especially true, now that we have Hashnode Discussion. It's much livelier there 🙃 Furthermore, there is a revamp in Hashnode's API.
While I didn't exactly create a filtering mechanism, it's an interesting tinkering session to pull information to find out the general interest in the type of articles that are sought after.
Hope you have a good read for this, look forward to the next one!
Cheers! 🍻
Subscribe to my newsletter
Read articles from Bernice Choy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bernice Choy
Bernice Choy
A fledgling engineer dabbling into areas of DevOps, AWS and automation. I enjoy tinkering with technology frameworks and tools to understand and gain visibility in the underlying mechanisms of the "magic" in them. In the progress of accumulating nuggets of wisdom in the different software engineering disciplines!