Hashing It Out: Understanding the Magic of Hashtables
 Wiseman Umanah
Wiseman Umanah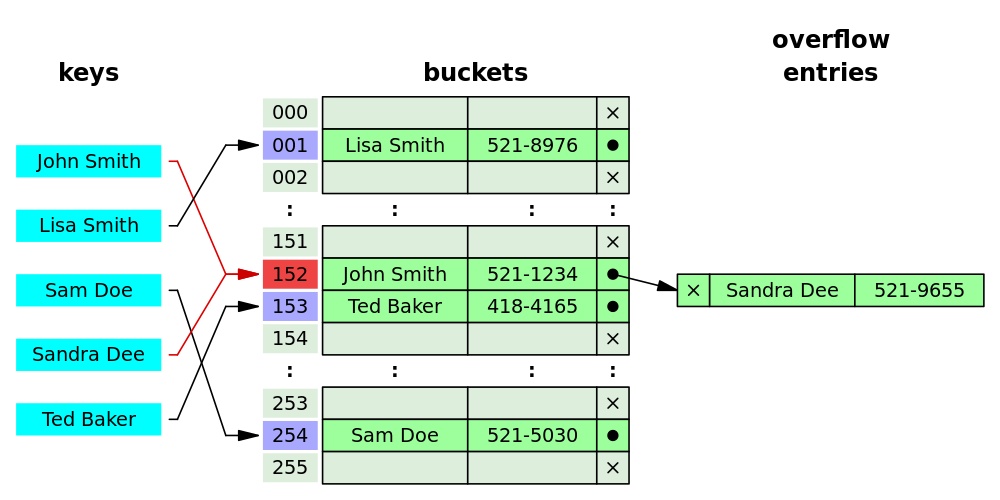
Introduction
One of the most interesting data structures I have come to love in C language is the Hash table. This ingenious data structure offers a robust framework for organizing and categorizing data, relying on intricate algorithms to achieve this precision. Python, a language renowned for its elegance, adopts the Hash Table to power its dictionary implementations, exemplifying the data structure's versatility and efficiency.
Understanding Hash Tables
At its core, a Hash Table is an array strategically augmented with linked lists. These linked lists serve as containers, each holding data that share a unique relationship defined by a carefully crafted algorithm. The key strength of Hash Tables lies in their ability to swiftly locate and manipulate data, making them indispensable in a multitude of applications.
Hashing Algorithms
A pivotal aspect of Hash Tables is the process of obtaining an index for each piece of data, commonly known as a key. This crucial task is accomplished through Hashing Algorithms. Among the myriad algorithms, the djb2 algorithm stands out, its elegance and efficiency rendering it a popular choice. By employing the djb2 algorithm and subsequently calculating the modulus of the resulting hash value, Hash Tables efficiently assign indices to data, ensuring rapid access and retrieval. For this article, we will use the djb2 algorithm which was invented by Daniel J. Bernstein, a renowned computer scientist. Another algorithm can be used by calculating the total of the ASCII value of each element and obtaining the modulus of the value from the table size. Let's see our to implement this algorithm.
/*Using the djb2 algorithm and getting the hashtable
The djb2 Algorithm
*/
unsigned long int hash_djb2(const unsigned char *str)
{
unsigned long int hash;
int c;
if (str == NULL)
return (0);
hash = 5381;
while ((c = *str++))
{
hash = ((hash << 5) + hash) + c; /* hash * 33 + c */
}
return (hash);
}
/*Obtaining the Index for the key-value of the element*/
unsigned long int key_index(const unsigned char *key, unsigned long int size)
{
unsigned long int value;
if (key == NULL)
return (0);
value = hash_djb2(key);
value = value % size;
return (value);
}
With the value gotten after the function above we can easily position our key-value anywhere in our hashtable without issues.
Defining the Hash Table
Let's look at how we can create the hashtable so that we can use it to logically store our value. Everything we will do here will work with us dynamically allocating memory and successfully controlling every activity that the system will take on our hashtable.
#ifndef HASH_TABLES
#define HASH_TABLES
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/**
* struct hash_node_s - Node of a hash table
*
* @key: The key, string
* The key is unique in the HashTable
* @value: The value corresponding to a key
* @next: A pointer to the next node of the List
*/
typedef struct hash_node_s
{
char *key;
char *value;
struct hash_node_s *next;
} hash_node_t;
/**
* struct hash_table_s - Hash table data structure
*
* @size: The size of the array
* @array: An array of size @size
* Each cell of this array is a pointer to the first node of a linked list,
* because we want our HashTable to use a Chaining collision handling
*/
typedef struct hash_table_s
{
unsigned long int size;
hash_node_t **array;
} hash_table_t;
Having a well-structured header file like this will be necessary for easy visualization. This is optional, you can do all your coding in one file but having a separate header will make reading easy. We use structures to group this data, to understand what is structure I recommend you read this article Structures in C. hash_node_t **array is the pointer to the array that contains the linked list, we also define unsigned long int size this is to keep track of the array size anywhere during the execution of our program.
Initialization of Hash Table
After the definition of our hashtable, initializing it is another process. I mean what will be the point of defining it without using it 😂. With our well-defined hash table, initialization will just be cake to us.
#include "hash_tables.h"
hash_table_t *hash_table_create(unsigned long int size)
{
hash_table_t *arr;
unsigned int i;
arr = malloc(sizeof(hash_table_t));
if (arr == NULL)
return (NULL);
arr->size = size;
arr->array = malloc(sizeof(hash_node_t *) * size);
if (arr->array == NULL)
{
free(arr);
return (NULL);
}
for (i = 0; i < size; i++)
arr->array[i] = NULL;
return (arr);
}
We dynamically allocate memory to create a hash table with malloc having the size of the hash table structure. The size of the hashtable is stored in arr->size and memory is allocated for each contain of the array i.e. each element of the array is a structure (linked list in this case). You can use calloc in this case, but I manually allocate memory to the array elements so that we all understand what is happening here. If you don't understand what I mean by dynamic memory allocation, you can read this helpful article, Dynamic Memory Allocation. Every member of the array is then initialized to NULL, this is so that the array elements don't point to a garbage value in the computer memory. Also, note that we constantly check for failures if the memory wasn't allocated successfully to avoid program crashes or unwanted behaviour. Finally, we return the arr, to be used in other programs.
Setting Keys in the Array
Once the array is successfully created, we can then start storing values based on the hash value of their keys in our array. This is where our djb2 algorithm comes to play an important role in obtaining the index for the value in the array. Let's dive in 😊
#include "hash_tables.h"
hash_node_t *createNode(const char * key, const char *value);
int hash_table_set(hash_table_t *ht, const char *key, const char *value)
{
unsigned int num, count;
hash_node_t *new_node, *curr;
num = key_index(key, ht->size);
curr = ht->array[num];
if (curr != NULL)
{
while (curr != NULL)
{
if (strcmp(curr->key, key) == 0)
{
free(curr->value);
curr->value = malloc(strlen(value) + 1);
strcpy(curr->value, value);
return (1);
}
curr = curr->next;
}
new_node = createNode(key, value);
if (new_node == NULL)
return (0);
new_node->next = ht->array[num];
ht->array[num] = new_node;
}
else
{
new_node = createNode(key, value);
if (new_node == NULL)
return (0);
new_node->next = ht->array[num];
ht->array[num] = new_node;
}
return (1);
}
hash_node_t *createNode(const char * key, const char *value)
{
hash_node_t *new_node;
new_node = malloc(sizeof(hash_node_t));
if(new_node == NULL)
return (NULL);
new_node->key = malloc(strlen(key) + 1);
new_node->value = malloc(strlen(value) + 1);
if (new_node->key == NULL || new_node->value == NULL)
return (NULL);
strcpy(new_node->key, key);
strcpy(new_node->value, value);
return (new_node);
}
Looks pretty long right 😂, yeah this is us handling some test cases in our program which we will discuss later in the article. The function createNode is very easy to understand, all we did there was to create a new node to be stored in our array.
Question: Hey, why don't you write both functions as one why break it to two functions?
Answer: My coding style follows a system called Betty coding style, this is for simplicity and readability.
For the other function, let me start by explaining the test cases. This will make you understand what is happening there.
The function checks if an index in the array is empty which of course should create a new node in the array if it is empty. That's easy right 😊
But what if it's not empty 😱, we add the new node to the beginning of the linked list.
Before adding a new node, what if we have two keys that are the same? We have to check the linked list and update the value if necessary
After all the test cases have been passed successfully, we return "0" for success. If we encounter any issue during execution, "1" is returned for error.
What Did We Store??
We created a function that can store values in a hash table based on their keys, but how can we see what we have stored in the has table? Let's write a simple function that will do that for us.
#include "./hash_tables.h"
/**
* hash_table_print - Prints hash table.
* @ht: A pointer to hash table to print.
*
* Description: Key/value pairs are printed in the order
* they appear in array of the hash table.
*/
void hash_table_print(const hash_table_t *ht)
{
hash_node_t *node;
unsigned long int i;
unsigned char comma_flag = 0;
if (ht == NULL)
return;
printf("{");
for (i = 0; i < ht->size; i++)
{
if (ht->array[i] != NULL)
{
if (comma_flag == 1)
printf(", ");
node = ht->array[i];
while (node != NULL)
{
printf("'%s': '%s'", node->key, node->value);
node = node->next;
if (node != NULL)
printf(", ");
}
comma_flag = 1;
}
}
printf("}\n");
}
This function will print the elements of the array in a style "key": "value" just like we have in the Python dictionary. That's why before I started, I said something about how Python dictionaries are formed and printed since Python language was created with C language. The comma flag is temporary to check if we have reached the end of the array to stop printing ,. That's it 😊, straightforward.
I Need What I Stored Back 😡
Well so far we cannot retrieve what we stored in the array and that's not nice. We need to be able to get the value we stored to use it subsequently for another program if we have any program that will make use of the value. Knowing the key, how can we get its value without even knowing the index? Tricky right 😂. Remember our djb2 algorithm and the key_index function, that's how we know the index of the array where to find the value of the key.
#include "hash_tables.h"
char *hash_table_get(const hash_table_t *ht, const char *key)
{
hash_node_t *current;
unsigned long int index;
index = key_index(key, ht->size);
current = ht->array[index];
while (current != NULL)
{
if (strncmp(current->key, key, strlen(key)) == 0)
return(current->value);
current = current->next;
}
return (NULL);
}
Once we have the index, we then find the value in the array. If the key was found we returned the value of the key, if it was found, we returned NULL to show that the key wasn't found or doesn't exist.
Memory! Memory!! Memory!!!
So far we have used a certain amount of computer memory for our program, it's time we tell the computer "Hey, I'm done with this memory let's free it". This aspect of the program is crucial whenever memory is dynamically allocated in a program it must be freed after use. Let's free it 😊
#include "hash_tables.h"
void hash_table_delete(hash_table_t *ht)
{
hash_node_t *current, *temp;
unsigned long int i;
for (i = 0; i < ht->size; i++)
{
if (ht->array[i] != NULL)
{
current = ht->array[i];
while (current != NULL)
{
temp = current;
current = current->next;
free(temp->key);
free(temp->value);
free(temp);
printf("%p %p\n", current, temp);
}
}
}
free(ht->array);
free(ht);
}
Let me take you on a walkthrough of what is happening here:
We have a loop that moves through all the elements of the array's linked list
We free memory allocated to key and value for each linked list
The member of the array is the freed
The array itself is freed and finally;
The hash table is freed. All taking a systematic method just the same way we dynamically allocated the memory. This is to avoid memory leaks after execution.
What Next? 🤔
All our functions are now ready to be executed in the main function of our program. A simple main function can add a key : value to a created hashtable and delete it after you are done with it. Don't forget to add all function prototypes in your header file.
The code can be compiled using these flags (this is optional):
gcc -Wall -Werror -Wextra -pedantic -std=gnu89 *.c -o {filename output}
Why Use Hash Tables
Hash tables are fundamental data structures in computer science with various applications due to their efficiency and speed in data retrieval and insertion. Here are some compelling reasons why hash tables are essential:
1. Fast Data Retrieval: Hash tables provide constant-time average-case complexity for search, insert, and delete operations. This means that these operations are incredibly fast and not dependent on the size of the data set.
2. Efficient Data Insertion and Deletion: Hash tables allow for efficient insertion and deletion of data. When inserting data, the hash function calculates the index where the data should be stored, and when deleting, the data can be quickly located and removed.
3. Key-Value Storage: Hash tables store data in a key-value pair format. This makes it ideal for applications where data needs to be associated with specific keys, such as dictionaries in programming languages.
4. Optimal for Database Indexing: Databases use hash indexes to optimize search operations. Hash indexes allow databases to find data records quickly, speeding up query performance.
5. Collision Resolution: Hash tables have techniques like chaining and open addressing to handle collisions (situations where two keys hash to the same index). This ensures that data is not lost and can be efficiently retrieved even if collisions occur.
6. Efficient Memory Usage: Hash tables can be memory-efficient because they dynamically resize, ensuring that memory is allocated efficiently as the size of the data set changes.
7. Used in Algorithms and Data Structures: Hash tables are used in various algorithms and data structures. For example, hash tables are the backbone of many search algorithms and are utilized in graph algorithms for efficient storage and retrieval of graph nodes and edges.
8. Caching Mechanisms: Hash tables are used in caching mechanisms to store recently accessed data. By storing frequently accessed data in a hash table, systems can reduce the time it takes to retrieve information.
9. Implementing Sets and Dictionaries: Hash tables are often used to implement sets and dictionaries in programming languages. Sets and dictionaries are fundamental data structures used in algorithms and applications.
In summary, hash tables are indispensable tools in computer science and software engineering due to their efficiency, versatility, and wide range of applications. They enable fast data access, and efficient memory usage, and are utilized in various fields, making them essential for developers and computer scientists.
If you find this article very useful, please share and subscribe for more articles 😊🚀🚀
Subscribe to my newsletter
Read articles from Wiseman Umanah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Wiseman Umanah
Wiseman Umanah
I'm WIseman Umanah, a developer 💻️ who loves to share my knowledge and experiences with others and I'm always looking for ways to improve my skills and learn new things. When I'm not working, you can find me drawing as an artist 🤗😀.