Tables & Keys
 Deon Slabbert
Deon Slabbert
Now that we know about data design and how data in different containers relate to each other via foreign keys, let's look at relational databases and start calling things by their correct names.
Please note that everything you will learn here applies to all relational database management systems (RDBMS). Examples of relational database management systems are PostgreSQL, MySQL, MariaDB, Microsoft SQL Server, SQLite, Oracle Database, Apache Derby, H2, DB2, and Microsoft Access to name a few. Some of them are commercial applications and need to be paid for while others are open source and thus free to use. We will focus on the latter.
RDBMS
In previous posts, we used a spreadsheet application such as Microsoft Excel or Google Sheets to build our Employee database.
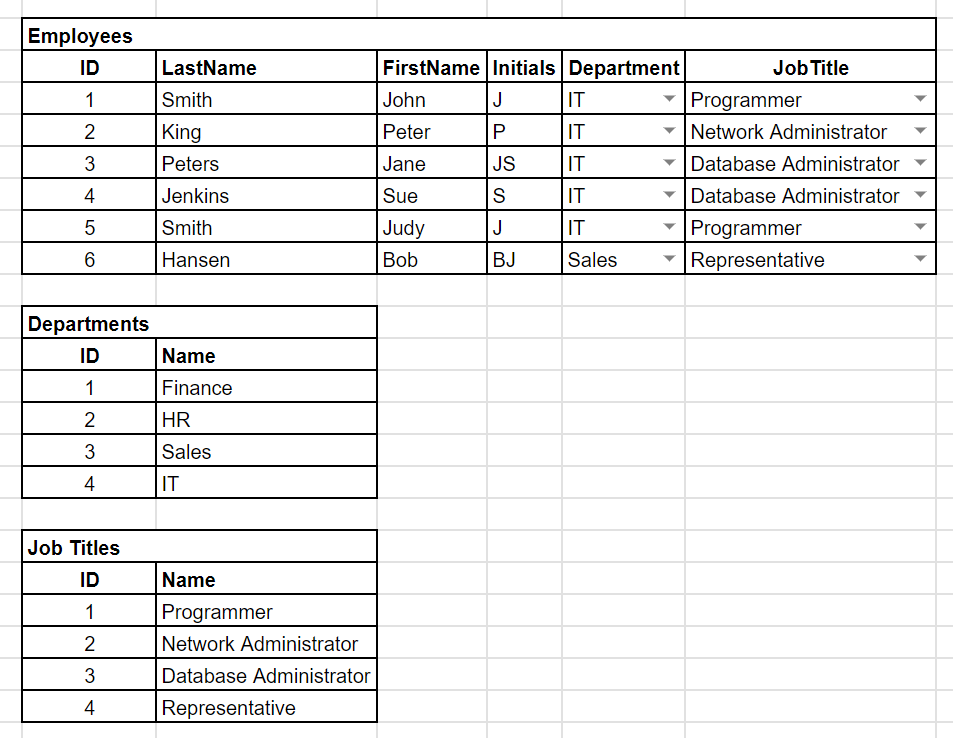
In the example above we have three collections of data to deal with, namely Employees, Departments, and Job Titles. This is manageable for now, but what if we need to deal with tens or hundreds of collections of data? This is where the mighty spreadsheet fails us. Even if we use a multi-sheet spreadsheet and move each collection of data to its own sheet, it will let us down rather sooner than later.
It's not the spreadsheet's fault. It's ours! We are using an application for a purpose it never was designed for. This is where the Relational Database Management System (RDBMS) comes to the rescue.
A Relational Database Management System is an application that is purpose-built to manage your database for you. Please note that, technically, the RDBMS is not the database. It is the engine that manages your database.
The RDBMS:
creates your database
inserts new data into your database
updates existing data in your database
deletes existing data from your database
queries your data
protects the integrity of your data
backup your database
restore your database
and many more
The bottom line is that, without an RDBMS, your database is pretty much useless.
SQL
To do all these data manipulation and data queries mentioned above, we use a domain-specific language (DSL) called SQL. The purists pronounced it as 'Ess-cue-ell' and the rest of us say 'sequel'. There are even rumors that SQL is short for Structured Query Language but that can be neither confirmed nor denied.
The good news though is, that once you know SQL, you can pretty much communicate with any relational database under the sun. You will learn SQL once we start using an RDBMS, which is probably two or three posts away.
Tables
In our Employee database, we have three collections or clusters of data. In RDBMS terms we will store these clusters of data in Tables (also called Relations). We will use the term Table as it is not really used anywhere except to tell people that the other term for Table is Relation.
So, after we have created an Employee database with the help of our RDBMS, we will create three tables:
Employee,
Department, and
Job Title.
Columns
Each table will have some Columns (also called Attributes). The term Column is used more than Attribute so we will also use Column. Each column contains a piece of data related to the Table it is in. We will create the following columns:
The Employee Table has the following columns:
ID (primary key)
Last Name
First Name
Initials
Department ID (foreign key)
Job Title ID (foreign key)
The Department Table has the following columns:
Department ID (primary key)
Department Name
The Job Title Table has the following columns:
Job Title ID (primary key)
Job Title Name
It is important to note that each Table has a Primary Key that uniquely defines each row.
Rows
Each time, we add a new employee to our Employee table, the RDBMS will save the new employee data in a new row. Thus if we have 10 employees, we will have an Employee table with 10 rows. Each row holds the ID, Name, Department, and Job Title of a different employee.
Two other terms that are used when referring to rows in a database table are Records and Tuples. The term Record is used quite often whereas the term Tuple is not used that much.
Keys
| ID | Employee Code | Last Name | First Name | Identity Number |
| 101 | FIN001 | Smith | John | 1234567890 |
| 102 | MRK001 | Jenkins | Peter | 2345678901 |
| 103 | ICT001 | Conner | John | 3456789012 |
| 104 | FIN002 | Smith | Will | 4567890123 |
| 105 | MRK002 | Smithers | James | 5678901234 |
Candidate Keys
Remember what we have mentioned a few times now. Each row in a table must be unique. Thus, we cannot have two identical rows in a table. Technically you can, but trust me, you don't want to. With that said, let's look at the above table and see how we can ensure that each row is unique.
Each row has a unique ID. Each row has a unique Employee Code, The Last Name and First Names rows are not unique as we have two employees with the last name Smith and we have two employees with the first name John. The Identity Number again is unique.
If we combine columns, we see that the ID + Employee Code combination is unique. So is the ID, Employee Code, and Last Name combination. So is the ID, Employee Code, Last Name, and First Name combination. So is the ID, Employee Code, Last Name, First Name, and Identity Number combination. And so is the ID and Identity No combination. You get the picture...
Although the ID, Employee Code and Identity Columns always seem to be unique, it cannot be guaranteed for the first and last names. So, to play it safe, we seem to have three candidate keys:
ID,
Employee Code, and
Identity No.
It is from these three columns that we need to pick a primary key that will represent each row in the table.
The ID column seems to be just a numeric number that auto-increments with each new employee.
The Employee Code turns out to be a code manually allocated by HR to go on the employee's name badge. The first three letters indicate the department where the employee works (FIN for Finance, ICT for IT, MRK for Marketing). Although this code is unique for now, there is no guarantee that somebody is not going to make a boo-boo that ends up with duplicates in the table. There is also the possibility that the employee code may be changed to a different format in the future.
Upon investigation, we learn that the Identity Number is a government-issued number for each citizen. Although, it is a unique number controlled by the government, what do we do if a foreigner, joins the company? There will be no identity number for that employee.
Primary Keys
It is safe to say that the ID column, which is just a numeric value, is the best candidate key to use as a primary key.
Foreign Keys
As we have seen in previous posts, the primary key of one table can be used as a foreign key in another table, thus providing a link between tables. Doing things this way eliminates the anomalies we discussed in a previous post and contributes to good data design.
Conclusion
Once again, we have progressed a little further into our database journey. I try to keep things simple and easy to understand for the plain reason that for many of you, it will be the first time you learn this stuff. Over time things will become a little less easy but hopefully still simple.
Our next stop is Database Naming Conventions, where we will look at best practices when it comes to naming database constructs. After that, we will start using actual relations database management systems. See you there!
Subscribe to my newsletter
Read articles from Deon Slabbert directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Deon Slabbert
Deon Slabbert
I am a fullstack software developer with 35 years experience building enterprise applications for the financial sector and have a passion for learning & teaching others the tools of the trade