Using Nested Set Model to Build Hierarchical Data
 Simon Asika
Simon Asika
I've been using the Nested set model for a while in Windwalker Framework, as it's built into its core ORM package. However, I realized that there isn't much discussion about this model in the dev community.
The Nested set model is a data model designed for efficiently handling tree node structures. It allows us to retrieve nodes, calculate node counts, or load whole tree data without traversing the entire tree.
About Traditional Adjacency List Model
First, let's discuss the traditional design for handling nested structures, using a data table that contains a parent_id for its tree structure.
Table: `tree`
| id | parent_id | title |
|----|-----------|-------|
| 1 | 0 | ROOT |
| 2 | 1 | four |
| 3 | 1 | node |
| 4 | 2 | node |
| 5 | 2 | node |
| 6 | 3 | node |
As we can see, each record has a parent_id pointing to its parent node. To retrieve child nodes, an SQL query would look like this:
SELECT * FROM `tree` WHERE `parent_id` = 1;
This method is straightforward and easy to understand. However, its downside is evident when trying to fetch multi-level data or calculate the number of nodes, as it requires recursive operations, heavily burdening the database.
Solution: Nested Set Model
The Nested Set Model is an excellent solution to this issue.
Let's examine the tree structure of the Nested set model. Each node has a left and right key, usually named lft and rgt. Assume we start with a root node A:
A (1,2)
When we add a node B under A, it changes to:
A (1,4)
|
|
B (2,3)
Then, adding a node C:
A (1,6)
|
---------------
| |
B (2,3) C (4,5)
Clearly, the left and right keys of B and C are wrapped within A. To retrieve B and C, an SQL query would be:
-- Assuming a typical workflow, we might first
-- retrieve A's data using ORM
SELECT * FROM `tree` WHERE `id` = 1;
-- Then, using A's lft and rgt to query all children
SELECT * FROM `tree` WHERE `lft` > 1 AND `rgt` < 6
-- To include A, add equals sign
SELECT * FROM `tree` WHERE `lft` >= 1 AND `rgt` <= 6
-- This approach can implementable in any programming language
The advantage here is evident, using lft and rgt keys, we can easily retrieve whole children nodes. Refer to the following image:
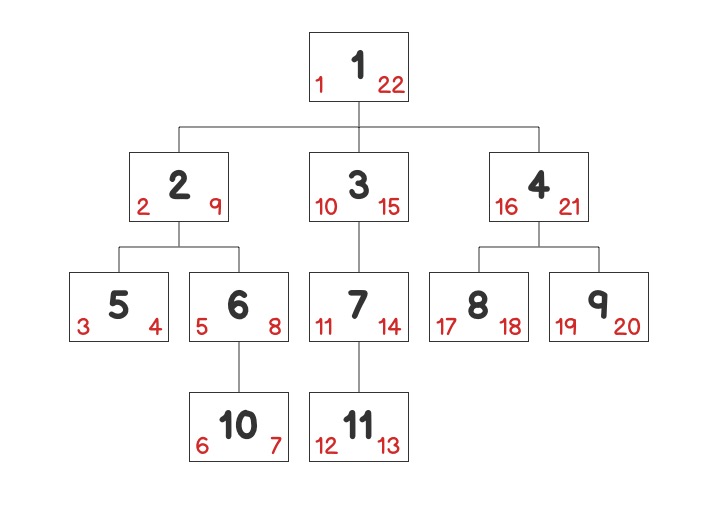
Using lft > 1 AND rgt < 22, we can retrieve all nodes at once, whereas the traditional adjacency list model might require up to 5 queries to fetch or calculate all child nodes.
Initializing a Tree
Now, let's dive into some real-world examples.
A key point of Nested set is to always have a root node, which is the starting point for all nodes and generally not used. Initially, we need to create a table with parent_id, lft, rgt. The parent_id is used for upward queries. Additionally, to easily control query levels, we can add a level column to track the current level.
Initializing a category table:
| id | parent_id | title | lft | rgt | level |
|----|-----------|-------|-----|-----|-------|
| 1 | 0 | ROOT | 1 | 2 | 1 |
Here's a simple creation syntax:
CREATE TABLE IF NOT EXISTS `categories` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`parent_id` int(10) UNSIGNED NOT NULL DEFAULT '0',
`lft` int(11) NOT NULL DEFAULT '0',
`rgt` int(11) NOT NULL DEFAULT '0',
`level` int(10) UNSIGNED NOT NULL DEFAULT '0',
`title` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_left_right` (`lft`,`rgt`)
) DEFAULT CHARSET=utf8;
INSERT INTO `categories` VALUE (1, 0, 'ROOT', 1, 2, 1);
Preparing Example Data
Here, we prepare some example data, including category and article tables:
Category
| id | parent_id | title | lft | rgt | level |
|----|-----------|-------|-----|-----|-------|
| 1 | 0 | ROOT | 1 | 10 | 1 |
| 2 | 1 | A | 2 | 7 | 2 |
| 3 | 2 | B | 3 | 4 | 3 |
| 4 | 2 | C | 5 | 6 | 3 |
| 5 | 1 | D | 8 | 9 | 2 |
Articles
| id | title | catid |
|----|------------|-------|
| 1 | Article 1 | 1 |
| 2 | Article 2 | 2 |
| 3 | Article 3 | 3 |
| 4 | Article 4 | 3 |
| 5 | Article 5 | 4 |
| 6 | Article 6 | 5 |
Some Simple Query Examples
Retrieve all articles under all categories of A (very useful for blog categories):
SELECT `a`.*, `b`.*
FROM `articlea` AS `a`
LEFT JOIN `categories` AS b ON `a`.`catid` = `b`.`id`
WHERE
`b`.`lft` >= 2 AND `b`.`rgt` <= 7
-- OR
`b`.`lft` BETWEEN 2 AND 7
Limiting Levels:
SELECT `a`.*, `b`.*
FROM `articles` AS `a`
LEFT JOIN `categories` AS b ON `a`.`catid` = `b`.`id`
WHERE
`b`.`lft` >= 2 AND `b`.`rgt` <= 7
AND
`b`.`level` < 2
Reverse Query to Find All Ancestors of Node B:
SELECT `categories`.*
FROM `categories` AS `node`, `categories` AS `parent`
WHERE
`node`.`lft` BETWEEN `parent`.`lft` AND `parent`.`rgt`
AND `node`.`id` = 3
Adding a Node Before B:
-- First, make room, all rgt, lft + 2
UPDATE `categories` SET
`rgt` = `rgt` + 2,
`lft` = `lft` + 2
where
`lft` > 2
-- Then insert the node
INSERT INTO `categories` VALUE (:id, 'New Article', 2, 3, 4, 3);
This approach can be easily implemented in any language.
Extending Neste Set Model
Generally, only the parent_id, lft and rgt are required fields in Nested Set Model. Furthermore, additional fields can be added to extend various functions. For example, in this article, we add level to control the node levels. Some implementation will add an alias and path field, which looks like parent/parent2/child/child2. This is useful in the application itself for quickly comparing node levels.
You may also create a Multi-Tree Neseted Set Table, Just add a root_id or master_id to hold the ROOT node ID for every node, then adding this where control to every query:
WHERE `root_id` = :rootId
that you can limit every read / write operation under a root node.
Conclusion
Nested set model has pros on the loading and retrieving performance. However, the downside is that adding or moving nodes requires traversing the entire tree to rebuild the index, which is not very efficient.
For general applications, it's like trading back-end storage operation performance for front-end reading performance, which is also a solution in high-traffic systems.
Related Links
Subscribe to my newsletter
Read articles from Simon Asika directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by