Understanding ReLU, LeakyReLU, and PReLU: A Comprehensive Guide
 Juan Carlos Olamendy
Juan Carlos Olamendy
Why should you care about ReLU and its variants in neural networks?
In this tutorial, we'll unravel the mysteries of the ReLU family of activation functions, which are pivotal in modern neural network architectures.
Activation Functions
Before delving into ReLU, let's understand what an activation function is and its role in a neural network.
Role in Neural Networks
An artificial neural network, akin to the human brain, comprises interconnected nodes or artificial neurons.
These networks are adept at solving complex problems like image classification.
At its core, each neuron uses an activation function to compute its output based on inputs and weights.
Activation functions can be linear (e.g., f(x)=αx) or non-linear (e.g., sigmoid function).
Non-linear functions are crucial for tackling real-world problems with intricate feature relationships.
Common Activation Functions
In the realm of neural networks, several activation functions are commonly used.
Linear: The identity function f(x)=x is a basic linear activation, unbounded in its range.
ReLU: Standing for rectified linear unit, ReLU is a widely-used non-linear function.
Sigmoid: This function outputs values between 0 and 1, ideal for probability-based models.
Tanh: The tanh function outputs values between -1 and 1, effectively mapping negative inputs to negative outputs.
Limitations of Sigmoid and Tanh
Sigmoid and tanh functions, however, face challenges during model training, particularly the vanishing and exploding gradient problems.
Gradient Problems
Vanishing Gradient
Here, gradients become minuscule, hindering weight updates and learning.
The vanishing gradient problem is a significant challenge encountered in training deep neural networks, particularly those using gradient-based learning methods and backpropagation.
As the gradient is backpropagated, it gets multiplied by the derivative of the activation function at each layer. If these derivatives are small (less than 1), multiplying them repeatedly for many layers causes the gradient to diminish exponentially as it reaches the earlier layers.
When the gradient becomes very small, the updates to the weights in the earlier layers of the network become insignificant. This means these layers learn very slowly, or not at all, hindering the network's ability to capture complex patterns, especially those represented by the data processed in the earlier layers.
The vanishing gradient problem is particularly pronounced in deep neural networks with many layers.
Exploding Gradient
Conversely, large gradients can destabilize the model, preventing learning.
The exploding gradient problem occurs when the gradients during backpropagation become excessively large. This can happen due to several reasons, such as improper initialization of parameters, inappropriate learning rate, or issues in the network architecture.
ReLU Activation
Now, let's focus on the ReLU function and its characteristics.
Basic ReLU
ReLU is efficient and avoids vanishing/exploding gradient issues but suffers from the dying ReLU problem, where negative inputs lead to inactive neurons.
ReLU helps mitigate the vanishing gradient problem because the gradient is either 0 (for negative inputs) or 1 (for positive inputs). This ensures that during backpropagation, the gradients do not diminish exponentially as they would with sigmoid or tanh functions.
The Dying ReLU Problem:
Cause: The dying ReLU problem occurs when neurons only receive negative input. When this happens, the output of the ReLU function is zero. As a result, during the backpropagation process, there is no gradient flowing through the neuron, and its weights do not get updated.
Impact: Once a ReLU neuron gets stuck in this state where it only outputs zero, it is unlikely to recover. This is because the gradient through a neuron is zero when its output is zero. Consequently, the neuron becomes inactive, essentially 'dying', and ceases to play any role in discriminating the input.
Resulting Issues: If many neurons in a network 'die', it can lead to a substantial loss of capacity in the network, and the network may fail to fit or generalize the data properly. This is especially problematic in deeper networks with many layers.
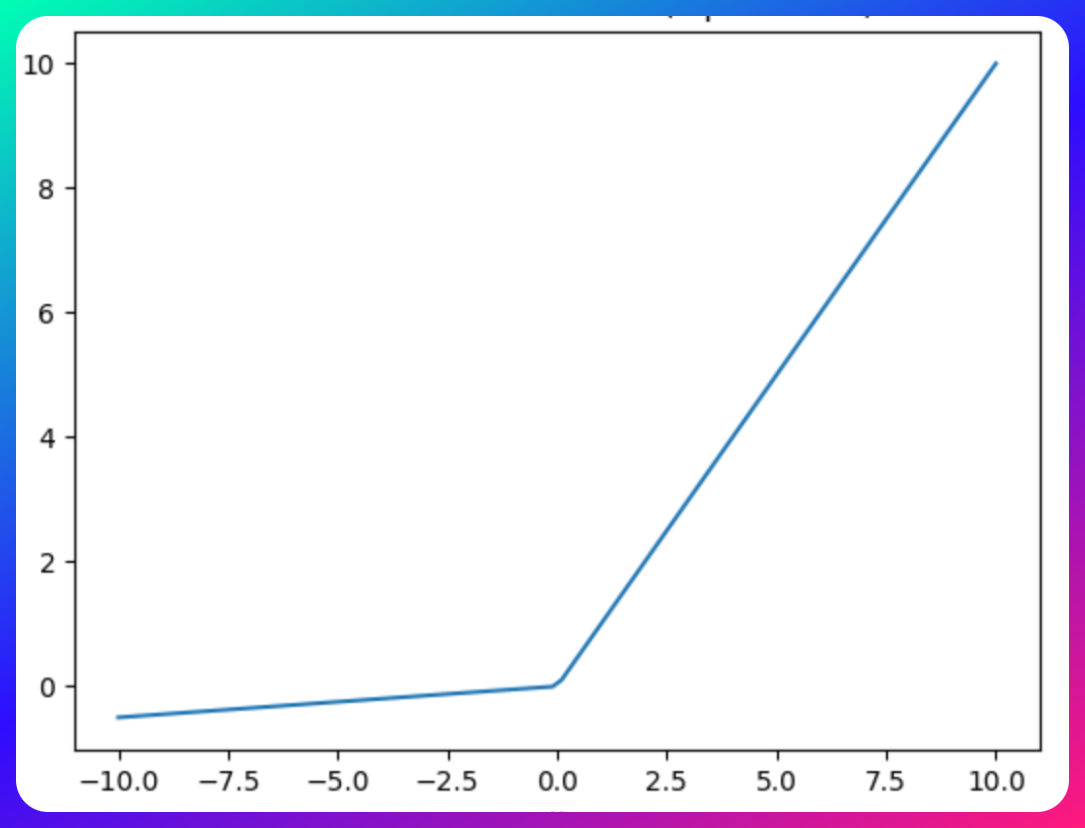
Leaky ReLU
To mitigate the dying ReLU problem, Leaky ReLU introduces a small gradient for negative inputs, preserving some activity in the neurons.
However, it struggles with consistency for negative inputs, using a fixed slope throughout training.
When implementing Leaky ReLU, it’s important to experiment with adjusting the learning rate, along with regular evaluations. This can help in determining the optimal configuration for Leaky ReLU in a given neural network.
In summary, Leaky ReLU is a valuable tool in the neural network toolkit, especially for addressing the limitations of the ReLU function.
Its ability to maintain a gradient flow through negative inputs makes it a popular choice for deep neural network models, though careful consideration is needed regarding the choice and handling of the parameters.
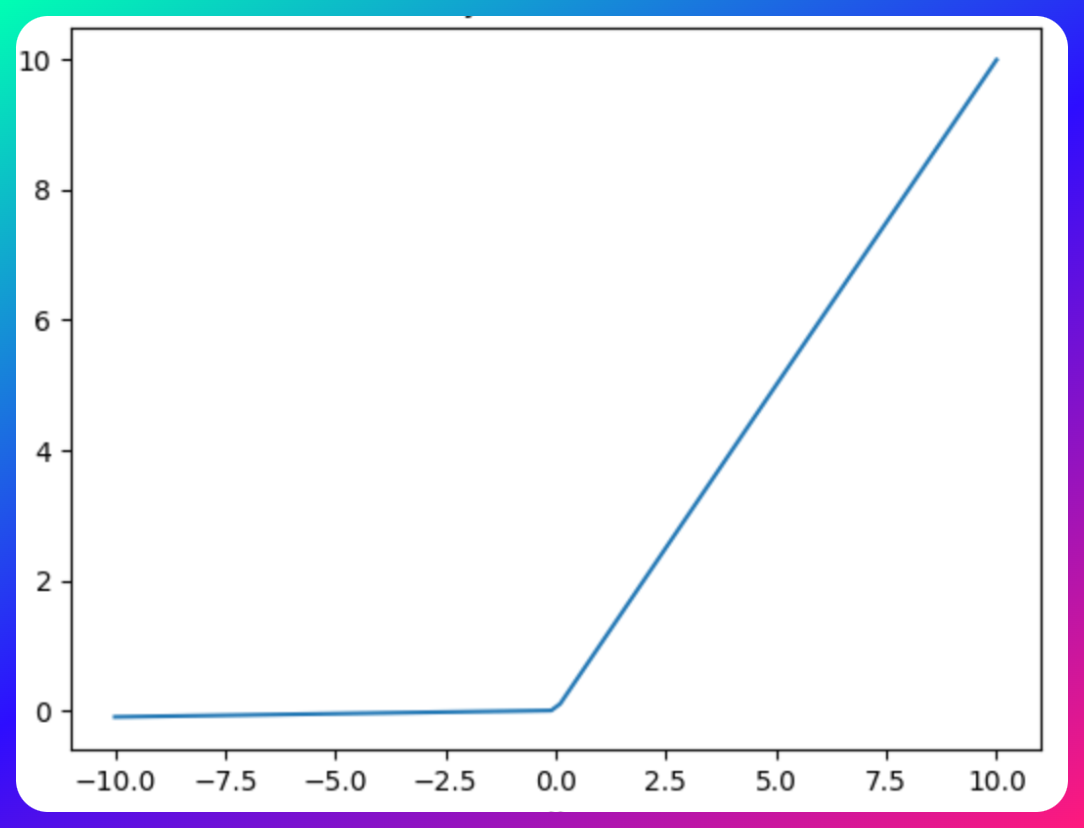
Parametric ReLU (PReLU)
Parametric ReLU (PReLU) is an advanced variation of the traditional ReLU and Leaky ReLU activation functions, designed to further optimize neural network performance.
PReLU improves upon Leaky ReLU by making the slope a learnable parameter, enhancing model accuracy and convergence.
Yet, fine-tuning this parameter can be time-consuming, especially with diverse datasets.
PReLU has shown effectiveness in various applications, particularly in fields where capturing complex patterns is crucial, like computer vision and speech recognition.
In conclusion, PReLU represents a significant advancement in activation function design, offering adaptability and potentially better performance. However, its benefits come with the cost of increased model complexity and the need for careful tuning and regularization. Its use is particularly advantageous in scenarios where the added complexity is justified by the need to capture intricate patterns in the data.
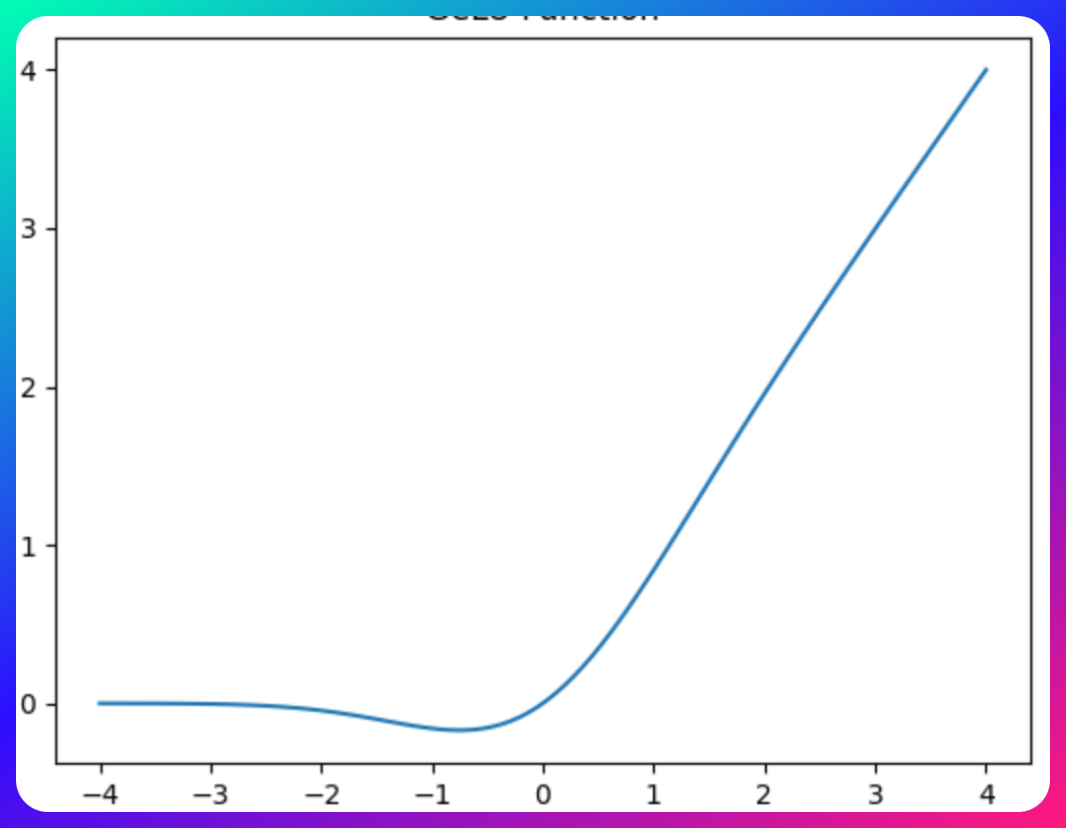
Gaussian Error Linear Unit (GeLU)
The Gaussian Error Linear Unit (GeLU) is a relatively recent addition to the suite of activation functions used in neural networks, known for its unique approach to handling inputs. It stands out due to its probabilistic foundations and smooth approximation characteristics.
GeLU is a smooth approximation of the rectifier function, scaling inputs by their percentile rather than their sign, offering another alternative in the ReLU family.
GeLU has gained notable popularity in transformer architectures, such as those used in models like BERT and GPT, where it has shown to improve performance in natural language understanding tasks.
Due to its smooth and non-linear nature, GeLU can be a good fit for complex models that require more nuanced activation behaviors, such as in advanced computer vision and speech recognition systems.
In summary, the Gaussian Error Linear Unit (GeLU) represents an innovative approach in the realm of activation functions, combining elements of probabilistic modeling with the benefits of smooth, non-linear activation. Its adoption in advanced models highlights its potential, although its computational demands and behavior under various scenarios remain areas for consideration and research.
ReLU vs. Leaky ReLU vs. Parametric ReLU
Here's a comparative analysis of vanilla ReLU and its two variants.
| Property | ReLU | LReLU | PReLU |
| Advantage | Solves gradient problems | Solves gradient problems | Solves gradient problems |
| Disadvantage | Dying relu problem | Inconsistent output for negative input | Fine-tune α |
| Hyperparameter | None | None | 1 |
| Speed | Fastest | Faster | Fast |
| Accuracy | High | Higher | Highest |
| Convergence | Slow | Fast | Fastest |
Conclusion
In this article, we explored activation functions, particularly ReLU and its variants, in artificial neural networks.
ReLU stands out for its simplicity and effectiveness in introducing non-linearity, while its variants address specific challenges like gradient problems and inconsistency with negative inputs.
Understanding these functions is crucial for designing and optimizing neural networks for a wide range of applications.
If you like this article, share it with others ♻️
That would help a lot ❤️
And feel free to follow me for more like this.
Subscribe to my newsletter
Read articles from Juan Carlos Olamendy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Juan Carlos Olamendy
Juan Carlos Olamendy
🤖 Talk about AI/ML · AI-preneur 🛠️ Build AI tools 🚀 Share my journey 𓀙 🔗 http://pixela.io