Navigating the Data Ingestion Landscape: A Comprehensive Guide, Part 1
 Warui Wanjiru
Warui WanjiruTable of contents
- Introduction
- Understanding Data Ingestion
- Data Pipelines Defined
- Key Engineering Considerations for the Ingestion Phase
- Bounded vs. Unbounded Data
- Synchronous Versus Asynchronous Ingestion
- Serialization and Deserialization
- Throughput and Scalability
- Reliability and Durability
- Payload Characteristics
- Push Versus Pull Versus Poll Patterns
- Conclusion

Introduction
In the realm of data engineering, the process of data ingestion plays a pivotal role in the journey of information from source systems to storage. This comprehensive guide aims to delve into the intricacies of data ingestion, exploring key engineering considerations, patterns, and choices that data engineers encounter in their quest to build efficient data pipelines.
Understanding Data Ingestion
What Is Data ingestion?
Data ingestion is the fundamental process of moving data from one place to another within the data engineering lifecycle. This movement from source systems to storage is an intermediate step, laying the groundwork for subsequent data processing and analysis. The visual representation of data flowing from one system to another illustrates the essence of data ingestion.
Contrasting Data Ingestion and Data Integration
It's essential to differentiate between data ingestion and data integration. While data ingestion focuses on the straightforward movement of data from point A to B, data integration takes a step further. It involves the amalgamation of data from disparate sources into a new dataset. This distinction becomes clear when considering scenarios like combining CRM data, advertising analytics, and web analytics to create a comprehensive user profile.
Data Ingestion vs. Internal Ingestion
Another crucial distinction is understanding that data ingestion differs from internal ingestion within a system. The latter involves copying data within a database or temporary caching in a stream, both integral components of the broader data transformation process.
Data Pipelines Defined
Data Pipelines Begin Here
Data pipelines, the backbone of the data engineering space, find their genesis in source systems. Still, during the ingestion stage, data engineers actively design and shape these pipelines. Data engineering is witnessing a shift from traditional monolithic approaches to open ecosystems of cloud services, akin to assembling LEGO bricks to realize intricate products. A modern data pipeline encapsulates established patterns like ETL and newer concepts like ELT, reverse ETL, and data sharing.
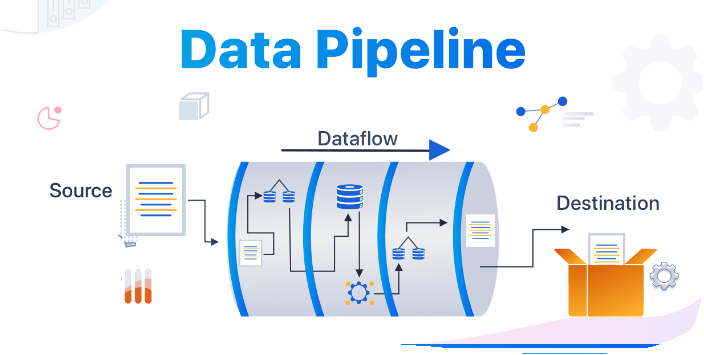
Defining Data Pipelines
In its broadest sense, a data pipeline embodies the combination of architecture, systems, and processes facilitating data movement across various stages of the data engineering lifecycle. The intentionally fluid definition allows data engineers the flexibility to adapt to the unique requirements of each task, whether it's a traditional ETL system or a cloud-based pipeline orchestrating diverse tasks like data ingestion, model training, deployment, and ongoing performance monitoring.
Key Engineering Considerations for the Ingestion Phase
Preparing for Data Ingestion Architecture
Data engineers must address several critical considerations before diving into the architecture or development of an ingestion system. These considerations act as guiding principles to ensure the data ingestion process's efficiency, scalability, and reliability.
Use Case for Data Ingestion
Understanding the use case for the data being ingested is paramount. Whether periodic updates, real-time streaming, or other scenarios, the use case shapes the architecture and design choices.
Avoiding Redundancy through Data Reuse
Can the data be reused, eliminating the need to ingest multiple versions of the same dataset? This consideration emphasizes the importance of optimizing data handling and storage.
Destination and Update Frequency
It is crucial to determine where the data is headed and how often it should be updated from the source. These factors influence the choice of technologies and design patterns for the data pipeline.
Handling Data Quality and In-Flight Processing
Ensuring the quality of the source data is imperative. Questions regarding the immediate downstream use, required post-processing, and potential data-quality risks must be addressed. Additionally, for streaming sources, considerations about in-flight processing become pertinent.
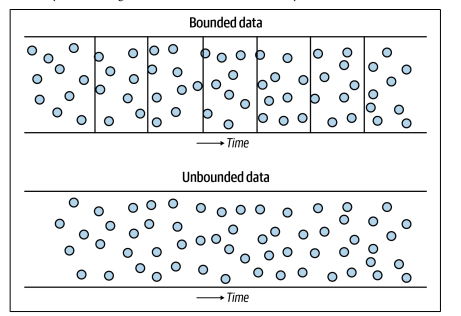
Bounded vs. Unbounded Data
Understanding Data Forms
Data comes in two primary forms: bounded and unbounded. Unbounded data reflects the continuous flow of events in real-time, while fixed data is organized into discrete batches. Recognizing the true unbounded nature of data is crucial, especially in streaming ingestion systems that preserve this unbounded characteristic for downstream processing.
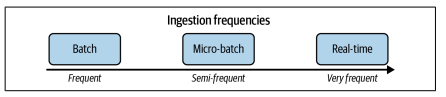
Frequency Matters
One of the critical decisions in data ingestion design is choosing the frequency of the process. Whether batch, micro-batch, or real-time, the ingestion frequency varies based on use cases and technological requirements.
Real-time Challenges and Opportunities
The term "real-time" is commonly used, although true real-time ingestion is nearly impossible due to inherent latency in data delivery. The concept of near-real-time, often used interchangeably with streaming, represents a pattern where events are processed individually or in micro-batches without explicit update frequencies.
Integration of Batch and Streaming
In many scenarios, data engineers deal with batch and streaming processes. While streaming ingestion is ideal for IoT applications and continuous data generation, batch processing downstream remains a standard practice, particularly for training machine learning models.
Synchronous Versus Asynchronous Ingestion
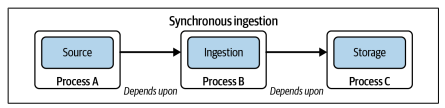
Decoding Workflow Dynamics
Workflow dynamics play a pivotal role in the effectiveness of data ingestion. Synchronous ingestion, depicted by tightly coupled dependencies between source, ingestion, and destination processes, contrasts with asynchronous ingestion, where individual events become available for processing as soon as they are ingested.
Pitfalls of Synchronous Workflows
Synchronous workflows, common in traditional ETL systems, may lead to significant challenges, especially when a failure in one stage impacts subsequent processes. The author presents a case study highlighting the pitfalls of a poorly designed transformation pipeline that took over 24 hours to complete.
Advantages of Asynchronous Ingestion
Asynchronous ingestion, characterized by dependencies operating at the level of individual events, offers advantages reminiscent of microservice architectures. Events become available for storage and processing in parallel, enhancing efficiency and fault tolerance.
Serialization and Deserialization
Navigating Data Encoding and Decoding
Moving data from source to destination involves serialization and deserialization—encoding data for transmission and preparing data structures for intermediate storage stages. The emphasis is on ensuring that the destination system can properly deserialize the ingested data, preventing it from becoming inert and unusable.
The Crucial Role of Serialization
Serialization, the process of encoding data, becomes a critical aspect of data movement. The author highlights instances where data, though successfully ingested, remains inert at the destination due to issues with deserialization.
Throughput and Scalability
Ensuring that data ingestion is a manageable bottleneck is crucial for scalable systems. Considerations about data throughput and system scalability become imperative as data volumes grow, emphasizing the need to design systems that flexibly match the desired data throughput.
Reliability and Durability
Building Robust Data Ingestion Systems
Reliability and durability take centre stage in the ingestion phase of data pipelines. High uptime, proper failover mechanisms, and data integrity are essential when architecting and building ingestion systems.
Risk Evaluation and Redundancy
Evaluating the risks associated with potential data loss and corruption is crucial. The author suggests building redundancy and self-healing mechanisms based on the impact and cost of losing data, emphasizing the need for a balanced approach that aligns with the organization's goals and resources.
Challenges in Extreme Scenarios
The author advises against assuming the creation of a system that can reliably and durably ingest data in every possible scenario. Extreme situations, such as internet outages, may render data ingestion inconsequential. Continually evaluating trade-offs and costs is necessary for making informed decisions about reliability and durability.
Payload Characteristics
Understanding the Data Being Ingested
The payload, representing the dataset being ingested, carries distinct characteristics that impact the data engineering lifecycle. Understanding the kind, shape, size, schema, data types, and metadata of the payload is vital for effective data processing.
Impact of Data Kind
The kind of data being handled directly influences downstream processing. Whether it's tabular, image, video, or text data, each category has unique characteristics that affect serialization and deserialization.
Shape: Critical Dimensions
Every payload has a shape describing its dimensions. The condition is critical for subsequent processing across the data engineering lifecycle, from the number of rows and columns in tabular data to the key-value pairs and nesting depth in semistructured JSON.
Size: Navigating Large Payloads
The size of the data payload, ranging from single bytes to terabytes, presents challenges and opportunities. Strategies such as compression and chunking are employed to reduce payload size and facilitate efficient transmission over networks.
Schema and Data Types
Many data payloads come with a schema describing fields and data types. Understanding the schema is crucial for effective data integration, and schema changes must be detected and handled appropriately. Schema registries in streaming data help maintain schema and data type integrity.
Metadata: The Unseen Value
Metadata, as data about data, is often as critical as the data itself. Ensuring detailed data descriptions, including schema information, facilitates usability and value.
Push Versus Pull Versus Poll Patterns
Strategies for Data Movement
The choice of strategies for data movement—push, pull, or poll—introduces nuances to the data ingestion process. Each pattern presents unique advantages and considerations, influencing how data is transferred from source to destination.
Push Strategy
A push strategy involves the source system actively sending data to a target. showcasing a direct data flow from the source to the destination.

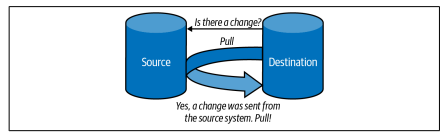
Pull Strategy
Conversely, a pull strategy entails the target reading data directly from a source. The destination pulls data when needed, creating a more on-demand approach.

Polling for Changes
A polling strategy involves periodically checking a data source for any changes. The destination pulls data when changes are detected, providing a flexible approach that adapts to evolving data scenarios.
Conclusion
In conclusion, navigating the data ingestion landscape involves a deep understanding of the key engineering considerations, patterns, and choices that data engineers encounter. From the fundamental concepts of data ingestion to the intricacies of payload characteristics and data movement patterns, this comprehensive guide provides a roadmap for building robust and efficient data pipelines. As data engineering evolves, embracing flexibility, scalability, and reliability remains at the core of effective data ingestion strategies.
Subscribe to my newsletter
Read articles from Warui Wanjiru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Warui Wanjiru
Warui Wanjiru
I am a passionate and highly motivated Junior Data Engineer, driven by my curiosity and eagerness to explore the vast world of data. With a solid foundation in data analytics, programming, and database management, I thrive on the challenge of extracting, cleaning, transforming, and visualizing data to uncover valuable insights. My journey in the realm of data engineering has exposed me to various programming languages and tools, including Python, SQL, and Tableau. However, I don't stop there—I am constantly seeking new knowledge and skills to stay ahead of the curve. Currently, I am immersing myself in the world of Rust, harnessing its speed and efficiency prowess. Embracing this new language allows me to tackle complex data engineering tasks with even greater efficiency and effectiveness. What truly sets me apart is my genuine enthusiasm for learning and taking on new challenges. I thrive in dynamic environments that push me to think creatively and find innovative solutions. With a solid understanding of data structures and algorithms, I relish the opportunity to dive into complex datasets, unearthing patterns and unlocking actionable insights. Above all, I am dedicated to making a real impact through data engineering. I believe in the power of data to drive transformative change and improve decision-making processes. By harnessing the power of data, I strive to empower organizations to make informed choices and achieve tangible results. Let's embark on this exciting journey together, where I can contribute my authentic enthusiasm, my thirst for knowledge, and my unwavering commitment to delivering exceptional data solutions.