Learning Note: Data Compression
 Raine
RaineThis article is a summary of Chapter 6 of:
Yazawa, H. (2015). 程序是怎么跑起来的[How Program Works] (L. Fengjun, Trans.). People's Posts and Telecommunications Press
RLE Algorithm
RLE (Run Length Encoding) is a data compression method that compresses files to (character X repeating times). For example, AAAAAABBCDDEEEEEF can be compressed to A6B2C1D2E5F1. RLE is useful for compressing FAX file containingmany recurring black and white pixels, images, and EXE files.
However, RLE has limited ability in dealing with files without many repeating characters. For example, for a sentence "This is a pen", the result of RLE would be "T1h1i1s1 1i1s1 1a1 1p1e1n1", which turns out to be longer than the original data.
Huffman Coding
Not all characters must be represented in one byte. We can assign more frequent words with shorter binary codings and less frequent words longer codings. This idea was implemented since Morse code, in which the code length of a character depends on its frequency in general.
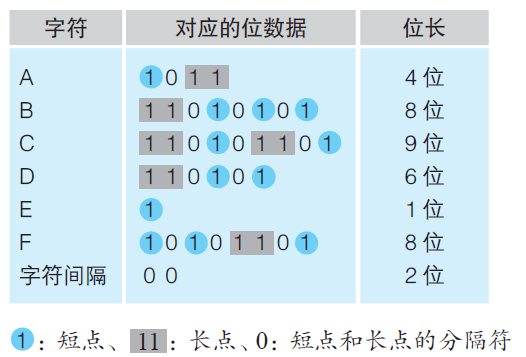
Fig 1. Morse code of A to F. (Image reproduced from Yazama, 2015)
Huffman coding creates a best coding system for every individual file and compress the file based on the coding. This is achieved through constructing a binary search tree called Huffman tree. The construction of Huffman tree is a bottom-up process as follows:
List every character and its corresponding frequency
Connect the two least frequent words (choose any two if there are many with same frequency) and connect them.
Repeat process 2 until connecting all characters to a single root node.
Starting from the root node, assign 0 to the left child node and 1 to the right child node. This becomes the code of each character.

Fig 2. A demonstration of the process of Huffman coding (Image reproduced from Yazama, 2015)
There are two notable advantage of Huffman coding. Firstly, it achieves the principle "assigning code lentgh depending on frequency". In Huffman coding, it takes more layers in the binary search tree to reach less frequent words, so less frequent words have longer codings, and the longest possible coding length would be logN (N is the number of distinct characters). Secondly, Huffman code does not need specific separaters to distinguish two words, since we identify an character only when reacing the end of the tree. For example, using the result from Fig 2, 0000000000001001001101011010101010101111 can unambiguously be translated to AAAAAABBCDDDEEEEEF
Reversable and Irreversable Compression
Unlike text and EXE files, it is usually acceptable for images to loose certain detailed clarity. Image file types like GIF, JPEG, and TIFF are all compression techniques the looses certain details. These compression algorithms that cannot restore the compressed files to original files are called irreversable compression. In contrast, reversable compression are compression algorithms than does not lose data.
Subscribe to my newsletter
Read articles from Raine directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by