Strong Consistency On Asynchronous Read Replica Databases With Accurate Clock
 Dichen Li
Dichen Li
My personal favorite for "what's new" from AWS re:invent 2023 was the announcement of the micro-second accuracy clock and ClockBound API. (There were other many exciting announcements too!) They brought two timely new features: micro-second accurate time on EC2, and guaranteed upper & lower bound clock error exposed from ClockBound APIs. This has some interesting impacts to distributed system designs. This great new blog post from Marc Brooker has summarized it well: https://brooker.co.za/blog/2023/11/27/about-time.html .
In this blog, I want to expand on one single aspect of the story here: to allow linearizable consistency level on database asynchronous read replicas.
Background: strong vs. eventual consistency
Linearizability is more often referred to as strong consistency in many database literatures. Here is a clear explanation of this term: https://jepsen.io/consistency/models/linearizable, but in short, it basically means that once a transaction is committed, all new transactions started after that immediately see the effect of this committed transaction. It is contradictory to "eventual consistency" where the client may see stale data that may not reflect newest committed writes.
In theory, it is straightforward (not really in practice!) to achieve strong consistency on a single writer node: writes will commit only after it has updated the in-memory cache and flushed redo log, so that follow up reads will immediately see the newest committed data.
It is much harder to achieve strongly consistent reads from asynchronous read replicas though. "Asynchronous" means that writer can replicate data to readers any time after committed. If a client issues a write, receives commit success from writer, then immediately read the value from an async replica, they may outrace the replication delay and see the stale value. Worse still, if there are multiple read replicas behind a load balancer, the client may read a newer value from a more advanced replica, then read again, only to see an older value, because it is randomly routed to a slower replica. It is often difficult and bug-prone to handle the subtlety of such data staleness from client side, and can be confusing to end users (imagine you have placed an order online, refresh the page, only to see the order is still pending payment). Async replicas are a great way for horizontal read scaling, but weak consistency guarantee limits their usefulness in real world applications.
I found this great blog from Murat Demirbus that summarized several ways to achieve strong consistency on read replicas. Some may require a Paxos quorum or special hardwares like RDMA (as in PolarDB), thus may not be applicable to classic database setups with a single writer and multiple async read replicas.
What if we have an ideal clock?
Let's assume we have an infinitely accurate clock on every database host. What can we do differently? Marc Brooker's blog provided a new approach: (so there is really nothing original from my blog!)

This simple approach is widely applicable. Most databases use a write-ahead log to apply total ordering of write commits. The database can bake in current clock timestamp into the WAL record, and make sure they follow the real-world clock ordering.
On the read replica side, when a new read request arrives, it can first get the current time from local clock, then wait until the storage has seen newer WALs received from writer, then serve the read request from a point in time that include all older writes using some techniques like MVCC (multi-version concurrency control). With total ordering of WAL by real-world clock, the reader is certain that as long as it has seen a commit at any point in time, it has also seen it all before this timestamp, so the read will return all writes committed before it.
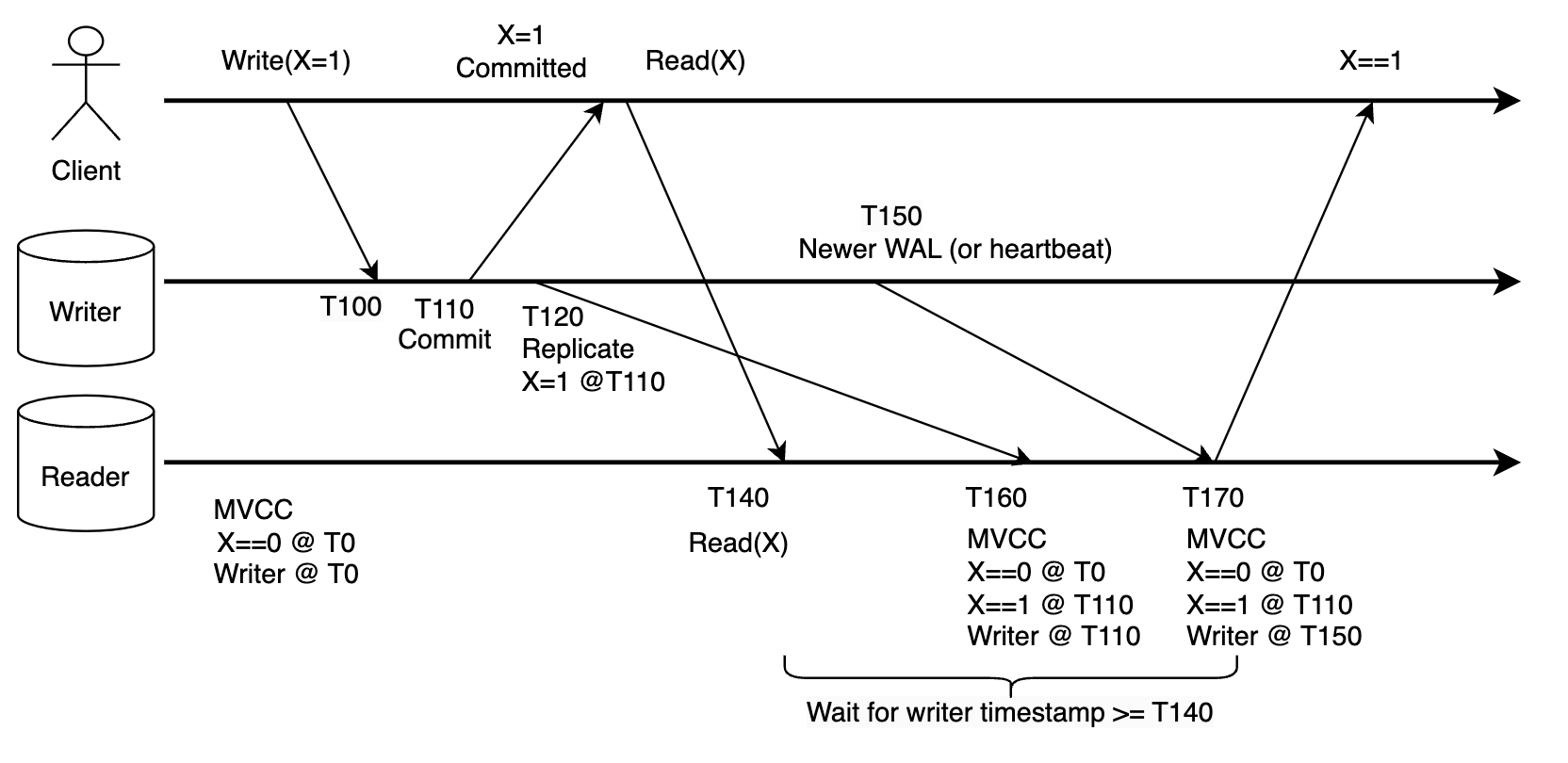
Above is an example, where client writes X=1, then immediately reads X from an async read replica. Replica receives the read request at time 140, waits until it has seen newer write commit from WAL (or heartbeat, see next section) from writer, then returns X=1. Notice the clock protocol is completely internal and transparent to the client.
Handle Idleness
What if the writer is completely idle, so that readers never see anything new from writer? The reader will not be able to differentiate whether the writer is just idle, or local data is stale but there is some huge network delay.
Obviously, you may solve this problem by periodically sending dummy writes to writer. But this is more expensive since it needs to go through transaction execution and WAL IO flush. A cheaper way might be to extend the database replication protocol to support a new heartbeat signal. The writer may periodically (say in every 1 ms and tunable) send the (last commit timestamp, current timestamp) tuple to replicas. The replica may use this message to know that it has caught up and seen all transactions before the "current timestamp" as long as it has received all the commits up to the "last commit timestamp", so that all read requests started before the "current timestamp" can be safely returned.
This heartbeat can be skipped if the writer is under heavy write workload so reader keeps getting newer commits from WAL anyway.
With this approach, the synchronous read will get an average latency penalty of 0.5 ms (assume 1 ms heartbeat interval), and there is no extra workload on the writer if it is already very busy.
Handle Clock Error
Now let's be back to reality and consider clock inaccuracy. With clock skew, strongly consistent read is not guaranteed: say if the writer's clock is faster than the reader. Now the client commits a write, then immediately reads it from a replica. But the write would be assigned a much higher timestamp, so the reader would mistakenly believe it has seen newer records from the writer "from the future", thus it would immediately reply with a stale value.
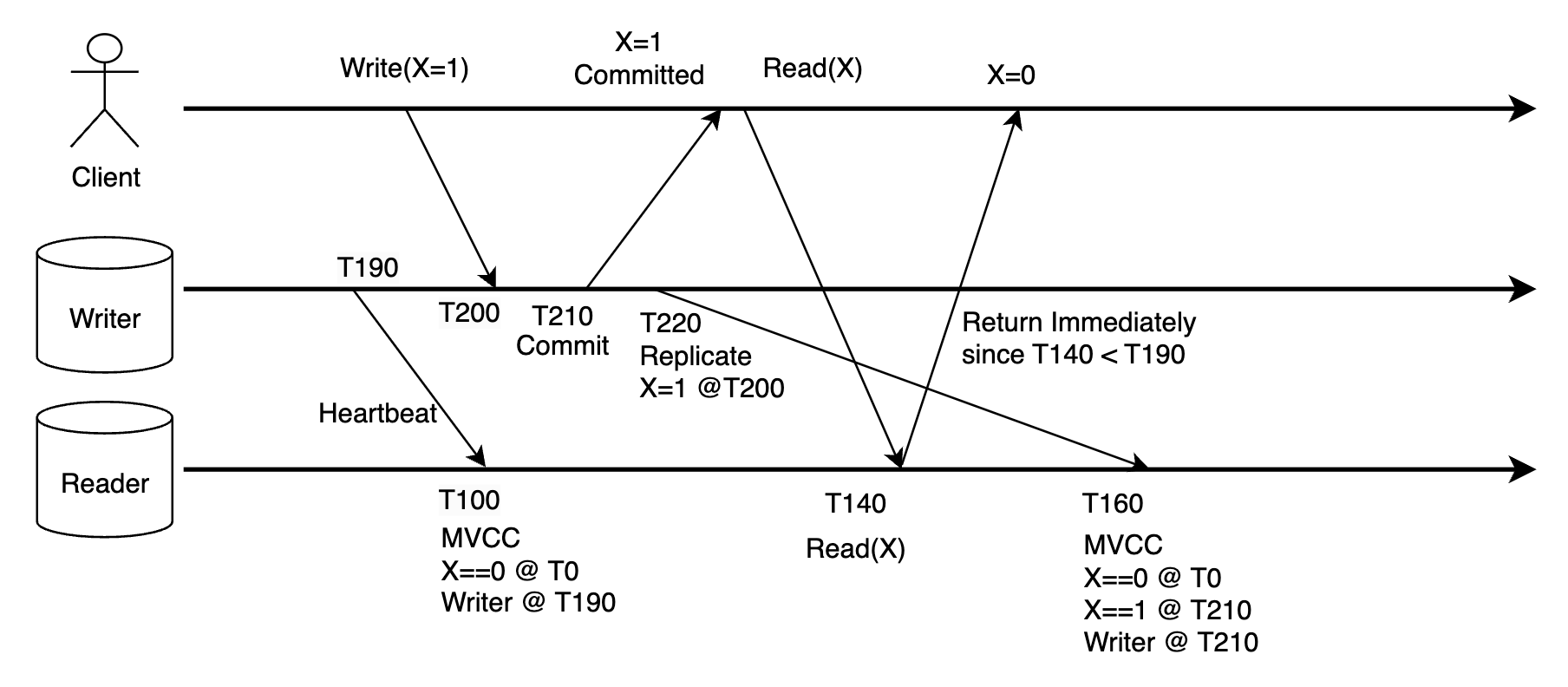
If writer's clock is slower, the impact is mainly just extra read latency.
With microsecond clock accuracy, clock skew may not be a real concern. For example, assume client to server network delay is 100 us. a client might write something, sees commit success after 100 us, then immediately read from a replica server, which will take another 100 us to arrive at the reader. Assume the writer's clock is 50 us faster than the reader, it is still too small compared with the 200 us delay between the write and read requests, so correct result will be returned anyway.
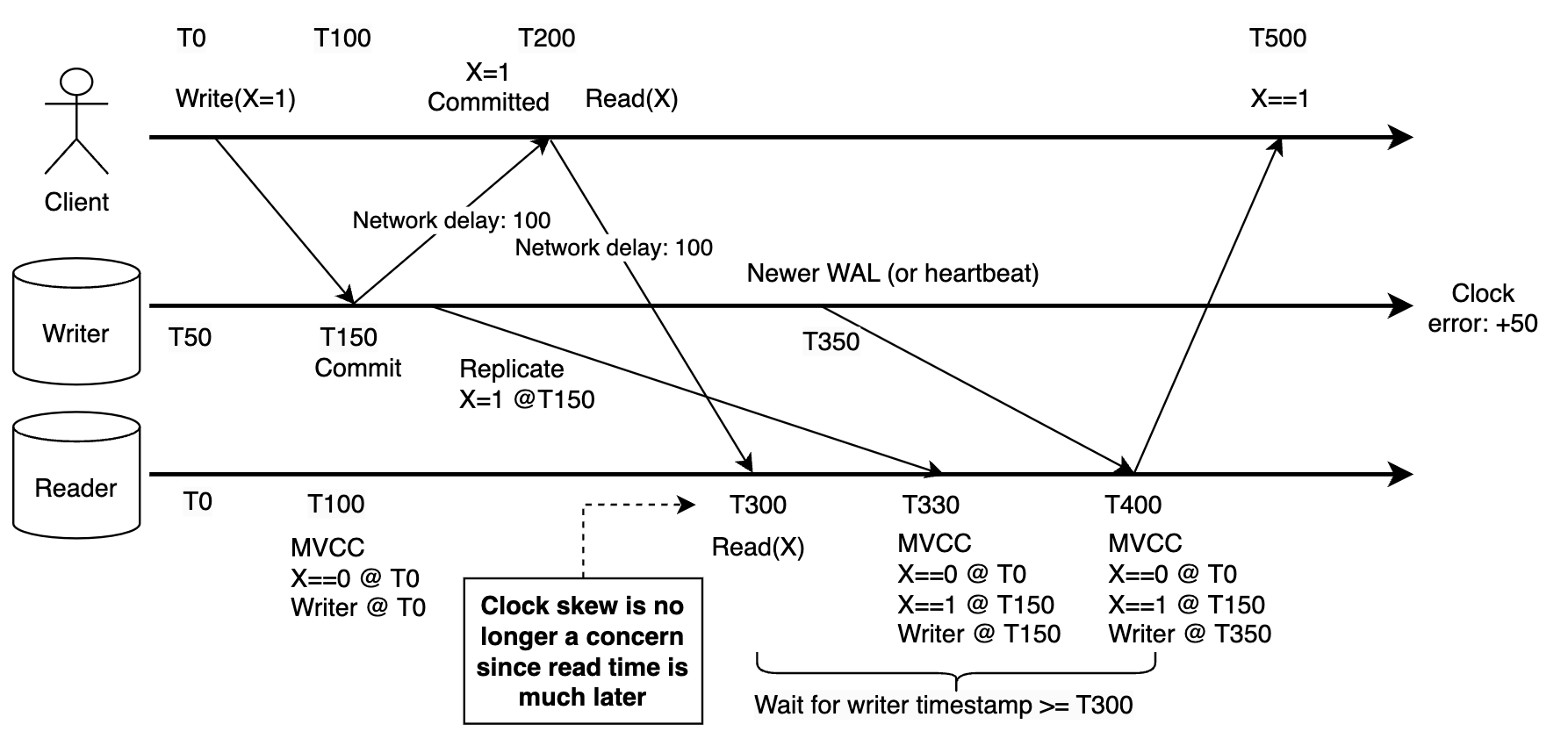

If the clock error is higher but still bounded, the Spanner paper has described a way to ensure causality using the TrueTime API (similar to ClockBound): the first write request assigns a commit timestamp at TT.now().latest, then wait until TT.now().earliest is higher than the assigned commit time before returning commit success to client. A new read request must assign a transaction timestamp later than TT.now().latest in the beginning, then wait until the storage is caught up to that timestamp, then execute the read request at this assigned point in time. This way, the read is guaranteed to be timestamped later than the writes that happened before it despite potential clock skew. Detailed proof can be found in the paper so I will not expand here.
This approach may add additional latency (proportional to the clock error bound) and implementation complexity, but provides a much stronger guarantee. If the clock bound is within microseconds, the database will probably just use the waiting period to do other useful but slow work, like flushing WALs locally, so we are unlikely to introduce real commit delay anyway.
Multi-Writer
Same idea applies to Multi-Paxos quorum as well. Assuming a multi-Paxos algorithm variant where all member nodes are allowed to propose writes, and the consensus algorithm ensures all the writes are globally totally ordered in the commit log. Despite the distributed coordination and consensus, parts of the algorithm is async (for good reason), so overall the cluster is only eventually consistent for reads. (For example, this results in eventual consistency in MySQL Group Replication plugin.)
This is deep topic and I'm not familiar with the past researches (so don't trust what I say here), but intuitively, things can work just the same as above: each node acts like an async read replica, waits until it has seen all writes from the peer writers (including itself), then serve strongly consistent reads.
Even though Paxos ensures a global total ordering of commits, the timestamps only need to be partially ordered. More specifically, each writer just ensures all writes from itself are ordered by the local clock, but writes from different writers may not be sorted by the clock due to network delay. As long as each node is aware of all the quorum members, it can keep track of a separate timestamp watermark for each peer, and use the lowest watermark of all as the global consistent point to block strongly consistent read requests after that. This is very rough idea (e.g. what if one writer fails?) I could not find a research paper that provided a detailed algorithm yet.
Where can this apply?
This approach provides a relatively cheaper, more scalable way for strongly consistent reads than simply making replicas synchronous. This is widely applicable to different database engines in theory, though some storage layer modifications might be needed to incorporate clock time into persisted versioned storage and write-ahead log.
This is NOT a way to scale writes though. For a given database engine, it potentially adds linearizability consistency level on top of the given isolation level (serializable, snapshot isolation, etc., see https://jepsen.io/consistency) on top of the given write scaling characteristics of the DB.
Final thoughts
Quantitative change can lead to qualitative change. All distributed system books start with a pessimistic tone that everything can fail and nothing can be trusted, then go on to discuss ways to deal with them. We are indeed constraint by physical laws: network cannot be faster than speed of light, clock can't be infinitely accurate, storage and network cannot be 100% reliable. But sometimes "better" can be almost as good as "perfect": what if we make storage durable 99.9999999% of time? What if we could reduce clock error to microsecond? What if network latency between US and Europe is reduced 5x? (Yes, it is still slower than speed of light.) What if the network between two hosts in a region is guaranteed available 99.9999% of time? The list goes on. Many of these may be too costly to be worth solving, but some thought experiments may help us to discover unseen opportunities.
All opinions are my own. Though I also work in Amazon, I did not work in related teams or got involved in relevant projects, so this is just an outsider view.
Subscribe to my newsletter
Read articles from Dichen Li directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Dichen Li
Dichen Li
I'm a software engineer in AWS. I've spent years building databases as cloud services. This is my personal blog, all opinions are my own. My medium blog: https://medium.com/@dichenldc