Scraping GitHub Repositories and Profiles with Python.
 Crawlbase
Crawlbase
This blog is originally posted on crawlbase blog.
Welcome to our guide on using Python for scraping GitHub repositories and user profiles.
Whether you’re a data enthusiast, a researcher, or a developer looking to gain insights from GitHub, this guide will equip you with the knowledge and tools needed to navigate GitHub’s vast repository and user landscape.
Let’s get started!
If you want head right into setting up python, click here.
Table Of Contents
Installing Python
Setting Up a Virtual Environment
Installing Required Python Packages
GitHub Repositories
GitHub User Profiles
Navigating GitHub Repositories
Extracting Relevant Information
Implementing the Scraping Process and Saving to CSV
Navigating User Profiles
Retrieving User Details
Implementing the Scraping Process and Saving to CSV
Why Scrape GitHub Repositories and Profiles
GitHub Scraping involves systematically extracting data from the GitHub platform, a central hub for software development with informative data such as source code, commit history, issues, and discussions.
GitHub has an established reputation for its large user base and high number of users. Therefore its the first choice of developers when it comes to scraping. GitHub scraping, or gathering data from GitHub repositories and user profiles, is important for various individuals and purposes. Some of them are listed below:

Project Assessment:
Understanding Project Popularity: By scraping repositories, users can gauge the popularity of a project based on metrics such as stars, forks, and watchers. This information is valuable for project managers and developers to assess a project’s impact and user engagement.
Analyzing Contributor Activity: Scraping allows the extraction of data related to contributors, their contributions, and commit frequency. This analysis aids in understanding the level of activity within a project, helping to identify key contributors and assess the project’s overall health.
Trend Analysis:
Identifying Emerging Technologies: GitHub is a hub for innovation, and scraping enables the identification of emerging technologies and programming languages. This insight is valuable for developers and organizations to stay abreast of industry trends and make informed decisions about technology adoption.
Tracking Popular Frameworks: Users can identify popular frameworks and libraries by analyzing repositories. This information is crucial for developers choosing project tools, ensuring they align with industry trends and community preferences.
Social Network Insights:
Uncovering Collaborative Networks: Scraping GitHub profiles reveals user connections, showcasing collaborative networks and relationships. Understanding these social aspects provides insights into influential contributors, community dynamics, and the interconnected nature of the GitHub ecosystem.
Discovering Trending Repositories: Users can identify trending repositories by scraping user profiles. This helps discover projects gaining traction within the community, allowing developers to explore and contribute to the latest and most relevant initiatives.
Data-Driven Decision Making:
- Informed Decision-Making: GitHub scraping empowers individuals and organizations to make data-driven decisions. Whether it’s assessing project viability, choosing technologies, or identifying potential collaborators, the data extracted from GitHub repositories and profiles serves as a valuable foundation for decision-making processes.
Setting Up the Environment
We need to setup and install Python and its necessary packages first. So lets get started.
Installing Python
If you don’t have Python installed, head to the official Python website and download the latest version suitable for your operating system. Follow the installation instructions provided on the website to ensure a smooth setup.
To check if Python is installed, open a command prompt or terminal and type:
python --version |
If installed correctly, this command should display the installed Python version.
Setting Up a Virtual Environment
To maintain a clean and isolated workspace for our project, it’s recommended to use a virtual environment. Virtual environments prevent conflicts between different project dependencies. Follow these steps to set up a virtual environment:
For Windows:
Open a command prompt.
Navigate to your project directory using the cd command.
Create a virtual environment:
python -m venv venv |
- Activate the virtual environment:
source venv/bin/activate |
You should see the virtual environment’s name in your command prompt or terminal, indicating that it’s active.
Installing Required Python Packages
With the virtual environment activated, you can now install the necessary Python packages for our GitHub scraping project. Create a requirements.txt file in your project directory and add the following:
crawlbase |
Install the packages using:
pip install -r requirements.txt |
Crawlbase: This library is the heart of our web scraping process. It allows us to make HTTP requests to Airbnb’s property pages using the Crawlbase Crawling API.
Beautiful Soup 4: Beautiful Soup is a Python library that simplifies the parsing of HTML content from web pages. It’s an indispensable tool for extracting data.
Pandas: Pandas is a powerful data manipulation and analysis library in Python. We’ll use it to store and manage the scraped price data efficiently.
Your environment is now set up, and you’re ready to move on to the next steps in our GitHub scraping journey. In the upcoming sections, we’ll explore GitHub’s data structure and introduce you to the Crawlbase Crawling API for a seamless scraping experience.
Understanding GitHub’s Data Structure
This section will dissect the two fundamental entities: GitHub Repositories and GitHub User Profiles. Furthermore, we will identify specific data points that hold significance for extracting valuable insights.
GitHub Repositories:
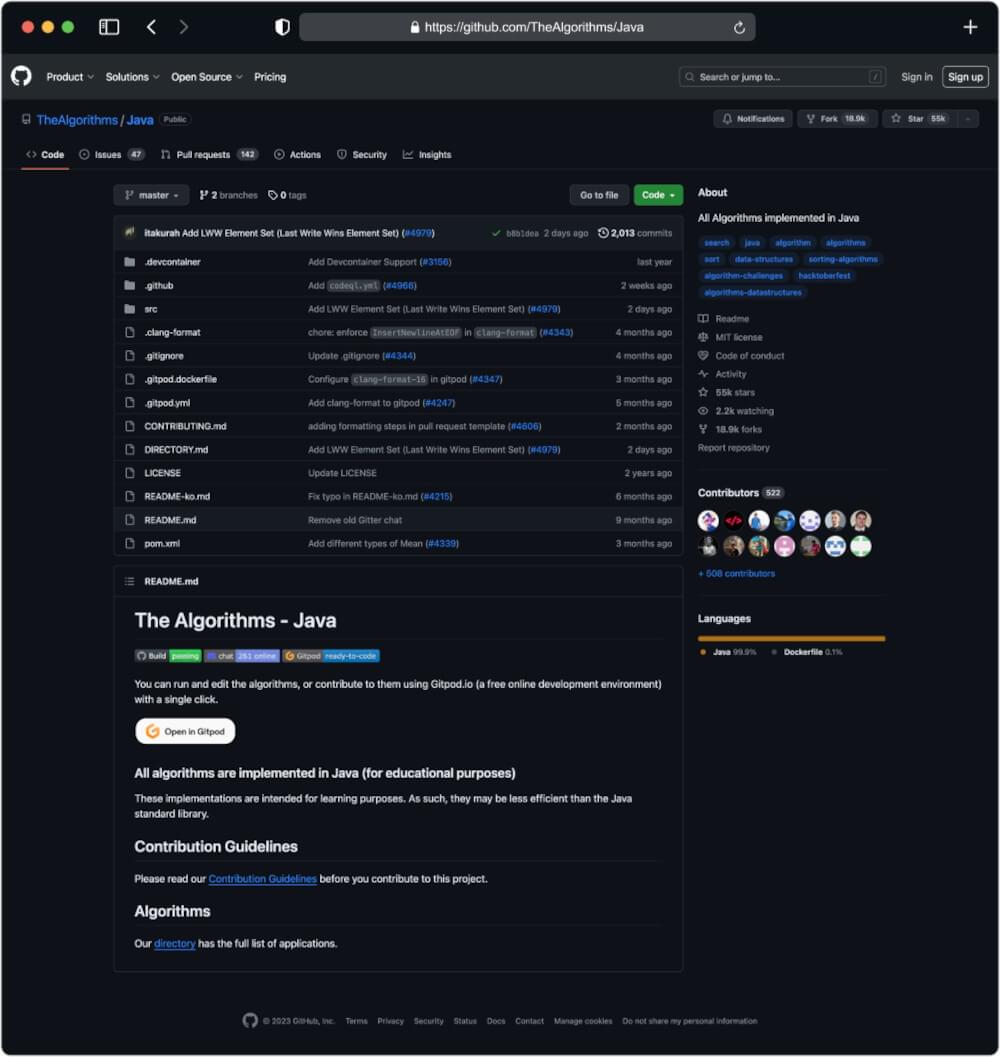
Repository Name and Description
The repository name and its accompanying description offer a concise glimpse into the purpose and goals of a project. These elements provide context, aiding in categorizing and understanding the repository.
Stars, Forks, and Watchers
Metrics such as stars, forks, and watchers are indicators of a repository’s popularity and community engagement. “Stars” reflect user endorsements, “forks” signify project contributions or derivations, and “watchers” represent users interested in tracking updates.
Contributors
Identifying contributors provides insight into the collaborative nature of a project. Extracting a list of individuals actively involved in a repository can be invaluable for understanding its development dynamics.
Topics
Repositories are often tagged with topics, serving as descriptive labels. Extracting these tags enables categorization and aids in grouping repositories based on common themes.
GitHub User Profiles
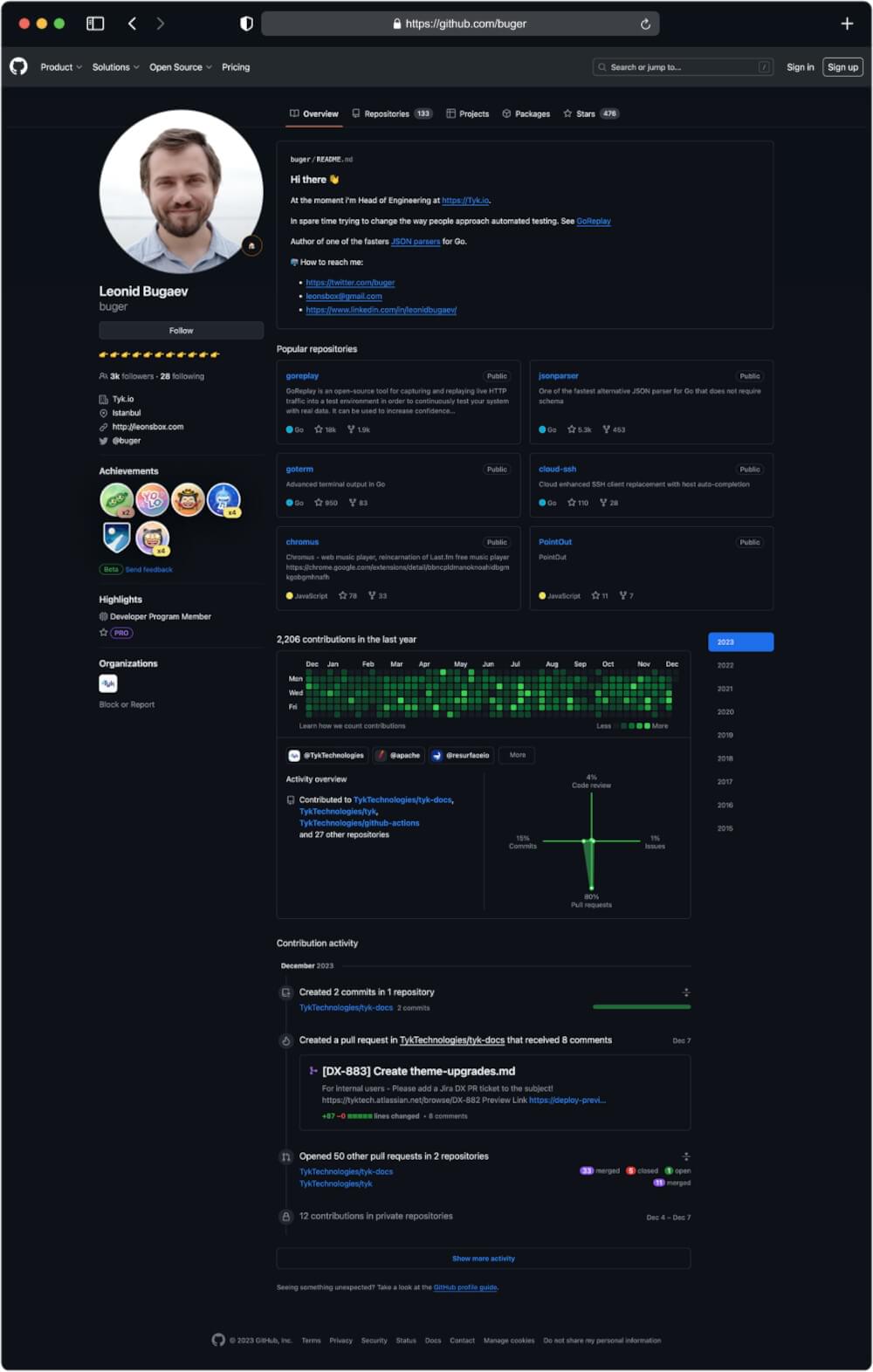
User Bio and Location
A user’s bio and location offer a brief overview of their background. This information can be particularly relevant when analyzing the demographics and interests of GitHub contributors.
Repositories
The list of repositories associated with a user provides a snapshot of their contributions and creations. This data is vital for understanding a user’s expertise and areas of interest.
Activity Overview
Tracking a user’s recent activity, including commits, pull requests, and other contributions, provides a real-time view of their involvement in the GitHub community.
Followers and Following
Examining a user’s followers and the accounts they follow helps map out the user’s network within GitHub. This social aspect can be insightful for identifying influential figures and community connections.
Crawlbase: Sign Up, Obtain API Token
To unlock the potential of the Crawlbase Crawling API, you’ll need to sign up and obtain an API token. Follow these steps to get started:
Visit the Crawlbase Website: Navigate to the Crawlbase website sign-up option.
Create an Account: Register for a Crawlbase account by providing the necessary details.
Verify Your Email: Verify your email address to activate your Crawlbase account.
Access Your Dashboard: Log in to your Crawlbase account and access the user dashboard.
Access Your API Token: You’ll need an API token to use the Crawlbase Crawling API. You can find your API tokens on your Crawlbase dashboard or here.
Note: Crawlbase offers two types of tokens, one for static websites and another for dynamic or JavaScript-driven websites. Since we’re scraping GitHub, we’ll opt for the Normal Token. Crawlbase generously offers an initial allowance of 1,000 free requests for the Crawling API, making it an excellent choice for our web scraping project.
Keep your API token secure, as it will be instrumental in authenticating your requests to the Crawlbase API.
Explore Crawling API Documentation
Familiarizing yourself with the Crawlbase Crawling API’s documentation is crucial for leveraging its capabilities effectively. The documentation serves as a comprehensive guide, providing insights into available endpoints, request parameters, and response formats.
Endpoint Information: Understand the different endpoints offered by the API. These could include functionalities such as navigating through websites, handling authentication, and retrieving data.
Request Parameters: Grasp the parameters that can be included in your API requests. These parameters allow you to tailor your requests to extract specific data points.
Response Format: Explore the structure of the API responses. This section of the documentation outlines how the data will be presented, enabling you to parse and utilize it effectively in your Python scripts.
Scraping GitHub Repositories
When venturing into the realm of scraping GitHub repositories, leveraging the capabilities of the Crawlbase Crawling API enhances efficiency and reliability. In this detailed guide, we’ll explore the intricacies of navigating GitHub repositories, extracting valuable details, and crucially, saving the data into a CSV file. Follow each step carefully, maintaining a script at each stage for clarity and ease of modification.
Navigating GitHub Repositories
Begin by importing the necessary libraries and initializing the Crawlbase API with your unique token.
import pandas as pd |
Extracting Relevant Information
Focus on the scrape_page function, responsible for the actual scraping process. This function takes a GitHub repository URL as input, utilizes the Crawlbase API to make a GET request, and utilize BeautifulSoup for scraping relevant information from HTML.
def scrape_page(page_url): |
Implementing the Scraping Process and Saving to CSV
In the main function, specify the GitHub repository URL you want to scrape and call the scrape_page function to retrieve the relevant information. Additionally, save the extracted data into a CSV file for future analysis.
def main(): |
By following these steps, you not only navigate GitHub repositories seamlessly but also extract meaningful insights and save the data into a CSV file for further analysis. This modular and systematic approach enhances the clarity of the scraping process and facilitates easy script modification to suit your specific requirements. Customize the code according to your needs and unlock the vast array of data available on GitHub with confidence.
Output for URL: https://github.com/TheAlgorithms/Java

Scraping GitHub User Profiles
When extending your GitHub scraping endeavors to user profiles, the efficiency of the Crawlbase Crawling API remains invaluable. This section outlines the steps involved in navigating GitHub user profiles, retrieving essential details, and implementing the scraping process. Additionally, we’ll cover how to save the extracted data into a CSV file for further analysis. As always, maintaining a script at each step ensures clarity and facilitates easy modification.
Navigating User Profiles
Begin by importing the necessary libraries, initializing the Crawlbase API with your unique token.
import pandas as pd |
Retrieving User Details
Define the scrape_user_profile function, responsible for making a GET request to the GitHub user profile and extracting relevant information.
def scrape_user_profile(profile_url): |
Implementing the Scraping Process and Saving to CSV
In the main function, specify the GitHub user profile URL you want to scrape, call the scrape_user_profile function to retrieve the relevant information, and save the data into a CSV file using pandas.
def main(): |
By following these steps, you’ll be equipped to navigate GitHub user profiles seamlessly, retrieve valuable details, and save the extracted data into a CSV file. Adapt the code according to your specific requirements and explore the wealth of information available on GitHub user profiles with confidence.
Output for URL: https://github.com/buger

Final Words
Congrats! You took raw data straight from a web-page and turned it into structured data in JSON file. Now you know every step of how to build a GitHub repository scraper in Python!
This guide has given you the basic know-how and tools to easily scrape GitHub repositories and profiles using Python and the Crawlbase Crawling API. Keep reading our blogs for more tutorials like these.
Till then, If you encounter any issues, feel free to contact the Crawlbase support team. Your success in web scraping is our priority, and we look forward to supporting you on your scraping journey.
Frequently Asked Questions
Q. Why is GitHub scraping important?
GitHub scraping is crucial for various reasons. It allows users to analyze trends, track project popularity, identify contributors, and gain insights into the evolving landscape of software development. Researchers, developers, and data enthusiasts can leverage scraped data for informed decision-making and staying updated on the latest industry developments.
Q. Is web scraping GitHub legal?
While GitHub allows public access to certain data, it’s essential to adhere to GitHub’s Terms of Service. Scraping public data for personal or educational use is generally acceptable, but respecting the website’s terms and conditions is crucial. Avoid scraping private data without authorization and ensure compliance with relevant laws and policies.
Q. How can Crawlbase Crawling API enhance GitHub scraping?
The Crawlbase Crawling API simplifies GitHub scraping by offering features such as seamless website navigation, authentication management, rate limit handling, and IP rotation for enhanced data privacy. It streamlines the scraping process, making it more efficient and allowing users to focus on extracting meaningful data.
Q. What are the ethical considerations in GitHub scraping?
Respecting GitHub’s Terms of Service is paramount. Users should implement rate limiting in their scraping scripts to avoid overwhelming GitHub’s servers. Additionally, it’s crucial to differentiate between public and private data, ensuring that private repositories and sensitive information are only accessed with proper authorization.
Q. Is it possible to scrape GitHub repositories and profiles without using the Crawlbase Crawling API and relying solely on Python?
Yes, it’s possible to scrape GitHub using Python alone with libraries like requests and BeautifulSoup. However, it’s crucial to be aware that GitHub imposes rate limits, and excessive requests may lead to IP blocking. To mitigate this risk and ensure a more sustainable scraping experience, leveraging the Crawlbase Crawling API is recommended. The API simplifies the scraping process and incorporates features like intelligent rate limit handling and rotating ip addresses, allowing users to navigate GitHub’s complexities without the risk of being blocked. This ensures a more reliable and efficient scraping workflow.
Subscribe to my newsletter
Read articles from Crawlbase directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by