Get started with Amazon Athena
 Maxat Akbanov
Maxat Akbanov
Amazon Athena is an interactive query service that makes it easy to analyze petabytes of data directly in Amazon Simple Storage Service (Amazon S3), on-premises data sources or other cloud systems using SQL or Python. Athena is built on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.

Here are key features and aspects of Amazon Athena:
Serverless: Athena is serverless, meaning there's no infrastructure to manage. You don't need to set up or manage any servers or data warehouses. This makes it easy to start using and scale without the need for significant administration. At the same time, Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries.
SQL-Based: Athena allows you to use standard SQL to query your data. This is advantageous because SQL is a widely known and used query language, making it accessible to a broad range of users with varying technical backgrounds.
Direct Analysis of Data in S3: Athena helps you analyze unstructured, semi-structured, and structured data stored in Amazon S3. You can run queries against data in S3 without needing to import it into a separate database or storage system.

Pay-Per-Query Pricing Model: Athena uses a pay-per-query pricing model, where you are charged based on the amount of data scanned by each query. This can be cost-effective, especially for sporadic or unpredictable query workloads.
Integration with Other AWS Services: Athena integrates seamlessly with other AWS services. For example, you can use it alongside AWS Glue for data catalog services, or you can visualize your data with Amazon QuickSight.

Supports Various Data Formats: It supports multiple data formats, including JSON, CSV, Avro, Apache ORC, and Parquet. This flexibility allows you to work with the data in its native format without needing complex transformations.
Use Cases: Common use cases for Athena include log analysis (VPC Flow logs, ELB logs, CloudTrail logs), data preparation for ML models, multicloud analytics, data exploration, ad hoc querying, and complex data processing and analysis tasks that are typical in big data environments.
Amazon Athena is a powerful tool for organizations looking to analyze large datasets stored in Amazon S3 using familiar SQL queries, with the added benefits of serverless architecture and integration with the AWS ecosystem.
Performance improvement techniques for Amazon Athena
Amazon Athena's performance and cost efficiency can be significantly improved by employing certain data management and query optimization strategies. Let's explore these techniques:
1. Use Columnar Data Formats for Less Data Scan
Columnar data formats like Parquet or ORC store data in columns rather than rows. This structure is highly efficient for Athena for several reasons:
Selective Reading: Only the columns needed for a query are read, reducing the amount of data scanned.
Better Compression: Columnar data can be compressed more effectively, as similar data types are stored together.
Cost Reduction: Since Athena charges based on the amount of data scanned, reading fewer columns directly translates to lower costs.
2. Compress Data for Smaller Retrievals
Compressing data reduces the file size, which has several benefits:
Reduced Data Scan Costs: Smaller files mean less data is scanned per query, lowering costs.
Improved Performance: Compressed files require less time to read from S3, potentially speeding up query times.
Supported Formats: Athena supports various compression formats for reading and writing data, like GZIP, DEFLATE, LZ4, LZO, ZLIB, ZSTD, Snappy, and BZIP2.
3. Partition Datasets in S3 for Easy Querying on Virtual Columns
Partitioning data involves dividing your data into subsets based on certain column values (like date, region, etc.), and treating each subset as a separate directory in S3:
Less Data Scanned: When you query a partitioned dataset, Athena scans only the partitions that contain relevant data, significantly reducing the amount of data scanned.
Faster Queries: By avoiding unnecessary data, queries run faster.
Virtual Columns: Partitions create virtual columns that you can directly query.
4. Use Larger Files Bigger than 128 MB to Minimize Overhead
Athena performs better with fewer, larger files:
Reduced Overhead: Each file incurs overhead in terms of metadata and connection setup. Fewer, larger files minimize this overhead.
Parallel Processing: Larger files can be processed in parallel more effectively, improving performance.
5. Optimize SQL Queries
Improving the efficiency of SQL queries can also enhance Athena's performance:
Filter Early: Apply
WHEREclauses as early as possible in your queries to reduce the amount of data scanned.Efficient Joins: Ensure joins are on columns with the same data type and structure. Use smaller tables on the right side of a LEFT JOIN for better performance.
6. Use AWS Glue Data Catalog
Integrating Athena with AWS Glue Data Catalog can improve query performance:
Central Metadata Repository: Glue Data Catalog provides a central place to manage metadata, improving the efficiency of query planning and execution.
Schema Evolution and Data Discovery: It facilitates schema evolution and data discovery, which can optimize how queries are executed.
By applying these strategies, you can significantly enhance the performance of Amazon Athena and reduce costs associated with data scanning and query execution.
Federated Query with Amazon Athena
Amazon Athena's ability to run federated queries using data source connectors, such as Lambda functions, significantly expands its querying capabilities beyond the native AWS data stores. Let's first understand what federated queries are and then delve into how Athena leverages Lambda for this purpose.
Federated Query
A federated query is a type of query that allows you to access and combine data from multiple sources as if it were all residing in a single database. In the context of cloud computing and data analytics, this means querying data across different systems, databases, and storage services without needing to move or replicate the data into a single location.
Key Aspects of Federated Queries:
Multiple Data Sources: They can access data from various sources like relational databases, NoSQL databases, object storage, etc.
Real-Time Access: Federated queries provide real-time access to data where it lives, eliminating the need to ETL (Extract, Transform, Load) data into a single repository.
Unified View: They offer a unified view of data across different repositories, facilitating complex analyses and insights that span across these sources.
Amazon Athena and Lambda for Federated Queries
Amazon Athena uses data source connectors, such as those based on AWS Lambda, to execute federated queries. A data source connector is a piece of code that can translate between your target data source and Athena. You can think of a connector as an extension of Athena's query engine. Prebuilt Athena data source connectors exist for data sources like Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB, and Amazon RDS, and JDBC-compliant relational data sources such MySQL, and PostgreSQL under the Apache 2.0 license. You can also use the Athena Query Federation SDK to write custom connectors.
For a list of data source connectors written and tested by Athena, see Available data source connectors.
For information about writing your own data source connector, see Example Athena connector on GitHub.
Here’s how it works:
Lambda-Based Data Source Connectors: These connectors are essentially Lambda functions that Athena invokes to access data from non-native sources. Developers can write Lambda functions to query different data sources like MongoDB, ElastiCache, DocumentDB, Elasticsearch, or even third-party services.
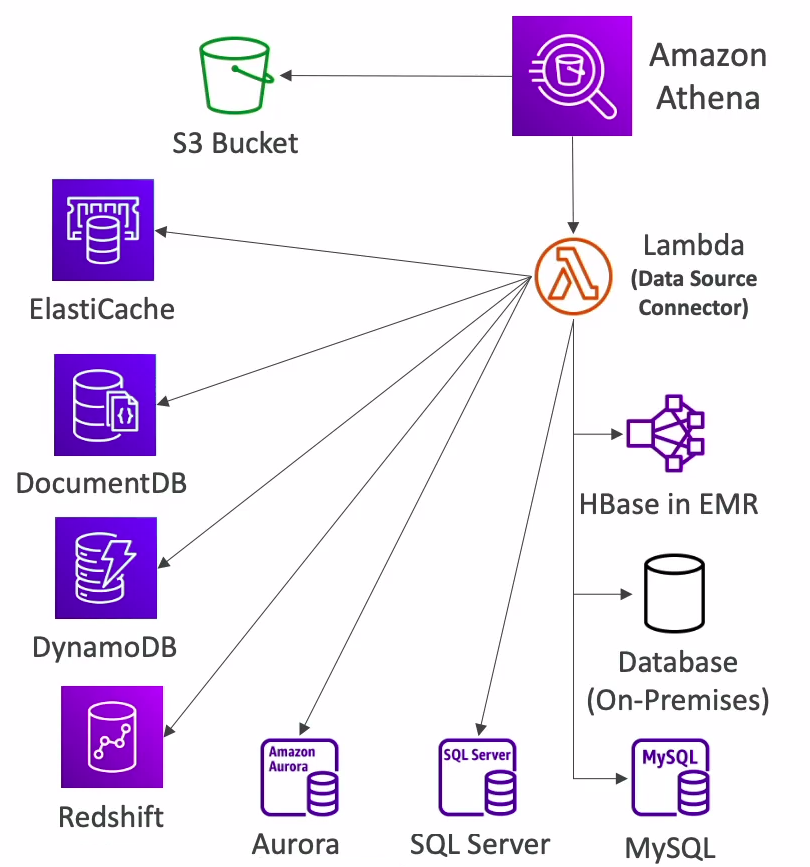
Registration with Athena: The connectors are registered with Athena, which then treats them as additional data sources.
Query Execution: When a federated query is executed, Athena calls the appropriate Lambda function based on the data source specified in the SQL query.
Data Retrieval and Processing: The Lambda function retrieves data from the target data source, processes it as necessary (like filtering or formatting), and returns it to Athena.
Combining Results: Athena can then combine this data with other data (for example, data stored in Amazon S3) and return the unified result set to the user or store the results in S3 bucket.
SQL Interface: The entire process is transparent to the user, who interacts with Athena using standard SQL.
Advantages
Extend Athena’s Capabilities: This approach significantly extends Athena’s querying capabilities beyond AWS-native services.
Flexibility: It provides a flexible framework to query diverse data sources.
Cost-Effective: Federated queries can be more cost-effective than moving large volumes of data into a single data store.
Use Cases
Cross-Domain Analytics: For businesses that store different types of data across various systems (like CRM, ERP, and custom databases).
Real-Time Reporting: For scenarios requiring real-time reporting and analytics across disparate data sources.
By using Lambda functions as data source connectors, Amazon Athena empowers users to perform federated queries, seamlessly accessing and combining data from a wide range of sources, thereby offering a powerful tool for complex data analysis in a distributed data environment.
Tutorial: Query data from S3 bucket by using Amazon Athena
Using Amazon Athena involves several basic steps, starting from setting up your AWS environment to running your first SQL query. Here's a step-by-step tutorial:
Prerequisites
An AWS account. If you don't have one, you can sign up for a free tier account on the AWS website.
Data stored in Amazon S3. For this tutorial, we'll assume you have some data in CSV format stored in an S3 bucket.
Date,Sales,Cost,Profit 2023-01-01,200,80,120 2023-01-02,150,60,90 2023-01-03,300,120,180 2023-01-04,250,100,150Save the file with a
.csvextension, for example,sample_data.csv.
Step 1: Set Up Your S3 Bucket
Log in to the AWS Management Console and navigate to Amazon S3.
Create a new bucket or use an existing one where your data is stored.

Upload your data file (e.g., a CSV file) to the bucket.

Create a new bucket to store the results of Athena queries.

Step 2: Set Up IAM Permissions
Navigate to the IAM Management Console in AWS.
Create a new policy or use the managed policy that allows access to your S3 bucket and Athena services.
Attach this policy to your user or group to ensure you have the necessary permissions to run queries in Athena.
For more information on IAM policies for Athena and S3, please refer to the following resources:
Identity and access management in Athena: https://docs.aws.amazon.com/athena/latest/ug/security-iam-athena.html
Access to Amazon S3: https://docs.aws.amazon.com/athena/latest/ug/s3-permissions.html
AWS managed policies for Amazon Athena: https://docs.aws.amazon.com/athena/latest/ug/managed-policies.html
Step 3: Set Up Athena
Go to the Athena service in the AWS Management Console.
Set up a query result location in S3. This is where Athena will save the results of your queries.
In the Athena console, go to Query Editor --> Manage Settings and specify an S3 bucket for the query results.

Step 4: Create a Database and Table
In the Athena Query Editor, start by creating a new database:
CREATE DATABASE my_test_database;
Next, create a table that corresponds to the structure of your CSV data:
CREATE EXTERNAL TABLE IF NOT EXISTS my_test_database.my_table ( Date DATE, Sales INT, Cost INT, Profit INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION 's3://your-bucket-name/path-to-your-csv/';Replace
column1_name,column2_name, etc., with your actual column names and data types.Replace
's3://your-bucket-name/path-to-csv-data/'with the path to your CSV file in S3.
Step 5: Run Your First Query
Now that your database and table are set up, you can run a SQL query against your data:
SELECT * FROM my_test_database.my_table LIMIT 4;This query will display the first 4 rows of your table.

Step 6: Example of an advanced SQL query.
For a more complex SQL query using Amazon Athena on the sample CSV data, let's consider a scenario where you might want to gain deeper insights from your data. The sample CSV file contains columns for Date, Sales, Cost, and Profit. Here's a more complex query example:
Query Objective
Let's say you want to analyze the following:
Total Sales, Cost, and Profit for each week.
Average Daily Profit within each week.
A comparison of weekly profit to the previous week's profit.
SQL Query
The query will involve date functions, aggregation, and window functions. Here’s how you can structure it:
WITH WeeklyAnalysis AS (
SELECT
DATE_TRUNC('week', Date) as WeekStart,
SUM(Sales) as TotalSales,
SUM(Cost) as TotalCost,
SUM(Profit) as TotalProfit,
AVG(Profit) as AvgDailyProfit
FROM
my_test_database.my_table
GROUP BY
DATE_TRUNC('week', Date)
)
SELECT
WeekStart,
TotalSales,
TotalCost,
TotalProfit,
AvgDailyProfit,
TotalProfit - LAG(TotalProfit) OVER (ORDER BY WeekStart) as ProfitChangeFromLastWeek
FROM
WeeklyAnalysis
ORDER BY
WeekStart;

Explanation
WeeklyAnalysisCommon Table Expression (CTE):DATE_TRUNC('week', Date) as WeekStart: This truncates theDateto the start of the week, effectively grouping the data by week.SUM(Sales) as TotalSales,SUM(Cost) as TotalCost,SUM(Profit) as TotalProfit: These calculate the total sales, cost, and profit for each week.AVG(Profit) as AvgDailyProfit: This calculates the average daily profit for each week.
Main Query:
The main query selects all columns from the
WeeklyAnalysisCTE.LAG(TotalProfit) OVER (ORDER BY WeekStart): This window function computes the difference in total profit from the previous week (ProfitChangeFromLastWeek).
Ordering:
- The results are ordered by
WeekStartto show the weekly analysis in chronological order.
- The results are ordered by
This query provides a comprehensive weekly analysis of the data, showing not just total figures but also average daily metrics and week-over-week changes, offering valuable insights for business decision-making.
Step 7: Clean Up
- Remember to delete the S3 buckets and any resources you created if they are no longer needed to avoid incurring unnecessary charges.
This basic tutorial gives you a glimpse into how to use Amazon Athena for querying data stored in S3. You can expand on these steps to explore more complex data analysis, including using partitioned tables, optimizing query performance, and integrating with other AWS services like AWS Glue or Amazon QuickSight for data cataloging and visualization.
References:
Subscribe to my newsletter
Read articles from Maxat Akbanov directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Maxat Akbanov
Maxat Akbanov
Hey, I'm a postgraduate in Cyber Security with practical experience in Software Engineering and DevOps Operations. The top player on TryHackMe platform, multilingual speaker (Kazakh, Russian, English, Spanish, and Turkish), curios person, bookworm, geek, sports lover, and just a good guy to speak with!