Find page and image links with getAttribute() in Selenium
 Debasmita Adhikari
Debasmita AdhikariUsing linkText() and partialLinkText() :
In Selenium WebDriver API, we have these locator strategies to locate a link and manipulate them. It could be buttons or navigation menu etc. Only condition is that these links must have visible text and an anchor <a> tag associated with them.
For example, let's find all links available on the google landing page:
public class FindLinksOnPage {
public static void main(String[] args) {
WebDriver driver = new EdgeDriver();
driver.get("https://www.google.com/");
//to find all links :
List<WebElement> allLinks = driver.findElements(By.tagName("a"));
System.out.println("Total links available : " + allLinks.size());
for(WebElement e : allLinks) {
System.out.println(e.getText());
}
}
}
And the output looks as below :

Few links do not have a text. Let's see the below code where we try to find the links using linkText() and partialLinkText() methods :
public class FindLinksOnPage {
public static void main(String[] args) {
WebDriver driver = new EdgeDriver();
driver.get("https://www.google.com/");
//to find the Gmail link
String gmailLink =
driver.findElement(By.linkText("Gmail")).getText();
//to find a link with long text
String longTextLink =
driver.findElement(By.partialLinkText("På vej")).getText();
System.out.println(gmailLink);
System.out.println(longTextLink);
}
} // we could do any kind of element manipulation e.g. getText() or click() etc.
The output will be :

Using getAttribute() method :
Usually we have href (url), target (whether a link will open in same tabor new tab etc.), title(text value) etc. attributes associated with a link on the DOM under the anchor tag. Let's find the href values for above links , we have used the getAttribute("href") after finding the elements :
public class FindLinksOnPage {
public static void main(String[] args) {
WebDriver driver = new EdgeDriver();
driver.get("https://www.google.com/");
//to find all links :
List<WebElement> allLinks = driver.findElements(By.tagName("a"));
System.out.println("Total links available : " + allLinks.size());
for(WebElement e : allLinks) {
System.out.println(e.getText() + " ------ " +
e.getAttribute("href"));
}
}
}
The output will be :
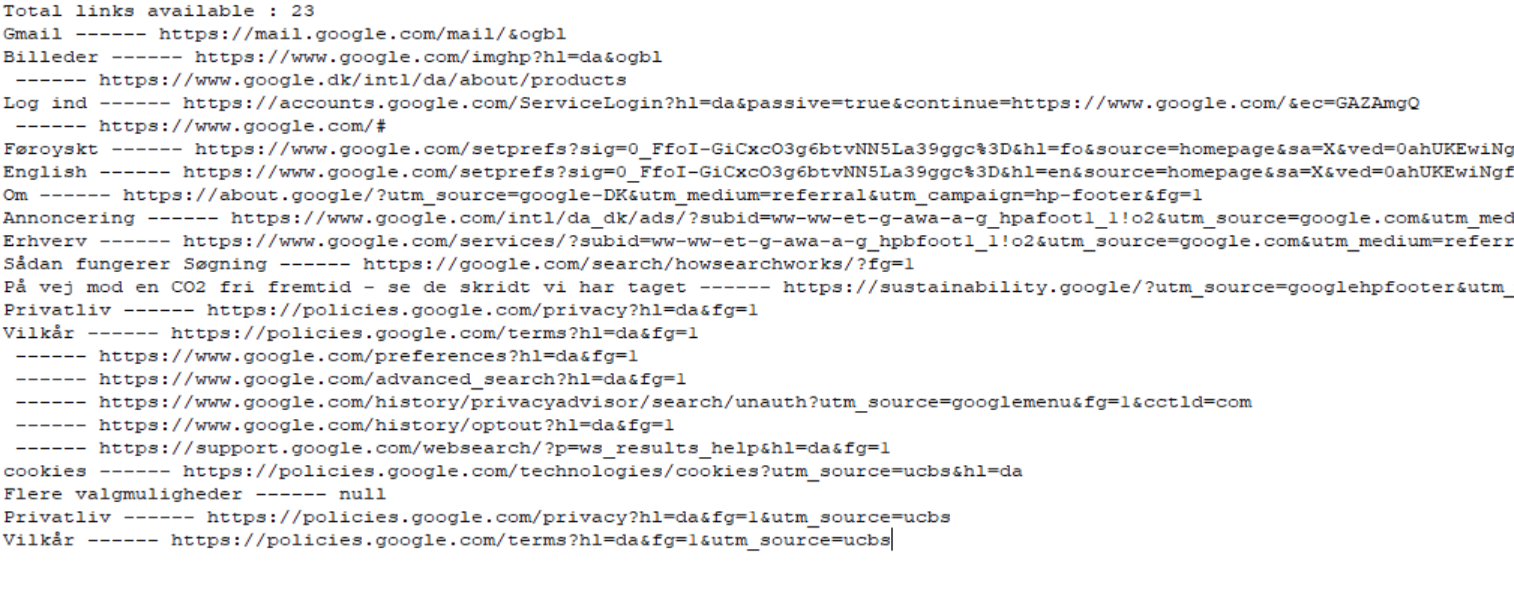
We have href values for all those links that do not have a text associated with them. If we have a url of a link that do not have a text, we could find it as below :
public class FindLinksOnPage {
public static void main(String[] args) {
WebDriver driver = new EdgeDriver();
driver.get("https://www.google.com/");
//to find all links :
List<WebElement> allLinks = driver.findElements(By.tagName("a"));
for(WebElement e : allLinks) {
if(e.getAttribute("href").contains("advanced_search")) {
System.out.println(e.getAttribute("href"));
e.click();
break;
}
}
}
}
Handling image elements :
An image on the page will be defined with the image tag <img\> on the DOM. It might have properties like alt (alternate image name as text), src (image source url), height, width etc. In Selenium, we do not have any methods specifically to find an image on the page. We have to use the getAttribute() method as below :
public class HandlingImageLinks {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
driver.get("https://www.amazon.de/");
List<WebElement> allImages = driver
.findElements(By.tagName("img"));
System.out.println("Total images : " + allImages.size());
for(WebElement e : allImages) {
System.out.println("Image name :: "
+ e.getAttribute("alt") + " ======= " +
"Image source :: "
+ e.getAttribute("src"));
}
}
} //this will print both the image names and their sources
The output will be : Not all images have an "alt" value.
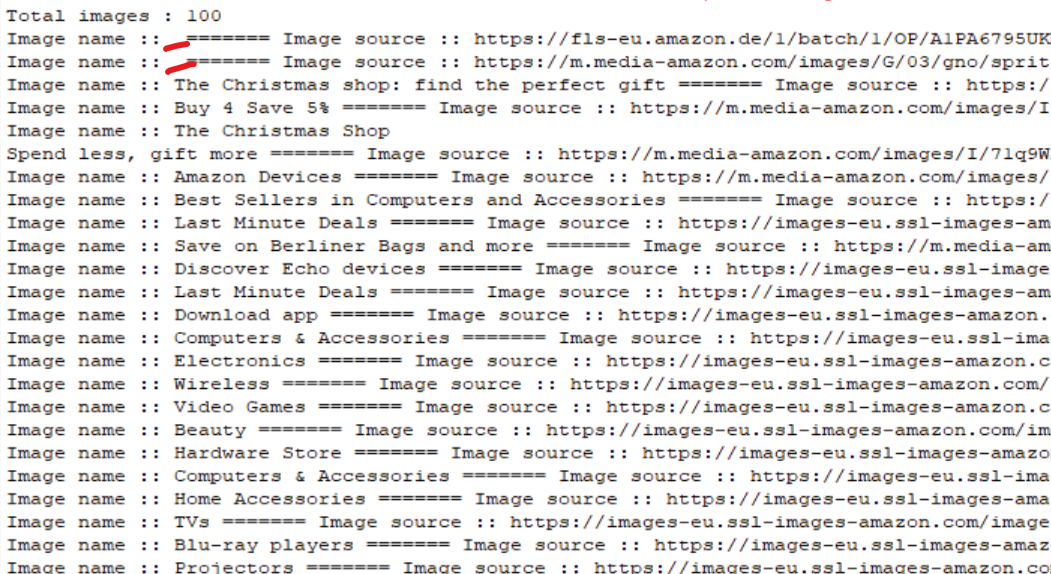
Subscribe to my newsletter
Read articles from Debasmita Adhikari directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Debasmita Adhikari
Debasmita Adhikari
I am a software engineer with interest in Automated testing. I am here to share my learning experiences.