What is star schema?
 Sweta_Sarangi
Sweta_Sarangi
A star schema is a multi-dimensional data model designed to facilitate the organization, understanding, and analysis of data within a database. It is applicable to various data management tools such as data warehouses, databases, data marts, and others. The structure of a star schema is specifically tailored for efficient querying of substantial datasets.
Originally introduced by Ralph Kimball in the 1990s, star schemas excel in data storage, historical record-keeping, and data updating. They achieve this by minimizing the duplication of recurring business definitions, enabling swift aggregation, and streamlined data filtering within the data warehouse.
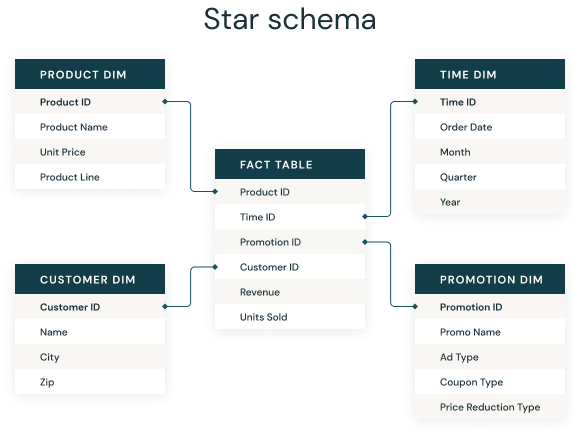
Courtesy: google
Facts Table and Dimension Table
The star schema serves to de-normalize business data by organizing it into dimensions, such as time and product, and facts, including transaction details like amounts and quantities.
At its core, a star schema features a central fact table holding business facts like transaction amounts and quantities. This fact table establishes connections with various dimension tables based on dimensions like time or product. This design empowers users to flexibly analyze data by slicing and dicing it according to their preferences. It often involves joining multiple fact tables and dimension tables together for comprehensive insights.
Denormalized Data
Star schemas involve the denormalization of data, incorporating redundant columns into specific dimension tables to enhance query speed and streamline data manipulation. The objective is to sacrifice some data model redundancy for improved query efficiency, circumventing resource-intensive join operations.
Within this framework, the fact table undergoes normalization, retaining data solely within the fact table, while the dimension tables remain in a denormalized state, allowing for the presence of redundant data.
Benefits of star schema
Fact/dimensional models like star schemas are simple to understand and implement, and make it easy for end users to find the data they need. They can be applied to data marts and other data resources.
Great for simple queries because of their reduced dependency on joins when accessing the data, as compared to normalized models like snowflake schemas.
Adapt well to fit OLAP models.
Improved query performance as compared to normalized data, because star schemas attempt to avoid computationally expensive joins.
How does a star schema work?
The fact table stores two types of information: numeric values and dimension attribute values. Using a sales database as an example:
Numeric value cells are unique to each row or data point and do not correlate or relate to data stored in other rows. These might be facts about a transaction, such as an order ID, total amount, net profit, order quantity or exact time.
The dimension attribute values do not directly store data, but they store the foreign key value for a row in a related dimensional table. Many rows in the fact table will reference this type of information. So, for example, it might store the sales employee ID, a date value, a product ID or a branch office ID.
Dimension tables store supporting information to the fact table. Each star schema database has at least one dimension table, but will often have many. Each dimension table will relate to a column in the fact table with a dimension value, and will store additional information about that value.
Star Schema Use cases
Star Schema databases are best used for historical data.
This makes them work most optimally for data warehouses, data marts, BI use and OLAP. Primarily read optimized, star schemas will deliver good performance over large data sets. Organizations can also tailor them to provide their best performance along the specific criteria considered the most important or most used to query against. Data can be added transactionally as it comes in, or it can be batch imported then checked and properly denormalized at that time.
Star schema database structures are generally not a good fit for live data, such as in online transaction processing. Their denormalized nature imposes restrictions that a fully normalized database does not. For example, slow writes to a customer order database could cause a slowdown or overload during high customer activity. This potential for data abnormalities could be disastrous in a live order fulfillment system.
SWETA SARANGI
14-12-2023
Subscribe to my newsletter
Read articles from Sweta_Sarangi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by