Exploring Database Indexes
 Surabhi Suman
Surabhi Suman
Why Indexes?
Database indexes are used for faster data retrieval. Let's explore the underlying data structure behind these indexes that enables faster queries.
Hash Index
This is a log based index and probably simpler and easiest to implement. It stores data in key value pair format in an append only file. When the file size grows it just moves to storing data in a different file. Compaction happens in the background asynchronously. Compaction is the process of merging two files and using the latest one as the trusted and updated source of data.
SSTable
SSTable is Sorted string table. Similar to hash index, it also stores key-value pairs in an append only segment file but in a sorted order sorted by key. Compaction also happens in the background on a regular interval.
How does it maintain sorted order in a segment file?
It uses any sorted data structure like Red Black Tree or AVL tree to keep keys in sorted order.
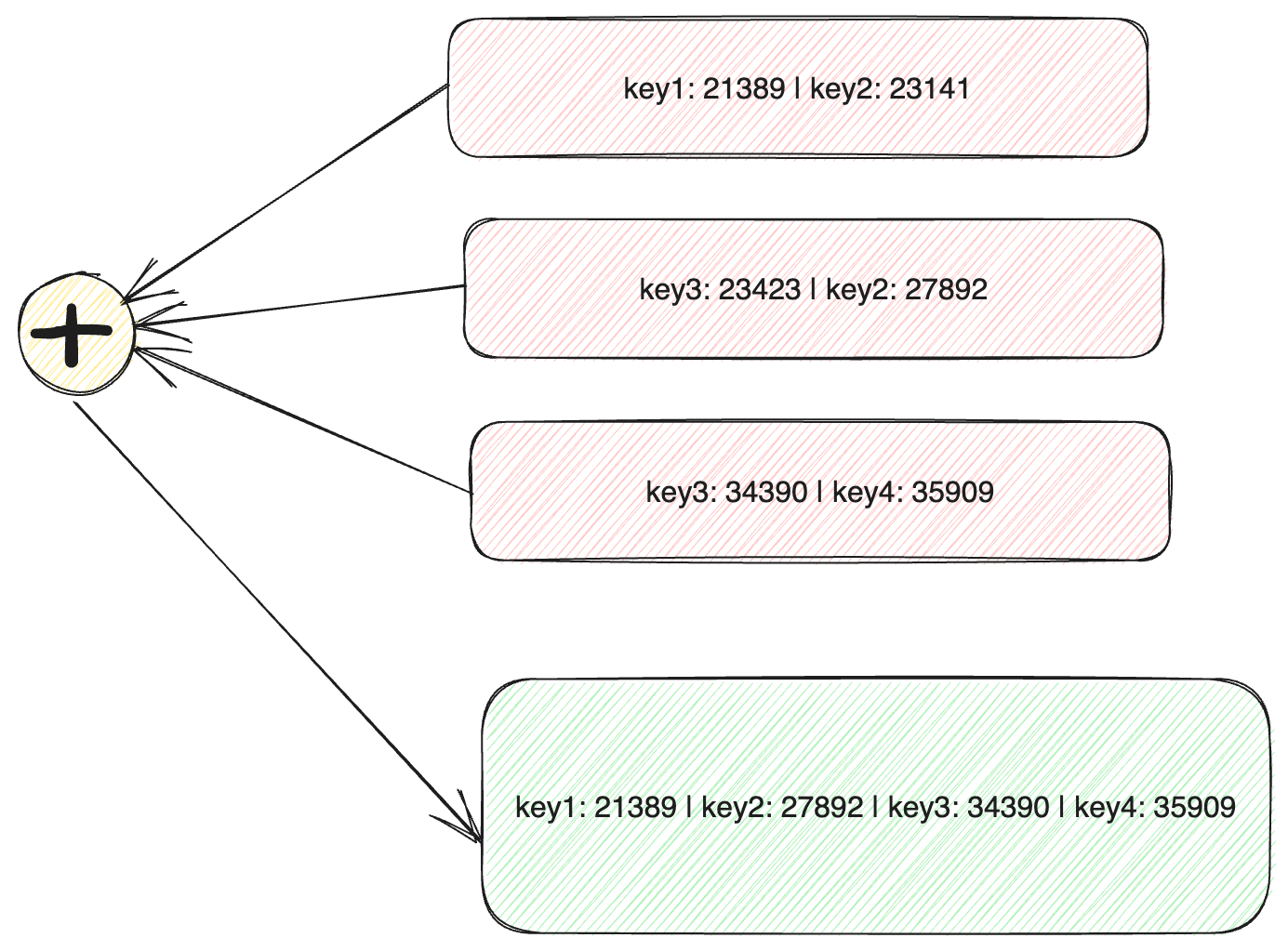
How compaction works?
SSTable make writes faster by appending data in an append only segment file. On files reaching a certain limit, new writes are done on new segment file. Compaction takes values from latest segment file and rejects values from old segement files in case of repeated keys. Since SSTables are already sorted, merging is faster as well with help of any sorting algorithm like merge sort.
Searching
For searching any key in SSTable, we need two offsets to begin with. For e.g. if we’ve to search for offset value for key10 and we’ve got offset values for key 2 and key 15, we can just use binary search to search within the SSTable since the values inside the table are sorted by key. Generally a sparse in memory index is also kept which keeps offset values for random keys to help with the binary search process.

Deletion
Deletion is worth mentioning for LSM trees as this might be the only case where deletion actually takes extra space. Since no in place updates are allowed in segment files(append only files), if a key pair is deleted, we just add a tombstone value to the key name and while merging/compaction it reads the value as tombstone and does not carry it forward in the merged segment.
LSM Tree
LSM tree is log structured merge tree which is essentially the algorithm we just described earlier. Searching works in the same way as above, however worst case complexity is still high in LSM tree, going through sparse index and going all the way to all on-disk SSTables. Further optimizations in LSM tree are made by introducing a bloom filter. So search is first made in bloom filter, then it goes to LSM tree.
BTree
BTree is a balanced tree. It possesses the properties of a n-ary binary tree with a twist that it balances itself on every insert, delete, and update.
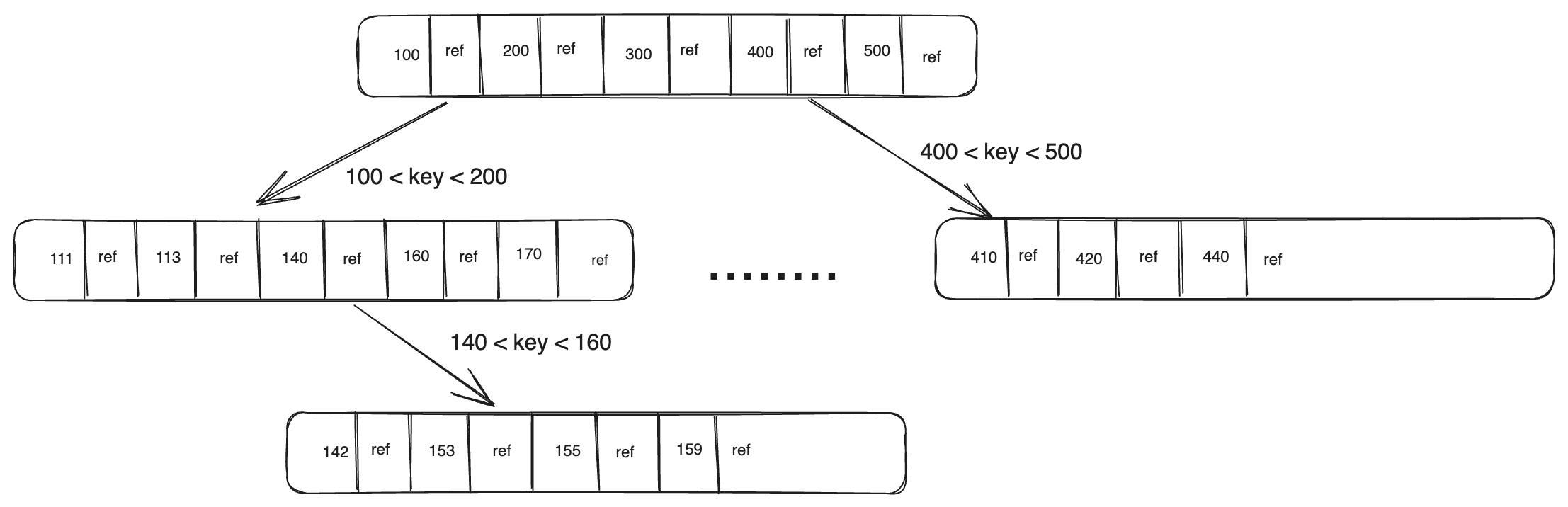
Each node in B-tree actually represents a page on disk. Contrast to LSM tree which divides disk into segments, B-tree splits and divides it’s data between nodes (pages) of fixed size. Insertions are slower than LSM tree but lookups are faster. B-tree also keep a WAL (Write Ahead Logs) which is an append only log file for data recovery in case of crash e.g. failure to update/add a value in the tree due to server restart or network failures. B-tree can again be reconstructed using that WAL.
B+ Tree
This is just an improved version of B tree in a sense that instead of storing references right next to the keys making the nodes heavier, it stores all the references at the leaf node. Makes range queries much faster.
Other indexes
Clustered index - Some indexes prefer keeping actual all row data in the value for key while some prefer keeping references to actual row data in the key while indexing data, the former one is known as clustered index.
Covering index - It is a mid-way between clustered and non clustered index. It stores values for some cloumns of the row and also the reference to original row. This allows some queries to be answered just by looking at the index and for more data, we can refer to the actual values.
Multi-column indexes - This is required for querying multiple columns of a table. E.g. if we’ve to filter out restaurants that lie within a given lat, lon values.
Most common multi column index is concatenated index, R-tree is also one of the multi column index.
Column oriented storage
→ In case of repetitive data in columns, mostly occurring due to joining tables or merging data from different sources e.g. in case of analytics data table, there is a lot of repetitive data if we just looks at the columns. Some analytics DB, store columns seperately in another table and just keep references in the main table. Further compression can be done on columns e.g. in case of number values, sparse values can be represented in a better way to save storage.
Subscribe to my newsletter
Read articles from Surabhi Suman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Surabhi Suman
Surabhi Suman
Hey! I am a software engineer by profession. Passionate about Ruby, Database internals, optimization, distributed systems