Advent of Cyber 2023 — Day 14 Writeup
 Anuj Singh Chauhan
Anuj Singh ChauhanScenario
The CTO has made our toy pipeline go wrong. By infecting elves at key positions in the toy-making process, he has poisoned the pipeline and caused the elves to make defective toys!
McSkidy has started to combat the problem by placing control elves in the pipeline. These elves take measurements of the toys to try and narrow down the exact location of problematic elves in the pipeline by comparing the measurements of defective and perfect toys. However, this is an incredibly tedious and lengthy process, so he’s looking to use machine learning to optimize it.
Learning Objectives
What is machine learning?
Basic machine learning structures and algorithms
Using neural networks to predict defective toys
Concept
Introduction
Over the last decade, there has been a massive boom in artificial intelligence (AI) and machine learning (ML) systems.
Just in the last couple of years, the release of ChatGPT has taken the world by storm. However, how these systems actually work is often shrouded in mystery, leading to a lot of snake oil sales tactics.
In this task, we will provide you with a glimpse into the world of ML to help demystify this incredibly interesting topic. We will create our very own neural network that can be used to detect defective toys!
Zero to Hero on Artificial Intelligence
Before we can create our own AI, we need to learn some of the basics. First of all, let’s discuss the two terms.
The term AI is used in broad strokes out there in the world — often incorrectly. We have to be honest with ourselves — AI can’t just be a bunch of “if” statements.
A better term to use is machine learning. ML refers to the process used to create a system that can mimic the behaviour we see in real life. This is because there is intelligence in real life and its structures. The field is incredibly broad, but here are a couple of popular examples:
Genetic algorithm: This ML structure aims to mimic the process of natural selection and evolution. By using rounds of offspring and mutations based on the criteria provided, the structure aims to create the “strongest children” through “survival of the fittest”.
Particle swarm: This ML structure aims to mimic the process of how birds flock and group together at specific points. By creating a swarm of particles, the structure aims to move all the particles to the optimal answer’s grouping point.
Neural networks: This ML structure is by far the most popular and aims to mimic the process of how neurons work in the brain. These neurons receive various inputs that are then transformed before being sent to the next neuron. These neurons can then be “trained” to perform the correct transformations to provide the correct final answer.
There are many more ML structures, but we’ll stick to neural networks for this task, as they are the most popular. And, while there’s a significant amount of maths involved in implementing an ML structure, we’ll be abstracting this information. If you want to learn more, you can start here (this is where I started) and then work your way up!
Learning Styles
First on our list of ML basics to cover is the neural network’s learning style. In order to train our neural network, we need to decide how we’ll teach it. While there are many different styles and subsets of styles, we will only focus on the two main styles for now:
Supervised learning: In this learning style, we guide the neural network to the answers we want it to provide. We ask the neural network to give us an answer and then provide it with feedback on how close it was to the correct answer. In this way, we are supervising the neural network as it learns. However, to use this learning style, we need a dataset where we know the correct answers. This is called a labelled dataset, as we have a label for what the correct answer should be, given the input.
Unsupervised learning: In this learning style, we take a bit more of a hands-off approach and let the neural network do its own thing. While this sounds very strange, the main goal is to have the neural network identify “interesting things”. Humans are quite good at most classification tasks — for example, simply looking at an image and being able to tell what colour it is. But if someone were to ask you, “Why is it that colour?” you would have a hard time explaining the reason. Humans can see up to three dimensions, whereas neural networks have the ability to work in far greater dimensions to see patterns. Unsupervised learning is often used to allow neural networks to learn interesting features that humans can’t comprehend that can be used for classification. A very popular example of this is the restricted Boltzmann machine. Have a look here at the weird features the neural network learned to classify different digits.
For this task, we will focus on supervised learning. It’s an easier learning style for learning the basics, including the basic network structure.
Basic Structure
Next on our list of ML basics to learn is the basic structure of a neural network. Sticking to the very basics of ML, a neural network consists of various different nodes
Input layer: This is the first layer of nodes in the neural network. These nodes each receive a single data input that is then passed on to the hidden layer. This means that the number of nodes in this layer always matches the network’s number of inputs (or data parameters). For example, if our network takes the toy’s length, width, and height, there will be three nodes in the input layer.
Output layer: This is the last layer of nodes in the neural network. These nodes send the output from the network once it has been received from the hidden layer. Therefore, the number of nodes in this layer will always be the same as the network’s number of outputs. For example, if our network outputs whether or not the toy is defective, we will have one node in the output layer for either defective or not defective (we could also do it with two nodes, but we won’t go into that here).
Hidden layer: This is the layer of nodes between the neural network’s input and output layers. With a simple neural network, this will only be one layer of nodes. However, for additional learning opportunities, we could add more layers to create a deep neural network. This layer is where the neural network’s main action takes place. Each node within the neural network’s hidden layer receives multiple inputs from the nodes in the previous layer and will then transmit their answers to multiple nodes in the next layer.
Feed-Forward Loop
The feed-forward loop is how we send data through the network and get an answer on the other side. Once our network has been trained, this is the only step we perform. At this point, we stop training and simply want an answer from the network. To complete one round of the feed-forward step, we have to perform the following:
Normalise all of the inputs: To allow our neural network to decide which inputs are most important in helping it to decide the answer, we need to normalise them. As mentioned before, each node in the network tries to keep its answer between 0 and 1. If we have one input with a range of 0 to 50 and another with a range of 0 to 2, our network won't be able to properly consume the input. Therefore, we normalise the inputs first by adjusting them so that their ranges are all the same. In our example here, we would take the inputs with a 0 to 50 range and divide all of them by 25 to change their ranges to 0 to 2.
Feed the inputs to our nodes in the input layer: Once normalised, we can provide one data entry for each input node in our network.
Propagate the data through the network: At each node, we add all the inputs and run them through the activation function to get the node's output. This output then becomes the input for the next layer of nodes. We repeat this process until we get to our network's output layer.
Read the output from the network: At the output layer of the network, we receive the output from our nodes. The answer will be a decimal between 0 and 1, but, for decision-making, we'll round it to get a binary answer from each output node.
Back-Propagation
When we are training our network, the feed-forward loop is only half of the process. Once we receive the answers from our network, we need to tell it how close it was to the correct answer. This is the back-propagation step. Here, we perform the following steps:
Calculate the difference in received outputs vs expected outputs: As mentioned before, the activation function will provide a decimal answer between 0 and 1. Since we know that the answer has to be either 0 or 1, we can calculate the difference in the answer. This difference tells us how close the neural network was to the correct answer.
Update the weights of the nodes: Using the difference calculated in the previous step, we can start to update the weights of each input to the nodes in the output layer. We won't dive too deep into this update process, as it often involves a bit of complex maths to decide what update should be made.
Propagate the difference back to the other layers: This is where the term back-propagation comes from. Once the weights of the nodes in the output layer have been updated, we can calculate what the difference would be for the previous nodes. Once again, this difference is then used to update the weights of the nodes in that layer before being propagated backwards even more. We continue this process of back-propagation until the weights for the input layer have been updated.
Once all the weights have been updated, we can run another sample of data through our network. We repeat this process with all our samples in order to train our network.
Dataset Splits
The last topic to cover before we can build our network is dataset splits. Let's use an analogy to explain this. Let's say your teacher constantly tells you that 1+1 = 2 and 2+2 = 4. But, in the exam, your teacher asks you to calculate 3+3. The question here is:
Have you just learned what the answer is, or did you learn the fundamental principle required to get to the answer?
In short, you can overtrain yourself by learning the answers instead of learning the required principle itself. The same thing can happen with neural networks!
Overtraining is a big problem with neural networks. We are training them with data where we know the answers, so it's possible for the network to simply learn the answers, not how to calculate the answer. To combat this, we need to validate that our neural network is learning the process and not the answers. This validation also tells us when we need to stop our learning process. To perform this validation, we have to split our dataset into the three datasets below:
Training data: This is our largest dataset. We use it to train the network. Usually, this is about 70–80% of the original dataset.
Validation data: This dataset is used to validate the network's training. After each training round, we send this data through our network to determine its performance. If the performance starts to decline, we know we're starting to overtrain and should stop the process. Usually, this is about 10–15% of the original dataset.
Testing data: This dataset is used to calculate the final performance of the network. The network won't see this data at all until we are done with the training process. Once training is complete, we send through the testing dataset to determine the performance of our network. Usually, this is about 10–15% of the original dataset.
Now you know how a basic neural network works, so it's time to build our own!
What is the other term given for Artificial Intelligence or the subset of AI meant to teach computers how humans think or nature works?
Answer: machine learning
What ML structure aims to mimic the process of natural selection and evolution?
Answer: genetic algorithm
What is the name of the learning style that makes use of labelled data to train an ML structure?
Answer: supervised learning
What is the name of the layer between the Input and Output layers of a Neural Network?
Answer: hidden layer
What is the name of the process used to provide feedback to the Neural Network on how close its prediction was?
Answer: back-propagation
What is the value of the flag you received after achieving more than 90% accuracy on your submitted predictions?
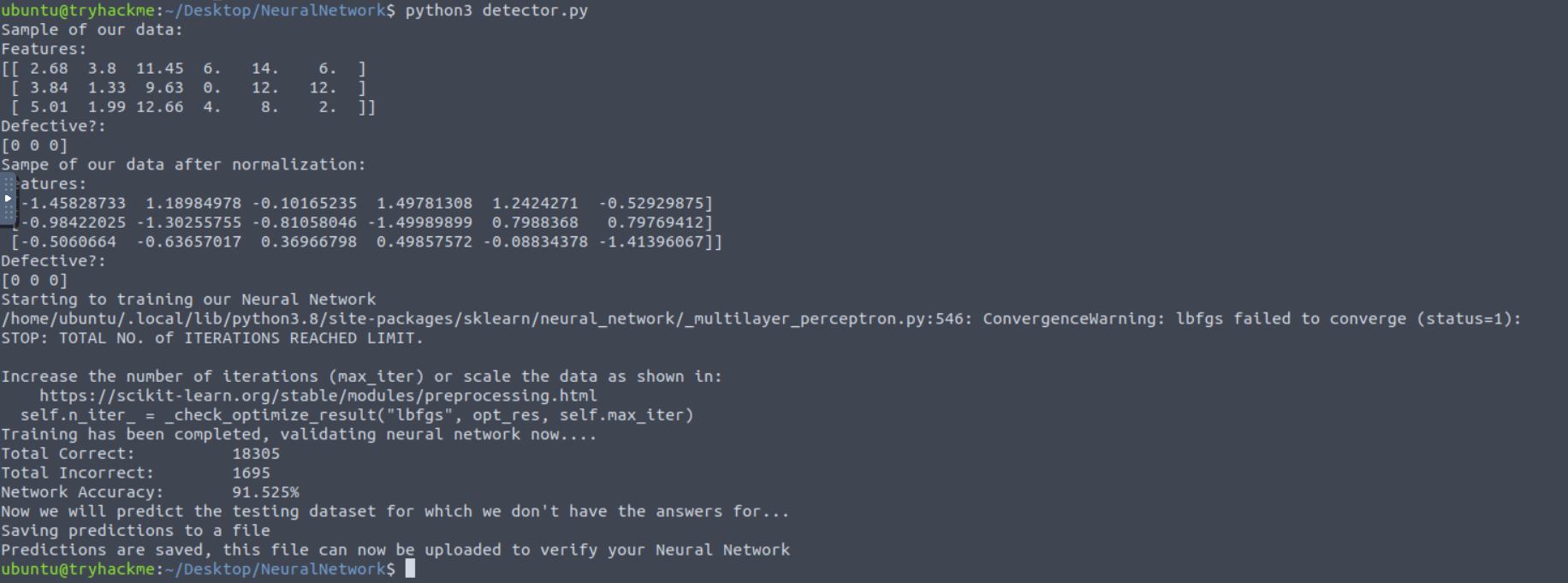
then upload the prediction file on http://websiteforpredictions.thm:8000/
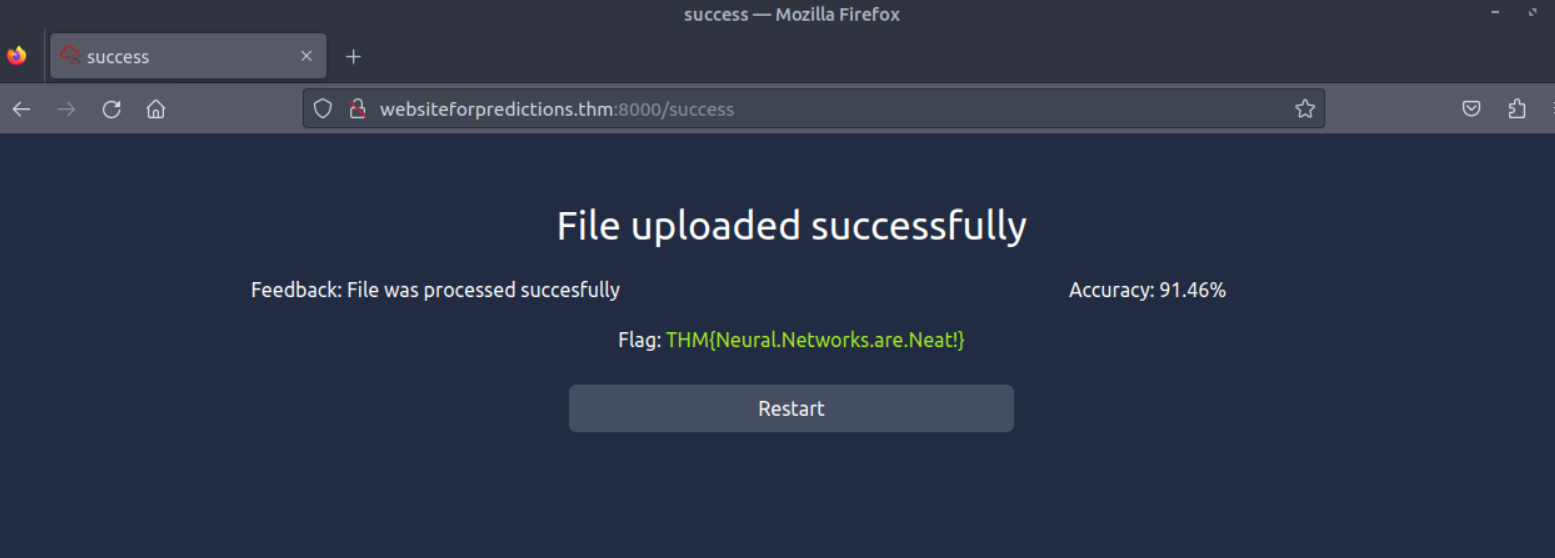
Answer: THM{Neural.Networks.are.Neat!}
thanks for reading!!
Subscribe to my newsletter
Read articles from Anuj Singh Chauhan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by