Quarkus: Database Projection with Panache
 Tug Grall
Tug Grall
Welcome back to the second installment of our exploration into Quarkus and Panache! In the previous blog post, we delved into setting default values for Panache entity fields. Now, as we continue refining the WindR.org website with Quarkus integration, our primary focus shifts to implementing Database Projection with Panache.
Code Example on GitHub:
To accompany this discussion, I've published the complete code example on GitHub, providing you with a hands-on reference for learning and experimentation.
GitHub Repository: Learning Quarkus: Database Projection with Panache
Understanding the data model
For this illustrative example, we'll work with a straightforward data model consisting of two tables: 'boards' and 'brands.' The 'boards' table contains a list of windsurfing boards, while the 'brands' table serves as a reference, linked to the 'boards' table through a foreign key relationship.
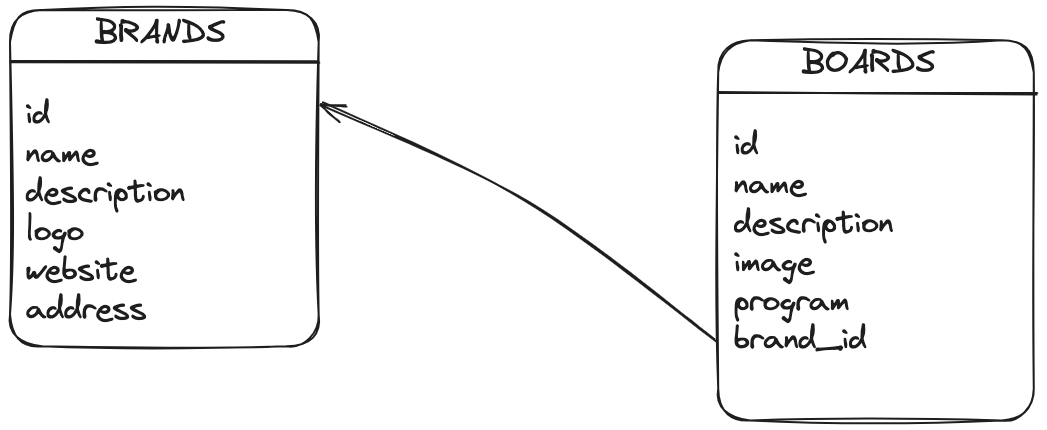
Panache Entities:
Let's take a closer look at the Panache entities representing these tables.
Board.java
@Entity
@Table (
name = "boards"
)
public class Board extends PanacheEntity {
@ManyToOne( fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "brand_id", nullable = false, foreignKey = @ForeignKey(name = "fk_board_brand_id"))
public Brand brand;
public String name;
public String description;
public String image;
public String program;
}
Brand.java
@Entity
@Table(
name = "brands"
)
public class Brand extends PanacheEntity {
public String name;
public String description;
public String logo;
public String website;
public String address;
}
Database Schema
These entities are mapped to the following database tables, reflecting the relational structure:
create table boards (
id bigint not null,
description varchar(255),
image varchar(255),
name varchar(255),
program varchar(255),
brand_id bigint not null,
primary key (id)
);
create table brands (
id bigint not null,
address varchar(255),
description varchar(255),
logo varchar(255),
name varchar(255),
website varchar(255),
primary key (id)
);
alter table if exists boards
add constraint fk_board_brand_id
foreign key (brand_id)
references brands;`
Using the Panache Entities
Now, let's create a new REST endpoint that efficiently returns the list of boards and board details, thanks to the simplicity provided by Quarkus.
BoardResource.java
@Path("/api/v1/boards")
@Produces(MediaType.APPLICATION_JSON)
public class BoardResource {
@GET
public List<Board> allBoards() {
return Board.listAll();
}
@GET
@Path("{id}")
public Board getBoard(Long id) {
return Board.findById(id);
}
}
Testing the REST Endpoint
So we can test the endpoint with the following command:
curl http://localhost:8080/api/v1/boards/0
that returns the following JSON:
{
"id": 0,
"name": "Fanatic Skate",
"brand": {
"id": 0,
"name": "Fanatic",
"description": "Fanatic Description",
"logo": "logo.svg",
"website": "https://www.fanatic.com/",
"address": null
},
"description": "Fanatic Skate Description",
"image": "image.png",
"program": "freestyle"
}
As you can see the JSON contains the full details of the board and brand; and all the columns are loaded from the database, as you can see in the following SQL query:
select
b1_0.id,
b1_0.brand_id,
b2_0.id,
b2_0.address,
b2_0.description,
b2_0.logo,
b2_0.name,
b2_0.website,
b1_0.description,
b1_0.image,
b1_0.name,
b1_0.program
from
boards b1_0
join
brands b2_0
on b2_0.id=b1_0.brand_id
where
b1_0.id=?
So, from the client perspective, it is not very efficient because you are loading the full Brand object from the database, and you are sending all the columns to the client.
A quick & dirty solution
Wait! Before we do that, if the reference table has a very small number of columns, you can use the @JsonIgnoreProperties annotation to exclude some columns from the Brand JSON serialization. For example, if you do not want to return the description, logo, website, and address columns, you can use the following annotation:
@ManyToOne( fetch = FetchType.EAGER, optional = false)
@JoinColumn(name = "brand_id", nullable = false, foreignKey = @ForeignKey(name = "fk_board_brand_id"))
@JsonIgnoreProperties({"description", "logo", "website", "address"})
public Brand brand;
Now when you call the endpoint, you will get the following JSON:
{
"id": 0,
"name": "Fanatic Skate",
"brand": {
"id": 0,
"name": "Fanatic"
},
"description": "Fanatic Skate Description",
"image": "image.png",
"program": "freestyle"
}
So from the client perspective, it is better, but from the server-side, it is not very efficient because you are still loading the full Brand & Boards objects from the database.
Efficient Data Retrieval with Database Projection:
To enhance efficiency, we introduce the concept of a projection—a query returning a subset of columns from the target entity.
I am using Java 21, so lets create a new record named BoardProjection:
record BoardProjection(
Long id,
String name,
String image,
String program,
@ProjectedFieldName("brand.name") String brandName
) { }
The process is straightforward: specify the fields you wish to include, and when referencing a field from a related table, employ the @ProjectedFieldName annotation.
To implement this projection, utilize a PanacheQuery and employ the project method to define the projection.
@GET
public List<BoardProjection> allBoards() {
PanacheQuery<Board> boards = Board.findAll();
return boards.project(BoardProjection.class).list();
}
@GET
@Path("{id}")
public BoardProjection getBoard(Long id) {
PanacheQuery<BoardProjection> boardQuery =
Board.find("id", id).project(BoardProjection.class);
return boardQuery.firstResult();
}
Pretty neat !
Let's look at the API call and SQL query:
curl http://localhost:8080/api/v1/boards/0
JSON Result
{
"id": 0,
"name": "Skate",
"image": "image.png",
"program": "freestyle",
"brandName": "Fanatic"
}
and the SQL query:
select
b1_0.id,
b1_0.name,
b1_0.image,
b1_0.program,
b2_0.name
from
boards b1_0
join
brands b2_0
on b2_0.id=b1_0.brand_id
where
b1_0.id=?
fetch
first ? rows only
By utilizing Panache's simple projection definition with a Java record, our API calls now retrieve only the essential data, optimizing both client and server-side performance.
Conclusion
In this blog post, we've explored the power of Database Projection with Panache in a Quarkus environment. By efficiently selecting specific columns through a projection, we strike a balance between data completeness and performance, ensuring a streamlined experience for both developers and end-users alike.
Feel free to check out the complete code on GitHub, experiment with the examples, and stay tuned for more Quarkus insights in future posts!
Subscribe to my newsletter
Read articles from Tug Grall directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by