Internals of PIPE command in Unix based System
 Adil Shaikh
Adil Shaikh
Pipes allow transfer a data between processes in the first-in-first-out manner (FIFO), and they also allow synchronization of process execution. Their implementation allows processes to communicate even though they do not know what processes are on the other end of the pipe hence results in one-directional communication channels between related processes (often a parent and a child).
Pipes are usually well known from shells, where we use “|” symbol to build command pipelines.
You can think of a pipe as a memory buffer with a byte stream API. Thus, by default, there are no messages or strict boundaries.
Basically pipe is system call and there are 2 of them pipe() and pipe2() (refer man 2 pipe())
From a reader’s perspective, a pipe can return a zero size read (end-of-file, EOF) if all writers close all their write pipe file descriptors. A reader blocks if there is nothing to read until data is available (you can change this by opening a pipe in the nonblocking mode).

Pipes are widely used in shells. The elegance of such an approach is that processes don’t have to know that they use pipes. They continue working with their standard file descriptors (stdin, stdout and stderr) as usual. Developers also don’t need to make any changes in their program’s source code in order to support this concept. It makes the process of connecting 2 programs composite, flexible, fast and reliable.
Internally, a pipe buffer is a ring buffer with slots. Each slot has a size of a PIPE_BUF constant. The number of slots is variableRe, and the default number is 16. So, if we multiply 16 by 4KiB, we can get a default size of 64KiB for a pipe buffer.
A pipe’s system max size limit can be found in the /proc/sys/fs/pipe-max-size

How the pipe's are internally created by shell :
With shells we usually use pipes to connect the stdout and/or the stderr of a process and stdin of another process. For example:
command 1 | command 2
Let's take an sample example and understand how shell connects the below 2 command's internally :
ls -la | wc -l
As we already know, a shell process has three special standard open file descriptors. Thus, all its children inherit them by default because of the fork() syscalls. The following simple program shows how a shell can create a pipe and connect 2 programs. It creates a pipe in the parent process, then makes a fork() call twice in order to run execve() for the ls and wc binaries. Before the execve() calls, the children duplicate the needed standart fd with one of the ends of the pipe.
The entire flow can be visualized as below:
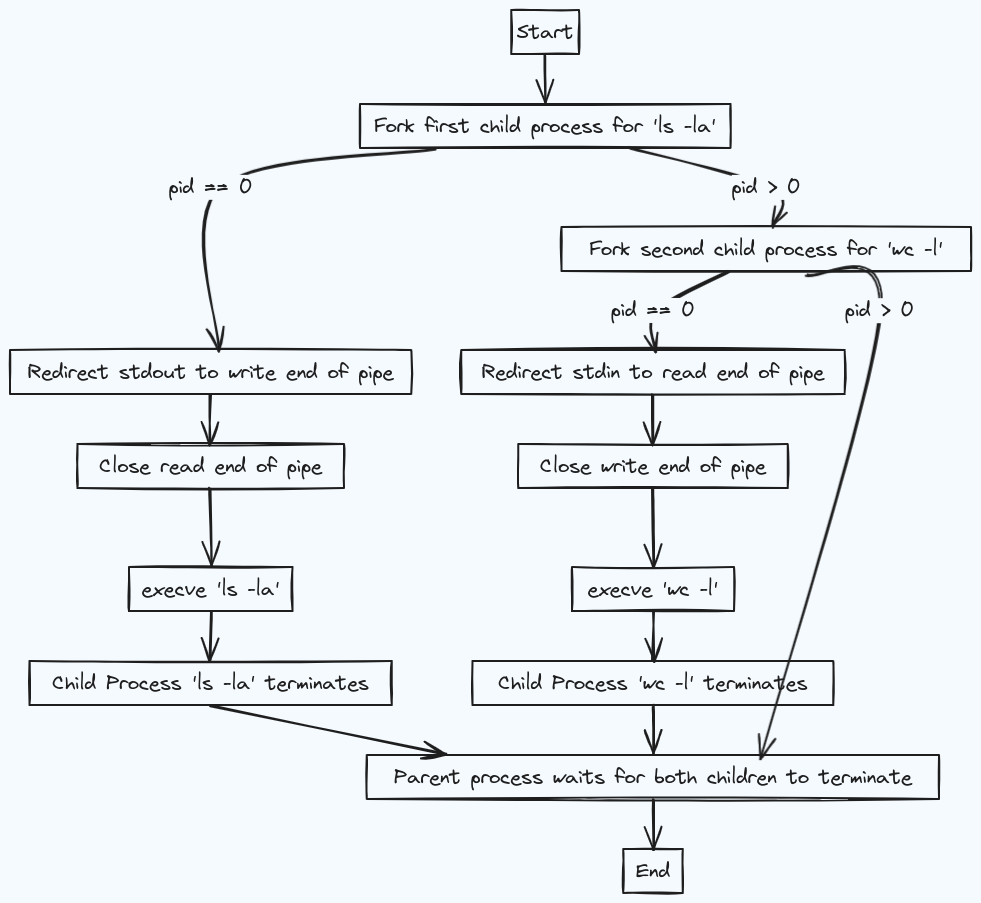
The function's which are used in the entire pipeline are :
if
p == 0i.e the process is child process. And ifp != 0the process is parent process.fork(): create a child processdup(): creates a new fd using the lowest unused int number. It usually follows theclose()syscall for the one of standard fd (stdin,stdout,stderr) in order to replace it.execve():execve()is the only way the Linux kernel can start a new program.
Pipe and Write buffer :
Modern programming languages often buffer all their writes in memory before the actual write syscall executes. The main idea of such buffering is to get better I/O performance.
It’s cheaper to make one big
write()call than several smaller ones.
There are 2 types of buffer that are widely used :
Block buffer : If the block size is 4Mib the buffer will flush out the content to the underlying fd when the buffer is full or when explicitely
flush()call is invoked.Line Buffer : This buffer type flushes its content when the new line character write occurs to the buffer.
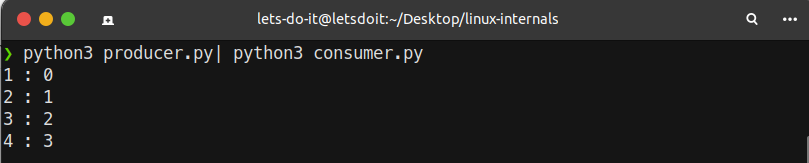
Let’s demonstrate this behavior with 2 scripts connected by a pipe. The first one will print 10 lines to stdout, and the other one will consume these lines from its stdin.
The producer script producer.py :
import time
for i in range(4):
print(f"{i}")
sys.stdout.flush()
time.sleep(0.1)
The consumer script consumer.py :
import fileinput
for i, line in enumerate(fileinput.input()):
print(f"{i+1}: {line.rstrip()}")
if we run these 2 scripts with a pipe, the output is very smooth and stable because of using flush() call in the producer script. Because of which the output is printed in sequential manner and not after the pause of few seconds:
Types of Pipe:
There are two kinds of pipes : named pipes and for sake of simplicity unnamed pipes, which are identical except for the way that a process initially access them.
Named or FIFO pipe : The FIFO file could be helpful when you need to build a connection between completely unrelated programs or daemons without changing their source code.The kernel internally creates the same pipe object and doesn’t store any data on disk.
Unnamed pipe : They are temporary and disappear when the processes using them terminate. They are not accessible to other processes outside of the creating process and its children.
Conclusion:
In conclusion, delving into the intricacies of the UNIX pipe command has provided us with a comprehensive understanding of its internal workings. From the initiation with the fork() command, through the pivotal role played by various commands, such as execve(), the entire pipeline process has been unveiled. This exploration not only demystifies the mechanics behind these commands but also underscores their collaborative synergy in facilitating seamless data flow. As we unravel the layers of UNIX's pipe command, we gain not just technical insights but also a deeper appreciation for the orchestration of commands that enable efficient execution.
Subscribe to my newsletter
Read articles from Adil Shaikh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Adil Shaikh
Adil Shaikh
Adil a final year Computer Science student poised to make a mark in the tech world. With a diverse experience in the field of Cloud ,MLOPS and AWS tool's and technologies, Adil navigates the intersection of academia and real-world tech challenges. Driven by a passion for innovation, Adil expands skills into DevOps, mastering Linux, Docker, and Kubernetes. This journey culminates in securing an internship at AI Planet, specializing in MLOps. Adil's impactful contributions include optimizing GenAI stack deployment with Terraform, Ansible, and implementing creative solutions like KEDA, Prometheus & Grafana to reduce model cold start times. These experiences mark the beginning of a promising career journey for Adil, blending technical prowess with a passion for tackling real-world challenges.