How to Use Sparse Vectors for Medical Data with Qdrant 1.7.0
 Akriti Upadhyay
Akriti Upadhyay
Introduction
In traditional vector databases, which were designed to query only dense vectors, handling sparse vectors posed significant challenges. The inherent sparsity of these vectors, where a majority of dimensions contain zero values, led to inefficient storage and retrieval methods in such databases. However, with the advent of Qdrant 1.7.0, a pioneering update in the vector search engine landscape, querying sparse vectors has become more accessible and efficient.
This release addresses the historical difficulties associated with sparse vectors, allowing users to seamlessly integrate them into their database queries. Qdrant 1.7.0 introduces native support for sparse vectors, revolutionizing the way vector databases handle data representations.

One specific area where this advancement holds immense promise is in the realm of medical data. Sparse medical data, characterized by its often irregular and incomplete nature, has historically posed challenges for traditional vector databases that primarily catered to dense vectors. The introduction of Qdrant 1.7.0 brings a tailored solution to the problem of sparse medical data. By offering efficient querying capabilities for sparse vectors, Qdrant is poised to enhance the exploration and analysis of medical datasets, facilitating more effective and streamlined medical research and decision-making processes.
Let's delve deeper into this subject.
Sparse Vectors: A Comprehensive Overview
A sparse vector is a vector that has mostly zero or empty values, meaning that it has very few non-zero elements compared to its total size. For example, if you have a vector of 10 numbers, and only 3 of them are non-zero, then the vector is sparse. Sparse vectors are useful when you have a lot of data that has a lot of empty or zero values, such as text data or high-dimensional data. Storing all the zeros wastes memory and time, so sparse vectors only store the non-zero values along with their indices. This way, you can save space and speed up operations on sparse vectors. Sparse vectors are useful for representing data that has many categories or features, such as text, images, or graphs.
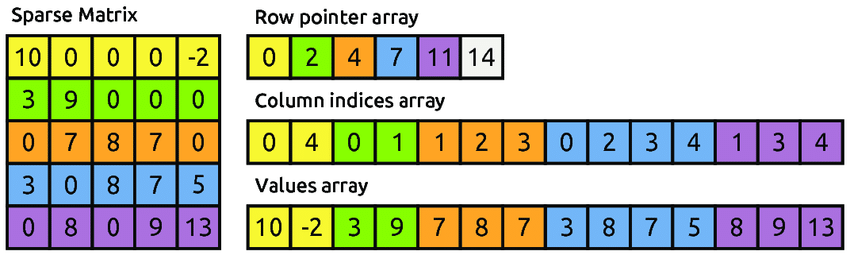
Some examples of sparse vectors are:
One-hot encoding: This is a way of representing categorical data as sparse binary vectors. For example, if we have a word "cat" in our vocabulary, we can encode it as [1, 0, 0], where 1 means the word is present and 0 means the word is absent. This way, we can store all the words in our vocabulary without repeating them.
Count encoding: This is a way of representing the frequency of words in a document as sparse binary vectors. For example, if we have a document "I like cats and dogs", we can encode it as [1, 0, 1], where 1 means the word appears once and 0 means the word appears zero times. This way, we can store the most frequent words in our document without counting them twice.
TF-IDF encoding: This is a way of representing normalized word frequency scores in a vocabulary as sparse binary vectors. For example, if we have a document "I like cats and dogs", we can encode it as [0.2, 0.3], where 0.2 means the word "cats" has a score of 0.2 (the sum of its frequency and inverse document frequency) and 0.3 means the word "dogs" has a score of 0.3 (the sum of its frequency and inverse document frequency). This way, we can store the most relevant words in our document without being biased by their popularity.
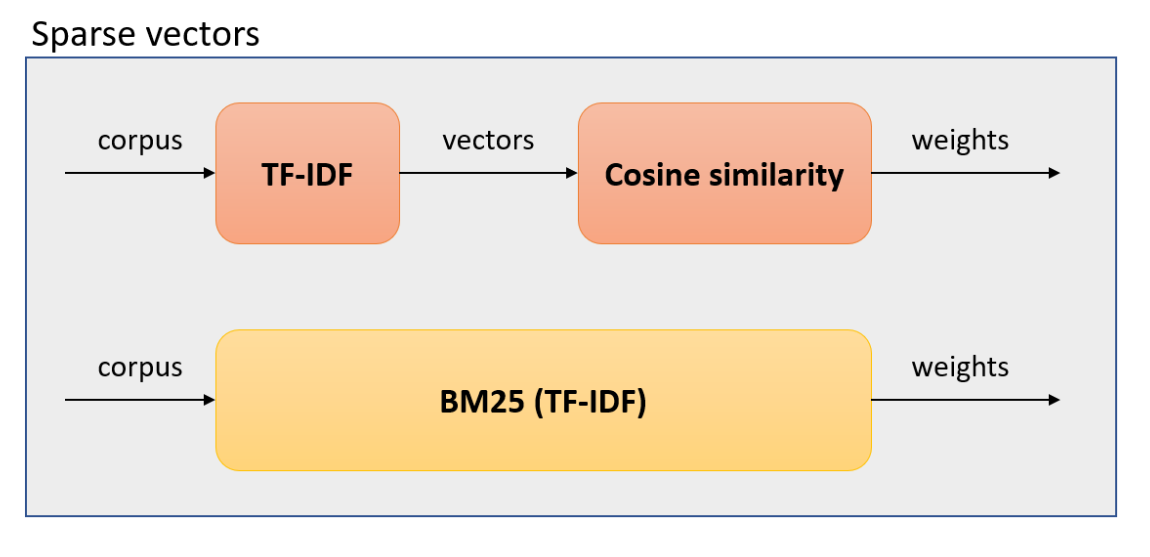
TF-IDF and BM25 are two algorithms for computing the relevance of documents to a query based on their term frequencies and inverse document frequencies. Term frequency (TF) measures how often a word appears in a document, and inverse document frequency (IDF) measures how rare or common a word is across the corpus of documents. TF-IDF combines both factors to give more weight to words that are relevant and less weight to words that are irrelevant.
TF-IDF can be calculated as follows:

BM25 can be calculated as follows:
Efficient SPLADE Retrieval for Sparse Vectors
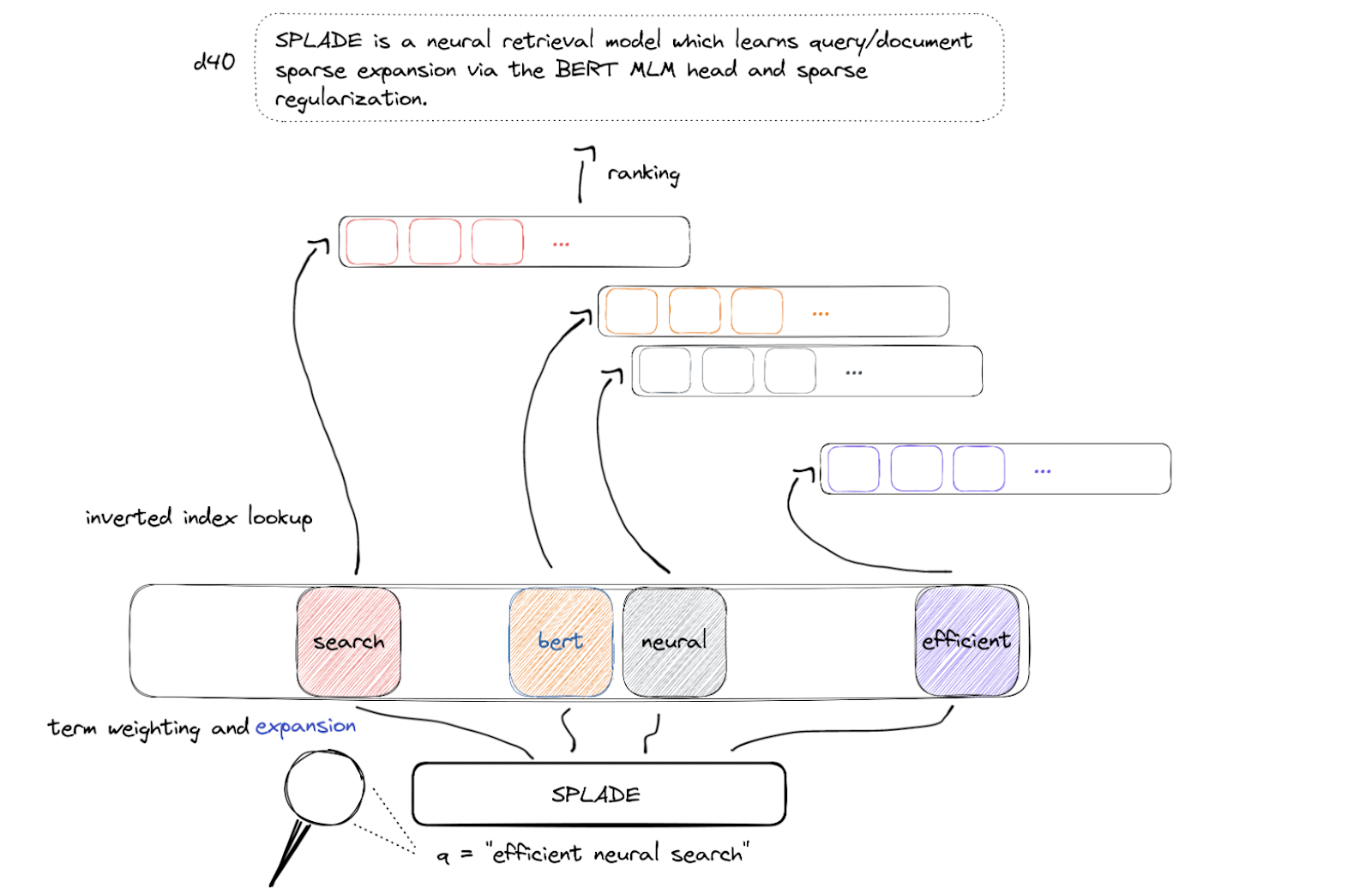
SPLADE, which stands for "Sparse Lexical Representations for First-Stage Ranking," is a model designed for the first-stage retrieval task. The primary objective of SPLADE is to predict term importance within the BERT WordPiece vocabulary based on the logits of the Masked Language Model (MLM) layer. This model is specifically tailored for efficiently ranking documents in response to user queries.
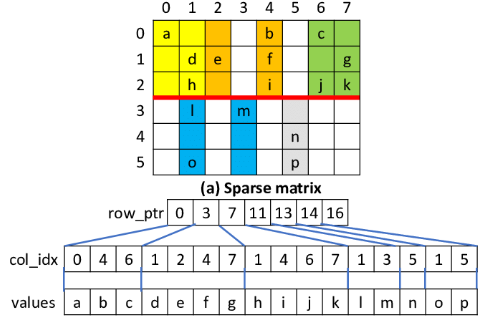
Architecture Overview
Input Representation:
SPLADE takes as input a query or document sequence after WordPiece tokenization, denoted as (𝑡 = (𝑡_1, 𝑡_2, ..., 𝑡_𝑁)).
Corresponding BERT embeddings (ℎ_1, ℎ_2, ..., ℎ_𝑁) are obtained for each token in the sequence.
2. Importance Prediction: The importance wij of token (j) for a token (i) is predicted using a transformation function:
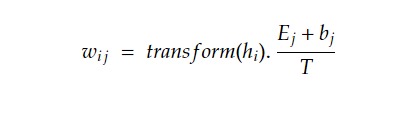
Ej is the BERT input embedding for token bj.
bj is a token-level bias.
transform(.) is a linear layer with GeLU activation and LayerNorm.
T is a parameter.
3. Final Representation: The final representation wj is obtained by summing importance predictors over the input sequence tokens, with a log-saturation effect:
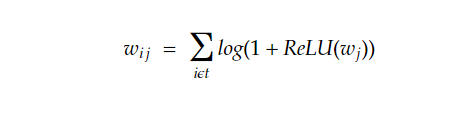
Pooling Strategy Modification
To enhance the model's performance, SPLADE proposes a modification to the pooling strategy. Instead of using summation, a max pooling operation is introduced, leading to the equation:
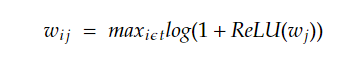
Regularization and Efficiency Improvements
Sparse FLOPS Regularization: SPLADE incorporates a regularization term, ℓFLOPS, which encourages sparsity in the learned representations.
Document-Only Version (SPLADE-doc): SPLADE introduces a document-only version, SPLADE-doc, where query expansion and term weighting are omitted. The ranking score depends solely on the document term weights, offering an efficiency boost.
Distillation for Knowledge Transfer
SPLADE integrates distillation into its training procedure, involving the training of a SPLADE first-stage retriever and a cross-encoder reranker. The second step incorporates triplets generated using SPLADE trained with distillation, leading to the creation of DistilSPLADE-max.
SPLADE aims to provide efficient and sparse representations for first-stage retrieval, with a focus on ranking documents based on user queries. The model leverages BERT embeddings, introduces a unique pooling strategy, includes regularization techniques, and incorporates distillation for knowledge transfer, resulting in improved performance and efficiency.
Leveraging Sparse Vectors with Qdrant 1.7.0
The release of Qdrant 1.7.0 marks a significant milestone with the introduction of native support for sparse vectors. This feature brings a wealth of opportunities and opens up exciting possibilities for users who seek efficient solutions for keyword-based search mechanisms. Let's delve into why using Qdrant 1.7.0 for sparse vectors is particularly interesting.
Addressing Keyword-Based Search Needs
Traditional Mechanisms: Keyword-based search mechanisms often involve algorithms like TF-IDF or BM25, where vectors are predominantly sparse, containing a limited number of non-zero values.
Native Support: Qdrant's introduction of native support for sparse vectors directly addresses the needs of users who rely on keyword-based search, providing a unified solution for both sparse and dense vectors.
Efficient Representation
Optimized Storage: Sparse vectors, by design, have a majority of dimensions filled with zeros, making their representation more memory-efficient compared to dense vectors.
Storage Strategy: Qdrant's native support for sparse vectors allows users to store and handle these vectors more efficiently, contributing to improved overall storage strategies.
Novel Discovery API
Beyond Traditional Search: Qdrant 1.7.0 introduces a Discovery API that goes beyond conventional search, offering a fresh approach to utilizing vectors for restricted search and exploration.
New Use Cases: The Discovery API broadens the scope of vector similarity applications, enabling users to explore novel use cases that extend beyond traditional search scenarios.
User-Defined Sharding
Tailored Data Distribution: With Qdrant 1.7.0, users gain the ability to define and decide which data points should be stored on specific shards.
Flexibility: User-defined sharding provides greater flexibility in data distribution, allowing users to tailor their storage strategy according to specific requirements and use cases.
Snapshot-Based Shard Transfer
Efficient Shard Management: The introduction of snapshot-based shard transfer in Qdrant 1.7.0 offers an optimized method for moving shards between nodes.
Enhanced Performance: This approach enhances the efficiency of shard management, contributing to improved system performance and resource utilization.
Implementing Qdrant for Sparse Medical Data
To understand more about how we are going to deal with sparse vectors, let's implement practically and see how Qdrant 1.7.0 is dealing with sparse vectors.
Let's start with installing all the libraries that we are going to need.
!pip install -q transformers |
Now, let's import all the packages that we require.
import pandas as pd |
We'll use the dataset from Kaggle, which comprises medical transcriptions for various medical specialities. You can visit the dataset here.
Load the dataset.
data = pd.read_csv("/content/mtsamples.csv") |
Let's go with only transcriptions.
data = data[['transcription']] |
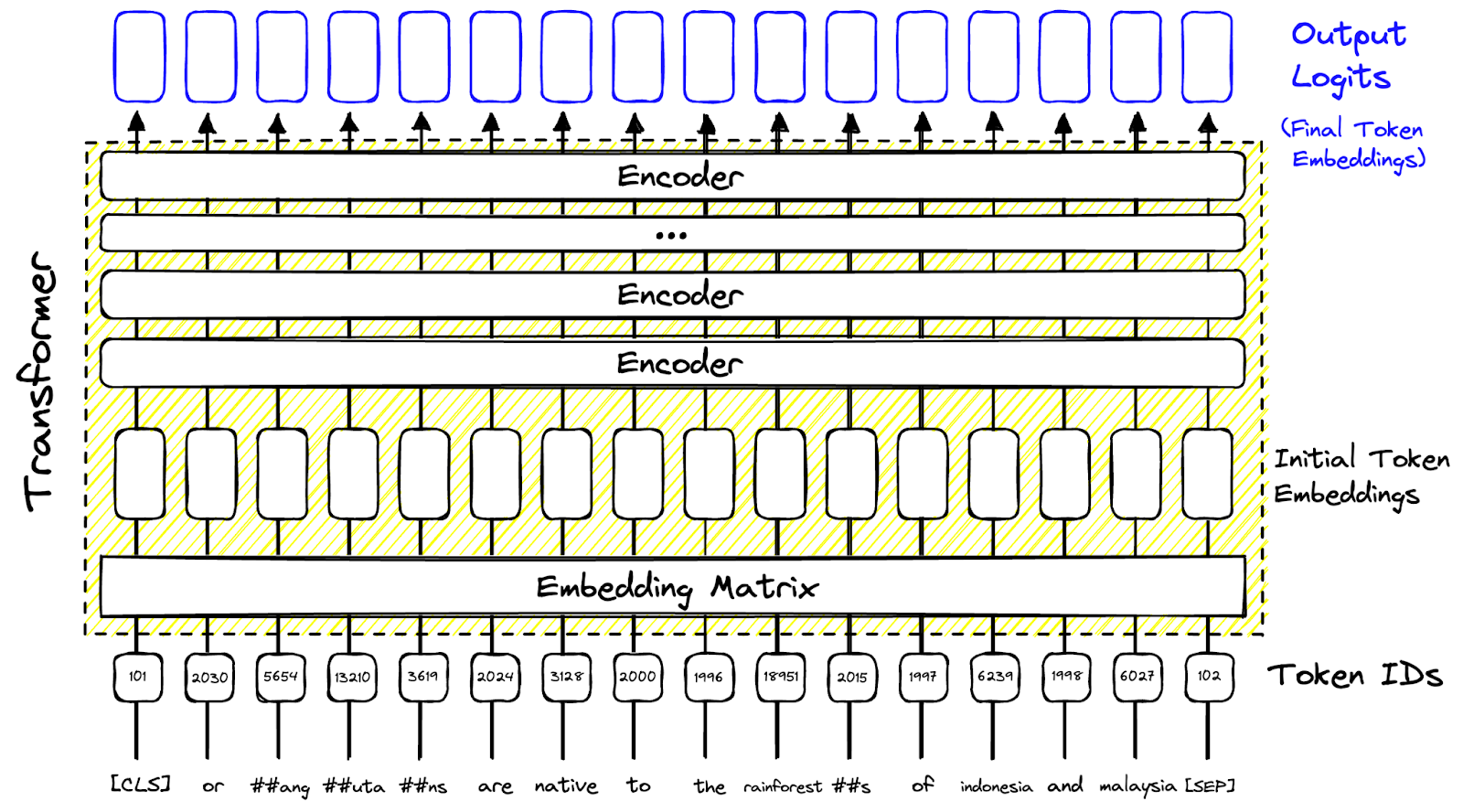
The code initializes a variable model_id with the identifier for a specific pre-trained language model which is SPLADE ("naver/splade-cocondenser-ensembledistil"). It then proceeds to load the tokenizer and the language model using the Hugging Face Transformers library. The tokenizer is responsible for tokenizing input text, and the model is configured for Masked Language Model tasks, indicating its ability to predict masked words in a text sequence.
model_id = "naver/splade-cocondenser-ensembledistil" |
We can create an input document text which here is the first transcription, tokenize it, and process it through the model to produce the MLM head output logits.
tokens = tokenizer(data['transcription'][0], return_tensors='pt') |
Following will be the output:
MaskedLMOutput(loss=None, logits=tensor([[[ -5.8697, -7.8917, -7.4682, ..., -8.1316, -8.0164, -5.3772], |
Let's check the shape of output logits.
output.logits.shape |
It will provide the shape of torch.Size([1, 333, 30522]). It means there are 333 probability distributions, each of dimensionality 30522. To transform this into the SPLADE sparse vector, we do the following:
vec = torch.max( |
Because our vector is sparse, we can transform it into a much more compact dictionary format, keeping only the non-zero positions and weights.
# extract non-zero positions |
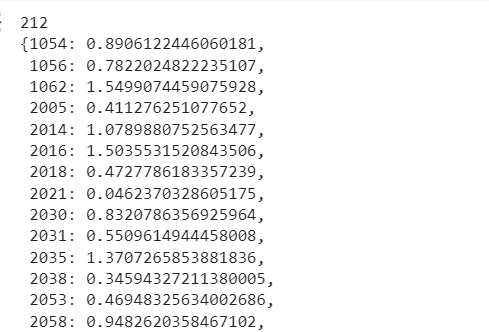
This is the final format of our sparse vector, but it’s not very interpretable. What we can do is translate the token ID keys to human-readable plaintext tokens. We do that like this:
# extract the ID position to text token mappings |
Now we can see the most highly scored tokens from the Sparse Vector.
Let's take some transcriptions to see how Qdrant handles Sparse Vectors.
text = data['transcription'][:10].tolist() |
Set up the Qdrant Client.
# Qdrant client setup |
Create a collection with Sparse vector support.
client.recreate_collection( |
Now, let's insert the sparse vectors. This step is key to building a dataset that can be quickly retrieved in the first stage of the retrieval process, utilizing the efficiency of sparse vectors.
indices = list(sparse_dict.keys()) |
Let's define a helper function to compute vectors from the text.
def compute_vector(text): |
Let's query with an example.
# Preparing a query vector |
After setting up the collection and inserting sparse vectors, the next critical step is retrieving and interpreting the results. This process involves executing a search query and then analyzing the returned results.
queryindices = list(queryindices) |
In the above code, we execute a search against our collection using the prepared sparse vector query. The client.search method takes the collection name and the query vector as inputs. The query vector is constructed using the models NamedSparseVector, which includes the indices and values derived from the query text. This is a crucial step in efficiently retrieving relevant documents.
Following will be the result:

The result, as shown above, is a ScoredPoint object containing the ID of the retrieved document, its version, a similarity score, and the sparse vector. The score is a key element as it quantifies the similarity between the query and the document, based on their respective vectors. The higher the score, the greater the similarity between the query and the document, making it a valuable metric for assessing the relevance of the retrieved documents. You can see that we got a score of 1.5238761901855469, which is a good result.
Conclusion
In conclusion, the release of Qdrant 1.7.0 has significantly eased the process of dealing with sparse vectors, introducing native support for efficient integration into vector databases. This update addresses historical challenges associated with sparse data, offering robust querying capabilities for both dense and sparse vectors. Qdrant's enhanced features not only simplify the handling of sparse vectors but also open up new possibilities for data analysis, marking a crucial advancement in the field of vector search engines.
The excitement surrounding the use of Qdrant for sparse medical transcriptions is palpable. Sparse medical data, known for its irregularities and missing values, has traditionally presented challenges for seamless integration into databases. Qdrant 1.7.0, however, transforms this landscape by providing a user-friendly platform for navigating and analyzing complex medical datasets. The native support for sparse vectors empowers medical researchers and practitioners, fostering more effective exploration and understanding of medical transcriptions. As Qdrant continues to be utilized for sparse medical data, the combination of advanced features and community-driven development promises a transformative experience, showcasing the ongoing evolution of tools to meet the demands of modern data challenges in the realm of medical research and analytics.
This article was originally published here: https://medium.com/@akriti.upadhyay/how-to-use-sparse-vectors-for-medical-data-with-qdrant-1-7-0-5a19c97c76b0
Subscribe to my newsletter
Read articles from Akriti Upadhyay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by