Implementing your personal production-ready Telegram bot using AI tools to monitor, transcribe, summarize and voice videos from YouTube
 Alexander Polev
Alexander Polev
Intro
Artificial intelligence (AI) is transforming the way we consume, create, and share information on the internet. From speech recognition to natural language processing, from computer vision to text summarization, AI tools are enabling us to access and understand vast amounts of data in various formats and languages.
In this article, I will show you how to build your personal Telegram bot using open-source AI tools and Python libraries to monitor, transcribe, summarize, and voice videos from your YouTube subscriptions. I tried to focus on self-hosted solutions and tools, and experimented with voice cloning.
As a desired result, you automatically get short and informative summaries, voiced by your favorite blogger, using voice-cloning technology!
Special attention is paid to app architecture, to make it as close to the real production-ready and scalable service as possible. I used the background workers and job scheduling library RQ (Redis Queue) and its Django integration django-rq. Also, I will show how to integrate the asynchronous Telegram bot library aiogram with modern Django.
Project schema and architecture
Showcased below is a visual representation of the pipeline.
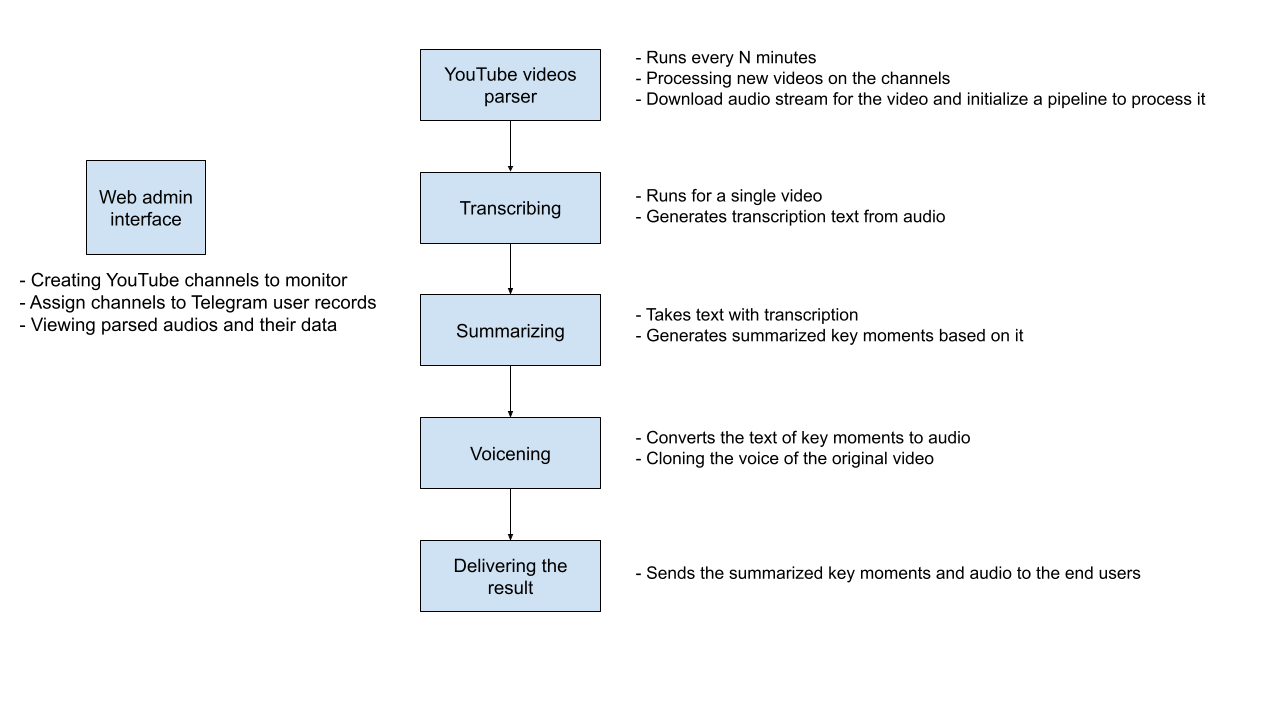
To implement the scheme shown above, I created a Django project, since this library has a nice ORM and out-of-the-box admin interface. django-rq is used for executing tasks.
The whole list of used libraries:
Django - for the admin web interface and database management
Django-RQ - for task workers and job execution queue
pytubefix - to parse YouTube videos and channels
OpenAI Whisper - for video transcription
nltk.tokenizer - to split text into sentences
OpenAI API - to generate key moments with ChatGPT
aiogram - for Telegram bot
Every step of the pipeline could be replaced with a similar solution because of the modular architecture.
The core logic is described in the main module. It has 2 models. YoutubeChannel:
class YoutubeChannel(models.Model):
url = models.URLField()
enabled = models.BooleanField(default=True)
title = models.CharField(max_length=200, blank=True, null=True)
last_parsed_at = models.DateTimeField(blank=True, null=True)
voice_file = models.FileField(upload_to='channels/', blank=True, null=True)
And YoutubeVideo:
class YoutubeVideo(CreatedUpdatedMixin):
channel = models.ForeignKey(YoutubeChannel, on_delete=models.CASCADE)
url = models.URLField()
youtube_id = models.CharField(max_length=100, blank=True, null=True)
title = models.CharField(max_length=200, blank=True, null=True)
audio_file = models.FileField(upload_to='videos/audio/', blank=True, null=True)
transcription = models.TextField(blank=True, null=True)
transcription_language = models.CharField(max_length=10, blank=True, null=True)
summary = models.TextField(blank=True, null=True)
voiced_summary = models.FileField(upload_to='videos/voiced/', blank=True, null=True)
It saves the data for all the pipeline stages.
Tasks are executed in django-rq, and split into 2 queues: default and ai. Default is used for any external API calls, like parsing YouTube or sending Telegram messages. It could have multiple workers and not be resource-consuming. "AI" queue, on the other hand, works with high-performance tasks, like transcription generation, summarization or voicing. In code, tasks are marked with @job decorator, specifying the queue for the task.
Now, let's explore step-by-step how the whole pipeline works.
Youtube monitor
To work with YouTube, there is a nice library called pytube. Unfortunately, it has not been actively maintained in recent times and crashes when working with Channels. So I have found another one, that implements the same functionality and uses the same interfaces - pytubefix.
There are 3 functions in the YouTube Monitor component of the pipeline.
parse_all_channels - loops through enabled channels and creates tasks to parse each of them:
@job('default')
def parse_all_channels():
print('running parse all channels')
for channel in YoutubeChannel.objects.filter(enabled=True):
parse_channel.delay(channel)
parse_channel - processes videos of a particular channel. For simplicity, the current implementation analyzes only the most recent video. It checks if it is not already in the database, and then creates the YoutubeVideo record and runs the pipeline with it:
@job('default')
def parse_channel(channel: YoutubeChannel):
print(f'running parse channel {str(channel)}')
yt_channel = Channel(channel.url)
channel.title = yt_channel.channel_name
channel.save()
try:
last_video = yt_channel.videos[0]
except IndexError:
return
if YoutubeVideo.objects.filter(channel=channel, youtube_id=last_video.video_id).exists():
return
new_video = YoutubeVideo.objects.create(
channel=channel,
url=last_video.watch_url,
youtube_id=last_video.video_id,
title=last_video.title,
)
channel.last_parsed_at = timezone.now()
channel.save()
parse_video.delay(new_video)
parse_video - fetches and saves the audio stream with the highest bitrate:
@job('default')
def parse_video(video: YoutubeVideo):
print(f'running parse video {str(video)}')
yt_video = YouTube(video.url)
video.youtube_id = yt_video.video_id
video.title = yt_video.title
video.save()
audio_streams = [stream for stream in yt_video.streams if stream.type == 'audio']
audio_streams = sorted(audio_streams, key=lambda s: s.bitrate, reverse=True)
if not audio_streams:
return
stream: Stream = audio_streams[0]
buffer = io.BytesIO()
stream.stream_to_buffer(buffer)
video.audio_file.save(f'{video.youtube_id}.{stream.subtype}', buffer)
video.save()
transcribe_video.delay(video)
Transcription
The next important stage is the audio transcription. Some libraries allow you to work with YouTube-generated captions. But I find that OpenAI's Whisper gives better results. I used the self-hosted solution with a "medium" model. They are also providing API for this if you want to avoid high-performant computations.
The process is pretty straightforward. The only thing to point out is the job timeout, I set it to 1 hour. It usually takes 15-20 minutes to transcribe a 2h video on my personal MSI GF65 Thin laptop.
@job('ai', timeout=60 * 60)
def transcribe_video(video: YoutubeVideo):
print(f'running transcribe video {str(video)}')
model = whisper.load_model('medium')
result = model.transcribe(video.audio_file.path)
video.transcription_language = result['language']
video.transcription = result['text']
video.save()
summarize_video.delay(video)
Summary
For summarization, I initially tried to use open-source LLMs. Unfortunately, my laptop is too weak for it and cannot run even quantified LLaMA 2 or Mistral 7B. So, I gave up and switched to using ChatGPT's API.
The core idea of the process is that I split the input text into sentences (using nltk.tokenize package), and form blocks of sentences until I reach the context window limit. I then summarize each block separately, with a 2-sentence overlap between blocks.
In the resulting summary, I combine outputs from all the blocks. In some algorithms, you also summarize all the outputs. However, I found that concatenation is better since there is not a lot of overlap of key moments.
This algorithm is quite simple but assumes that the initial transcription is correctly split into sentences. So it could be presented like this sequence of steps:
Split the text into a list of sentences
Group sentences into slightly overlapped blocks. Each block should fit the LLM context window size
Summarize each block using LLM and a special prompt
Join resulting outputs into the generic summary
The code and LLM prompts can be found in the related module in my repository
Voicing
My core idea was that people want to hear the voice of their favorite blogger. That's why I was oriented on tools that provide a voice cloning feature. Some libraries can do that. For example, VALL-E looks promising, and would be interesting to try it later. But I end up using Coqui TTS. I tried to use their studio, and the internal models look really awesome! But even open-source models are pretty good, providing a quality result.
For simplicity, I uploaded the speaker prompt to the YoutubeChannel model, but it could be extracted from the audio stream, based on intervals, returned by Whisper.
The resulting function:
@job('ai', timeout=20 * 60)
def voice_summary(video: YoutubeVideo):
from apps.telegram.tasks import send_video_notifications
print(f'running voice summary {str(video)}')
if not video.summary:
return
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tts = TTS('tts_models/multilingual/multi-dataset/xtts_v2').to(device)
_fd, temp_filename = tempfile.mkstemp()
try:
tts.tts_to_file(
text=video.summary,
speaker_wav=video.channel.voice_file.path,
language=video.transcription_language,
file_path=temp_filename,
)
with open(temp_filename, 'rb') as file:
video.voiced_summary.save(f'{video.youtube_id}.wav', file)
video.save()
finally:
os.remove(temp_filename)
send_video_notifications.delay(video)
Sending results
Now we have all the data. The last step: deliver it to the user. For that purpose, I am using aiogram library. For more info on basic bot setup, feel free to check my last article.
The tricky part is how to run an async bot in the sync-by-default Django environment and vice-versa, how to execute sync Django ORM commands inside the async bot.
So the bot entry point is this management command python manage.py run_bot:
import asyncio
from django.core.management import BaseCommand
from django.conf import settings
from apps.telegram.bot import run_bot
class Command(BaseCommand):
def handle(self, *args, **options):
asyncio.run(run_bot(settings.TELEGRAM_BOT_TOKEN))
The implementation of async run_bot is also quite simple:
async def run_bot(token: str) -> None:
dp = Dispatcher()
dp.message(CommandStart())(command_start_handler)
dp.message()(echo_handler)
bot = Bot(token, parse_mode=ParseMode.HTML)
dp.message.middleware(UserMiddleware())
await dp.start_polling(bot)
Since the service purpose is mostly to transfer information from the server to users, we need just any handler, to register user. And TelegramUser creation happens in the UserMiddleware:
class UserMiddleware(BaseMiddleware):
async def __call__(
self,
handler: Callable[[Message, Dict[str, Any]], Awaitable[Any]],
event: Message,
data: Dict[str, Any]
) -> Any:
data['user'] = await TelegramUser.get_or_create_from_telegram_user(event.from_user)
return await handler(event, data)
get_or_create_from_telegram_user uses new asynchronous Django ORM functions: aget and acreate which allow you to execute database queries from an async context. Now, it is enough to send the "/start" command to the bot, and the user should be created in the database. Plus, the bot can send notifications to the user.
Running & getting a result
The most exciting part - seeing how every cog builds up into a mechanism, and it all starts working together! There are a certain amount of processes to be run for the pipeline:
Web server with an admin panel
python manage.py runserver
RQ workers for AI tasks
python manage.py rqworker ai
RQ workers for other tasks
python manage.py rqworker default
RQ scheduler
python manage.py rqscheduler
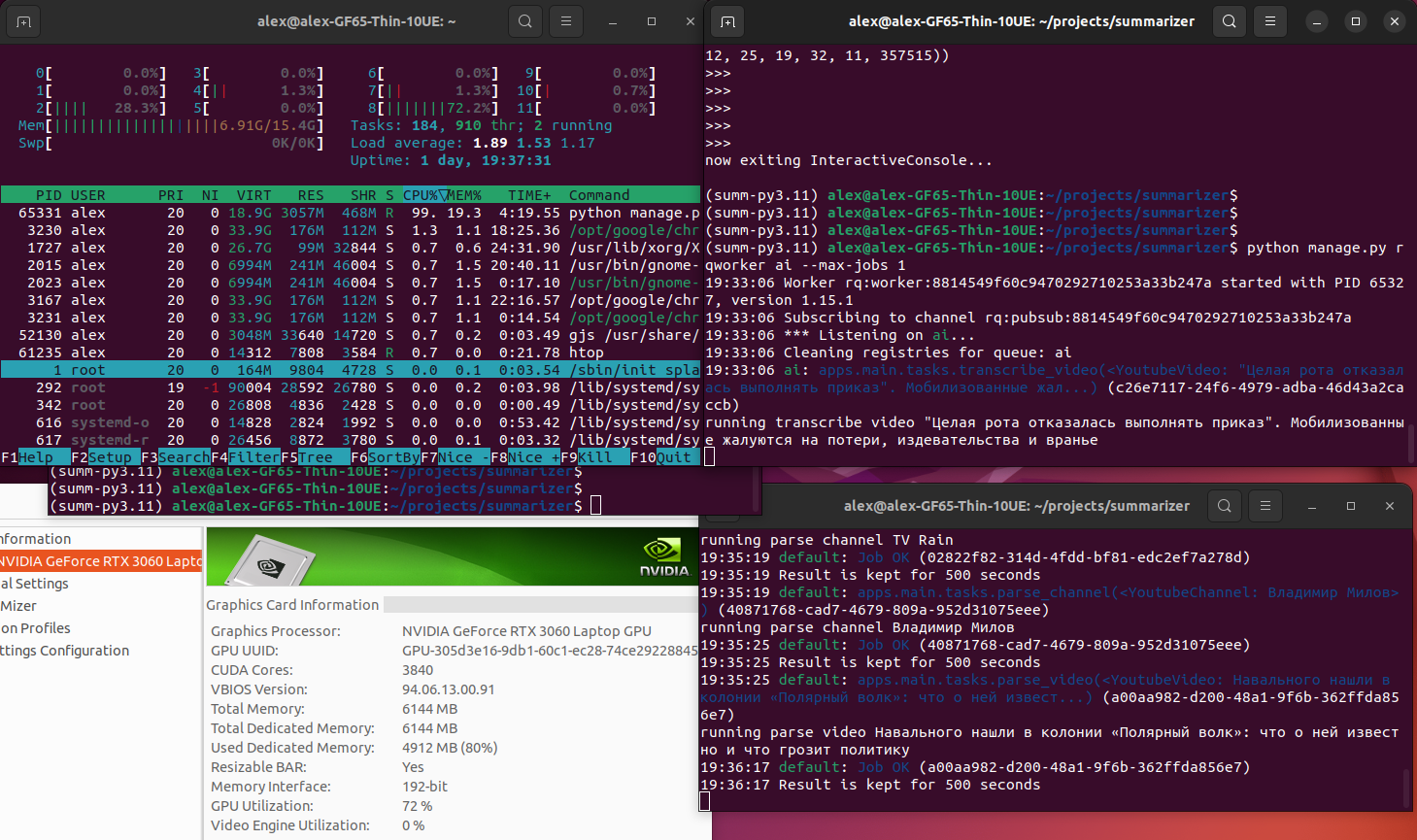
Here is an example of running processes and consumed resources:
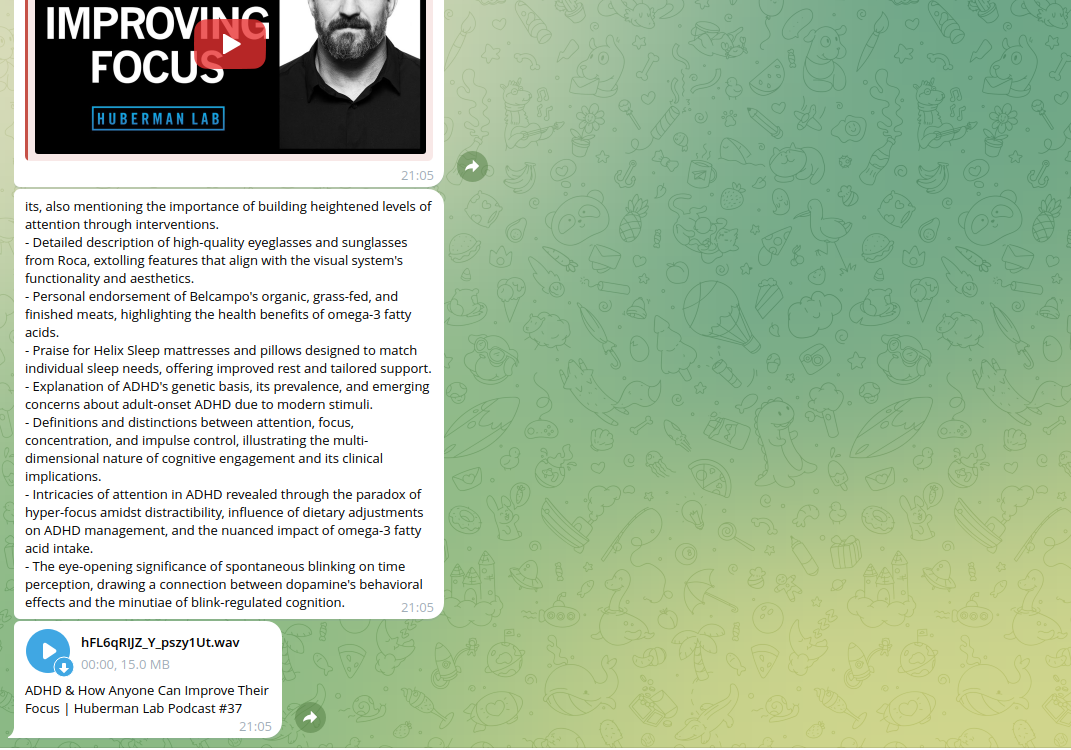
And the example of the resulting message (using GPT-4 for summary):
Conclusion & future improvements
In the end, I got a working prototype that could be easily Dockerized and run as a personal service. Especially considering that with so many models available online, you might not need to run high-performance computing on your own. So, any VPS could deal with simple API calls.
The biggest problem that I see now is the quality of summarized key moments. During some tests, I realized that ChatGPT 3.5 can mix up facts, so you cannot fully trust the resulting information to be 100% accurate, especially if it is about daily news or current events. ChatGPT-4 handles that much better, and the resulting quality is quite impressive. gpt-4-1106-preview model has a context window of 128k tokens, which is enough to fit almost any video in one chunk. But it is expensive - costed me 0.20$ per one API call for a medium-size transcription. So, it might be necessary to play more with prompts or try different LLMs.
Also, besides summary accuracy, to make it 100% production-ready, I would improve things like:
Add mutexes to tasks
Add tasks error handling
Dockerize the project
Use webhooks, instead of polling for the Telegram bot
Regardless, this working prototype is an interesting playground. Source code is available in GitHub.
Hopefully, you enjoyed reading this!
Disclaimer
This article and the content herein, including code, example processes, and the use of AI tools for voice cloning, are intended for personal information and educational purposes only. Unauthorized distribution of generated voice-cloned content without the author's explicit permission is strictly prohibited. Before using any of the mentioned tools in commercial products, consult with their license agreement. All credit goes to the rightful owners.
Subscribe to my newsletter
Read articles from Alexander Polev directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by