[PostgreSQL Scaling and Optimization] How to search on 10 GB data (1 million rows) within 5 ms?
 Kiều Tâm Đỉnh
Kiều Tâm Đỉnh
Warning
This article will help you to make a full text search API on PostgreSQL - a kind of text and retrieval problem.
Nowadays, in large-scale system, people usually decouple write-heavy DB and read-heavy DB, not one for all. Example: using PostgreSQL as a OLTP DB (Online Transaction Processing) and Elasticsearch as a search engine, RedShift as a OLAP (Online Analytical Processing). They have their own suitable underlying design, both software processes and storage to match their niche.
My approach in this article is using only PostgreSQL for both transactional processing and search engine. This way would be able to save some cost at the beginning of your application, or in the effort to scale up your relational DB.
Techstack
Django, Django REST framework, Open API
Docker, Shell script
PostgreSQL
Available repository
Oh, my fellow, as you wish, I already implemented all feature, populate test data, containerize all stuffs for you here https://gitlab.com/omnihr1. Not need to copy paste anymore, just clone to test.
In this article, I only focus on explaining my solution for searching.
Express my solution
Now, let's imagine we have a platform for HR management with numerous employees and their organization data. We will have 2 tables, Organization and Employee. Table Employee is potentially very big, we make some tweaking before.
Table partitioning
In DB Scaling, we have DB Sharding technique, which is splitting a large database into smaller, more manageable parts called shards. Each shard contains a subset of the data and is stored on a separate server.
This allows for better performance and scalability as the workload is distributed across multiple servers. Sharding can also improve fault tolerance, as a failure in one shard does not necessarily affect the entire database.
The idea of Table partitioning is simply split your table by the range of data values, a hash function...
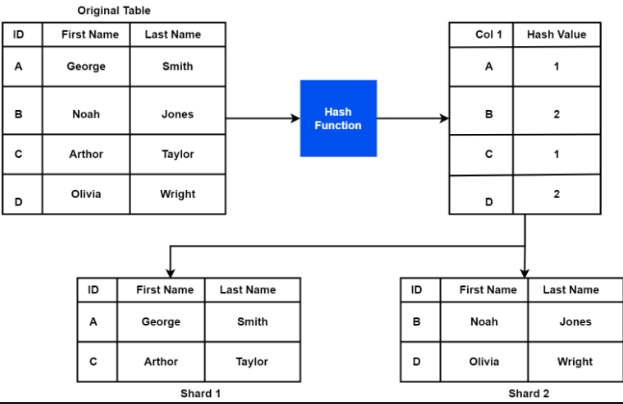
However, we only have 1 table, it turns out to be splitting only one table Employee on only 1 DB instance.
To open room for query planner scan on all table partition in parallel, in Django, we use psqlextra.types.PostgresPartitioningMethod to make the model on application layer. Given Employee status can be active, not_started, terminated we divide onto 3 corresponding partitions.
from django.db import models
from django.contrib.postgres.search import SearchVector, SearchVectorField
from psqlextra.types import PostgresPartitioningMethod
from psqlextra.models import PostgresPartitionedModel
from django.contrib.postgres.indexes import GinIndex
class Organization(models.Model):
name = models.CharField(max_length=100)
dynamic_columns = models.JSONField(null=True)
STATUSES = [
("active", "Active"),
("not_started", "Not started"),
("terminated", "Terminated"),
]
class Employee(PostgresPartitionedModel):
class PartitioningMeta:
method = PostgresPartitioningMethod.LIST
key = ["status"]
class Meta:
db_table = "search_employee"
# indexes = (GinIndex(fields=["vector_column"]),) # created at DB layer, app layer should not touched it
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
contact_info = models.CharField(max_length=500)
department = models.CharField(max_length=500)
location = models.CharField(max_length=1000)
company = models.CharField(max_length=200)
position = models.CharField(max_length=100)
status = models.CharField(choices=STATUSES)
organization = models.ForeignKey(Organization, on_delete=models.CASCADE)
# Have both company & organization?
# Assume some HeadHunt company store employees data. HeadHunt is org, their working company store employees is company.
created_date = models.DateTimeField(auto_now_add=True)
updated_date = models.DateTimeField(auto_now=True)
vector_column = SearchVectorField(null=True)
# I already "cheat" on migration file due to Django doesn't support for generated column
def _do_insert(self, manager, using, fields, update_pk, raw):
"""
Django tries to insert on a generated column, I did workaround to make it work
"""
return super(Employee, self)._do_insert(
manager,
using,
[f for f in fields if f.attname not in ["vector_column"]],
update_pk,
raw,
)
And write this on migration file.
migrations.RunSQL(
sql="""
CREATE TABLE employee_p1 PARTITION OF search_employee
FOR VALUES IN ('active');
""",
reverse_sql="""
DROP TABLE employee_p1
""",
),
migrations.RunSQL(
sql="""
CREATE TABLE employee_p2 PARTITION OF search_employee
FOR VALUES IN ('not_started');
""",
reverse_sql="""
DROP TABLE employee_p2
""",
),
migrations.RunSQL(
sql="""
CREATE TABLE employee_p3 PARTITION OF search_employee
FOR VALUES IN ('terminated');
""",
reverse_sql="""
DROP TABLE employee_p3
""",
),
Generated column
Using full text search, we need to vectorize both documents and queries in order to represent them as numerical vectors. This allows us to calculate the similarity between them and retrieve relevant documents based on the user's query.
Now, let's precompute documents in form of vectors by making a generated column named vector_column to speed up query later on.
migrations.RunSQL(
sql="""
ALTER TABLE search_employee ADD COLUMN vector_column tsvector GENERATED ALWAYS AS (
setweight(to_tsvector('english', coalesce(first_name, '')), 'A') ||
setweight(to_tsvector('english', coalesce(last_name,'')), 'B')
) STORED;
""",
reverse_sql="""
ALTER TABLE search_employee DROP COLUMN vector_column;
""",
),
GIN index
In PostgreSQL, there are 2 index type can be used to foster full text search: GiST and GIN. Generally, we choose GIN because our assumed app is needed to response rapidly as an API. It's acceptable to create new Employee a little bit slow. So, we create a GinIndex to support scanning on vector_column.
migrations.RunSQL(
sql="""
CREATE INDEX vector_column_gin_indx ON search_employee USING gin(vector_column);
""",
reverse_sql="""
DROP INDEX vector_column_gin_indx;
"""
)
Actually, the factorized data are not variant too much, so the index size is small and doesn't cost much time to scan. If you apply this solution set on your real-life system, don't expect the efficiency will be raised up incredibly like my demo :)
Pagination
On view layer, the API also support pagination for Front end side, because the amount of returned Employee may be too large to display/store all at once.
Python API
def search_org_employees(
org_id: int, filter_options: dict, search_text: str, page_index: int
):
org = Organization.objects.get(id=org_id)
offset = (page_index - 1) * settings.PAGE_SIZE
queryset = (
Employee.objects.annotate(
search=SearchVector("first_name", "last_name", config="english")
)
.filter(organization=org, **filter_options)
.filter(vector_column=search_text)
.order_by("-created_date")
.values()
)
if org.dynamic_columns:
queryset = queryset.values(*org.dynamic_columns)
match_employee_qty = queryset.count()
paginated_queryset = queryset[offset : offset + settings.PAGE_SIZE]
logger.info(f"--- hit DB query: {paginated_queryset.query}")
return match_employee_qty, list(paginated_queryset)
Result measurements
The query only
I imported about 1 million rows (~10GB) into Employee table. Each partition about 300k rows. Let's test:
select count(*) from search_employee se;
explain analyze
select
"search_employee"."id",
"search_employee"."first_name",
"search_employee"."last_name",
"search_employee"."contact_info",
"search_employee"."department",
"search_employee"."location",
"search_employee"."company",
"search_employee"."position",
"search_employee"."status",
"search_employee"."organization_id",
"search_employee"."created_date",
"search_employee"."updated_date",
"search_employee"."vector_column",
to_tsvector('english'::regconfig,
coalesce("search_employee"."first_name",
'') || ' ' || coalesce("search_employee"."last_name",
'')) as "search"
from
"search_employee"
where
("search_employee"."organization_id" = 1
and "search_employee"."position" = 'CTO'
and "search_employee"."status" = 'active'
and "search_employee"."vector_column" @@ (plainto_tsquery('Henry Lewis')))
order by
"search_employee"."created_date" desc
limit 30
QUERY PLAN |
-----------------------------------------------------------------------------------------------------------------------------------------------------------+
Limit (cost=848.74..851.15 rows=9 width=175) (actual time=1.300..1.334 rows=8 loops=1) |
-> Result (cost=848.74..851.15 rows=9 width=175) (actual time=1.298..1.332 rows=8 loops=1) |
-> Sort (cost=848.74..848.76 rows=9 width=143) (actual time=1.280..1.282 rows=8 loops=1) |
Sort Key: search_employee.created_date DESC |
Sort Method: quicksort Memory: 27kB |
-> Bitmap Heap Scan on employee_p1 search_employee (cost=45.88..848.60 rows=9 width=143) (actual time=1.020..1.266 rows=8 loops=1) |
Recheck Cond: (vector_column @@ plainto_tsquery('Henry Lewis'::text)) |
Filter: ((organization_id = 1) AND (("position")::text = 'CTO'::text) AND ((status)::text = 'active'::text)) |
Rows Removed by Filter: 189 |
Heap Blocks: exact=192 |
-> Bitmap Index Scan on employee_p1_vector_column_idx (cost=0.00..45.87 rows=216 width=0) (actual time=0.965..0.965 rows=197 loops=1)|
Index Cond: (vector_column @@ plainto_tsquery('Henry Lewis'::text)) |
Planning Time: 0.219 ms |
Execution Time: 1.376 ms |
Notice that a Bitmap Index Scan consists of 2 steps:
Scan the index to find all the possible match row locations, build a Bitmap structure. This likes you read the index of a real paper book.
Use that Bitmap to access the heap pages of the rows, also recheck condition of WHERE clause. This likes you actually go to specific paper page to read.
PostgreSQL picked the right partition based on status and ran Bitmap heap scan.
We already save some cost at step 1 compared to the case we scan on 1 big index of a huge table. This likes the paper book is divided onto multiple parts and you can pick the right one.
See, the scanning really leveraged our GIN index from generated column. Notice that employee_p1_vector_column_idx is renamed GIN index by PostgreSQL. You can check on table properties.
All 3 optimizations come into play!
Did cost 1.4 ms. I tested multiple times and see the slowest case is about 5 ms.
The normal API calling is just about 50 ms as well.
API end-to-end
curl --location 'localhost:10000/search/?org_id=1&search_text=Henry%20Lewis&position=CTO&status=active'
cost about 40 ms to have response.
{
"status": "success",
"data": {
"qty": 5,
"total_pages": 1,
"employees": [
{
"first_name": "Henry",
"last_name": "Lewis",
"contact_info": "Contact Information",
"department": "Quality Assurance",
"location": "Nowhere",
"company": "Microsoft",
"position": "CTO",
"status": "active"
},...
]
}
}
Conclusion
That's it!
Additionally, I setup Open API documentation for reading and using easily, use can use Try it out button on the UI of it, not need to open your Postman.
Thanks you!
Subscribe to my newsletter
Read articles from Kiều Tâm Đỉnh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kiều Tâm Đỉnh
Kiều Tâm Đỉnh
I am a lifelong learner. In career, I'm a DevOps engineer, focusing on Platform engineering, Backend development & Big data. In life, I'm a natural manifestation of the crazy simple mixture from writer, poet, amateur singer, runner athlete, spiritual-truth-seeker. I'm a bookworm, a big fan of Krishnamurti, Alan Turing, Leslie Lamport, Ichikawa Takuji, Faraday, Newton, Buddha, Jesus, Vyasa, Nam Cao... As the whole we are, I commit to consistently engage & contribute to the world forward.