Fine-tuning XLS-R Wav2Vec2 model for Swahili Automatic Speech Recognition
 Ronnie Leon
Ronnie Leon
Understanding Wav2Vec2
Wav2Vec2 is a pre-trained model for Automatic Speech Recognition (ASR) and was released in September 2020 by Alexei Baevski, Michael Auli, and Alex Conneau. Soon after the superior performance of Wav2Vec2 was demonstrated on one of the most popular English datasets for ASR, called LibriSpeech, Facebook AI presented a multi-lingual version of Wav2Vec2, called XLSR. XLSR stands for cross-lingual speech representations and refers to a model's ability to learn speech representations that are useful across multiple languages.
XLSR's successor, simply called XLS-R (referring to the "XLM-R for Speech"), was released in November 2021 by Arun Babu, Changhan Wang, Andros Tjandra, et al. XLS-R used almost half a million hours of audio data in 128 languages for self-supervised pre-training and comes in sizes ranging from 300 million up to two billion parameters. You can find the pre-trained checkpoints on the 🤗 Hub:
Similar to BERT's masked language modeling objective, XLS-R learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network during self-supervised pre-training (diagram below).
For fine-tuning, a single linear layer is added on top of the pre-trained network to train the model on labeled data of audio downstream tasks such as speech recognition, speech translation, and audio classification (diagram below).
XLS-R shows impressive improvements over previous state-of-the-art results on both speech recognition, speech translation, and speaker/language identification.
Setup
In this blog, I will give an in-detail explanation of how XLS-R - more specifically the pre-trained checkpoint Wav2Vec2-XLS-R-300M - was fine-tuned to develop a Swahili automatic speech recognition model with a word error rate of 0.083 evaluated on a private dataset by Mozilla.
XLS-R is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems, such as ASR and handwriting recognition.
I highly recommend reading the well-written blog post Sequence Modeling with CTC (2017)
While there are several pre-trained speech recognition models available, including Nvidia NeMo, Whisper, and Coqui, my preference has strongly inclined towards Wav2Vec2 XLS-R. From the moment I encountered it, there was an immediate sense that it outshines other models. Perhaps, this confidence stems from my positive experiences with products developed by MetaAI.
We initiated the process by installing the necessary packages
!pip install datasets==1.18.3
!pip install transformers==4.11.3
!pip install huggingface_hub==0.1
!pip install torchaudio
!pip install librosa
!pip install jiwer
torchaudio was used to load audio files and jiwer to evaluate our fine-tuned model using the word error rate (WER) metric. In the paper, the model was evaluated using the phoneme error rate (PER), but by far the most common metric in ASR is the word error rate (WER)
Prepare Data, Tokenizer, Feature Extractor
ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, e.g. a feature vector, and a tokenizer that processes the model's output format to text.
In 🤗 Transformers, the XLS-R model is thus accompanied by both a tokenizer, called Wav2Vec2CTCTokenizer, and a feature extractor, called Wav2Vec2FeatureExtractor.
We started by creating the tokenizer to decode the predicted output classes to the output transcription.
Create Wav2Vec2CTCTokenizer
A pre-trained XLS-R model maps the speech signal to a sequence of context representations as illustrated in the figure above. However, for speech recognition, the model has to to map this sequence of context representations to its corresponding transcription which means that a linear layer has to be added on top of the transformer block (shown in yellow in the diagram above). This linear layer is used to classify each context representation to a token class analogous to how a linear layer is added on top of BERT's embeddings for further classification after pre-training (cf. with the 'BERT' section of the following blog post). after pretraining a linear layer is added on top of BERT's embeddings for further classification - cf. with the 'BERT' section of this blog post.
The output size of this layer corresponds to the number of tokens in the vocabulary, which does not depend on XLS-R's pretraining task, but only on the labeled dataset used for fine-tuning.
We performed fine-tuning on XLS-R using the Common Voice 13.0 Swahili dataset.
from datasets import load_dataset
cv_swahili_train = load_dataset("mozilla-foundation/common_voice_13_0", "sw", split="train", use_auth_token=True)
cv_swahili_validate = load_dataset("mozilla-foundation/common_voice_13_0", "sw", split="validation", use_auth_token=True)
cv_swahili_test = load_dataset("mozilla-foundation/common_voice_13_0", "sw", split="test", use_auth_token=True)
Many ASR datasets only provide the target text, 'sentence' for each audio array 'audio' and file 'path'. Common Voice provides much more information about each audio file, such as the 'accent', etc. Keeping the notebook as general as possible, we only consider the transcribed text for fine-tuning.
columns_to_remove = ["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"]
cv_swahili_train = cv_swahili_train.remove_columns(columns_to_remove)
cv_swahili_validate = cv_swahili_validate.remove_columns(columns_to_remove)
cv_swahili_test = cv_swahili_test.remove_columns(columns_to_remove)
The transcriptions contained some special characters, such as ,.?!;:. Without a language model, it is much harder to classify speech chunks into such special characters because they don't correspond to a characteristic sound unit. For, the letter "s" has a more or less clear sound, whereas the special character "." does not. Also to understand the meaning of a speech signal, it is usually not necessary to include special characters in the transcription.
We removed all characters that don't contribute to the meaning of a word and cannot be represented by an acoustic sound and normalized the text.
import re
# Modify the chars_to_remove_regex pattern to include the additional symbols
chars_to_remove_regex = r'[\,\?\.\!\-\;\:\"\“\%\‘\”\�\'\(\)\*\=\_`\[\]\/\*°ː’•…]'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
cv_swahili_train = cv_swahili_train.map(remove_special_characters)
cv_swahili_validate = cv_swahili_validate.map(remove_special_characters)
cv_swahili_test = cv_swahili_test.map(remove_special_characters)
Before finalizing the pre-processing, it is always advantageous to consult a native speaker of the target language to see whether the text can be further simplified. Given that we were native speakers of the Swahili language, we replaced "hatted" characters with their equivalent "un-hatted" characters.
def replace_extra_characters(batch, column_name="sentence"):
character_replacements = {
'µ': 'u',
'á': 'a',
'â': 'a',
'ã': 'a',
'å': 'a',
'é': 'e',
'è': 'e',
'ë': 'e',
'í': 'i',
'ï': 'i',
'ñ': 'n',
'ó': 'o',
'ö': 'o',
'ø': 'o',
'ú': 'u',
'š': 's',
'ū': 'u',
'μ': 'u',
'ụ': 'u'
}
for original, replacement in character_replacements.items():
batch[column_name] = re.sub(re.escape(original), replacement, batch[column_name])
# Remove multiple dots and tabs
batch[column_name] = re.sub(r'\.\.\.+', '', batch[column_name])
batch[column_name] = re.sub(r'\t', '', batch[column_name])
return batch
cv_swahili_train = cv_swahili_train.map(replace_extra_characters)
cv_swahili_validate = cv_swahili_validate.map(replace_extra_characters)
cv_swahili_test = cv_swahili_test.map(replace_extra_characters)
In CTC, it is common to classify speech chunks into letters, so we did the same here. Let's extract all distinct letters of the training and test data and build our vocabulary from this set of letters.
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocab_train = cv_swahili_train.map(extract_all_chars, batched=True, batch_size=-1, remove_columns=cv_swahili_train.column_names)
vocab_validate = cv_swahili_validate.map(extract_all_chars, batched=True, batch_size=-1, remove_columns=cv_swahili_validate.column_names)
vocab_test = cv_swahili_test.map(extract_all_chars, batched=True, batch_size=-1, remove_columns=cv_swahili_test.column_names)
# Convert "vocab" column from each dataset to sets and union them
vocab_set_train = set(vocab_train["vocab"][0])
vocab_set_validate = set(vocab_validate["vocab"][0])
vocab_set_test = set(vocab_test["vocab"][0])
# Merge vocabularies
vocab_set = vocab_set_train | vocab_set_validate | vocab_set_test
# Convert the result back to a list
vocab_list = list(vocab_set)
The model has to learn to predict when a word is finished or else the model prediction would always be a sequence of chars which would make it impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important step before training your model. E.g., we don't want our model to differentiate between a and A just because we forgot to normalize the data. The difference between a and A does not depend on the "sound" of the letter at all, but more on grammatical rules - e.g. use a capitalized letter at the beginning of the sentence. So it is sensible to remove the difference between capitalized and non-capitalized letters so that the model has an easier time learning to transcribe speech.
To make it clearer that " " has its token class, we give it a more visible character |. In addition, we also add an "unknown" token so that the model can later deal with characters not encountered in Common Voice's training set.
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
Finally, we also added a padding token that corresponds to CTC's "blank token". The "blank token" is a core component of the CTC algorithm. For more information, please take a look at the "Alignment" section here.
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
We saved the vocabulary as a JSON file.
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
We used the JSON file to load the vocabulary into an instance of the Wav2Vec2CTCTokenizer class.
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
Create Wav2Vec2FeatureExtractor
Speech is a continuous signal, and, to be treated by computers, it first has to be discretized, which is usually called sampling. The sampling rate hereby plays an important role since it defines how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the real speech signal but also necessitates more values per second.
A pre-trained checkpoint expects its input data to have been sampled more or less from the same distribution as the data it was trained on. The same speech signals sampled at two different rates have a very different distribution. For example, doubling the sampling rate results in data points being twice as long. Thus, before fine-tuning a pre-trained checkpoint of an ASR model, it is crucial to verify that the sampling rate of the data that was used to pre-train the model matches the sampling rate of the dataset used to fine-tune the model.
XLS-R was pre-trained on audio data of Babel, Multilingual LibriSpeech (MLS), Common Voice, VoxPopuli, and VoxLingua107 at a sampling rate of 16kHz. Common Voice, in its original form, has a sampling rate of 48kHz, thus we will have to downsample the fine-tuning data to 16kHz in the following.
A Wav2Vec2FeatureExtractor object requires the following parameters to be instantiated:
feature_size: Speech models take a sequence of feature vectors as input. While the length of this sequence varies, the feature size should not. In the case of Wav2Vec2, the feature size is 1 because the model was trained on the raw speech signal 22.sampling_rate: The sampling rate at which the model is trained on.padding_value: For batched inference, shorter inputs need to be padded with a specific valuedo_normalize: Whether the input should be zero-mean-unit-variance normalized or not. Usually, speech models perform better when normalizing the inputreturn_attention_mask: Whether the model should make use of aattention_maskfor batched inference. In general, XLS-R model checkpoints should always use theattention_mask.
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
For improved user-friendliness, the feature extractor and tokenizer are wrapped into a single Wav2Vec2Processor class so that one only needs a model and processor object.
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
Preprocess Data
In addition to sentence, our datasets include two more column names path and audio. path states the absolute path of the audio file.
cv_swahili_train[0]["path"]
XLS-R expects the input in the format of a 1-dimensional array of 16 kHz. This means that the audio file has to be loaded and resampled.
cv_swahili_train[0]["audio"]
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-8.8930130e-05, -3.8027763e-05, -2.9146671e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 48000}
The audio data is loaded with a sampling rate of 48kHz whereas 16kHz is expected by the model. We set the audio feature to the correct sampling rate by making use of cast_column:
from datasets import load_metric, Audio
cv_swahili_train = cv_swahili_train.cast_column("audio", Audio(sampling_rate=16_000))
cv_swahili_validate = cv_swahili_validate.cast_column("audio", Audio(sampling_rate=16_000))
cv_swahili_test = cv_swahili_test.cast_column("audio", Audio(sampling_rate=16_000))
Looking at "audio" again, the sampling rate is now at 16kHz.
cv_swahili_train[0]["audio"]
{'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-7.4556941e-05, -1.4621433e-05, -5.7861507e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05be0c29807a73c9b099873d2f5975dae6d05e9f7d577458a2466ecb9a2b0c6b/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_21921195.mp3',
'sampling_rate': 16000}
We leveraged Wav2Vec2Processor to process the data to the format expected Wav2Vec2ForCTC for training.
First, we loaded and resampled the audio data, simply by calling batch["audio"]. Second, we extracted the input_values from the loaded audio file. In our case, the Wav2Vec2Processor only normalizes the data. For other speech models, however, this step can include more complex feature extraction, such as Log-Mel feature extraction. Third, we encode the transcriptions to label IDs.
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["sentence"]).input_ids
return batch
Training
The data is processed so that we are ready to start setting up the training pipeline. We will make use of 🤗's Trainer for which we essentially need to do the following:
Define a data collator. In contrast to most NLP models, XLS-R has a much larger input length than output length. E.g., a sample of input length 50000 has an output length of no more than 100. Given the large input sizes, it is much more efficient to pad the training batches dynamically meaning that all training samples should only be padded to the longest sample in their batch and not the overall longest sample. Therefore, fine-tuning XLS-R requires a special padding data collator, which we will define below
Evaluation metric. During training, the model should be evaluated on the word error rate. We should define a
compute_metricsfunction accordinglyLoad a pre-trained checkpoint. We need to load a pre-trained checkpoint and configure it correctly for training.
Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the test data and verify that it has indeed learned to correctly transcribe speech.
Set-up Trainer
We started by defining the data collator. The code for the data collator was copied from this example.
Without going into too many details, in contrast to the common data collators, this data collator treats the input_values and labels differently and thus applies to separate padding functions on them (again making use of the XLS-R processor's context manager). This is necessary because in speech input and output are of different modalities meaning that they should not be treated by the same padding function. Analogous to the common data collators, the padding tokens in the labels with -100 so that those tokens are not taken into account when computing the loss.
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
Next, the evaluation metric was defined.
wer_metric = load_metric("wer")
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
Next, we loaded the pre-trained checkpoint of Wav2Vec2-XLS-R-300M. The tokenizer's pad_token_id must define the model's pad_token_id or in the case of Wav2Vec2ForCTC also CTC's blank token 22. To save GPU memory, we enable PyTorch's gradient checkpointing and also set the loss reduction to "mean".
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-xls-r-300m",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
mask_time_prob=0.05,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
)
The first component of XLS-R consists of a stack of CNN layers that are used to extract acoustically meaningful - but contextually independent - features from the raw speech signal. This part of the model has already been sufficiently trained during pretraining and as stated in the paper does not need to be fine-tuned anymore. Thus, we set the requires_grad to False for all parameters of the feature extraction part.
model.freeze_feature_extractor()
In the final step, we defined all parameters related to training. To give more explanation on some of the parameters:
group_by_lengthmakes training more efficient by grouping training samples of similar input length into one batch. This can significantly speed up training time by heavily reducing the overall number of useless padding tokens that are passed through the modellearning_rateandweight_decaywere heuristically tuned until fine-tuning has become stable. Note that those parameters strongly depend on the Common Voice dataset and might be suboptimal for other speech datasets.
For more explanations on other parameters, one can take a look at the docs.
During training, a checkpoint was uploaded asynchronously to the Hub every 400 training steps.
from transformers import TrainingArguments, get_linear_schedule_with_warmup
# Check if you are running on a CUDA-enabled device before enabling FP16
import torch
if torch.cuda.is_available():
fp16_enabled = True
else:
fp16_enabled = False
print("CUDA device not available. Disabling FP16.")
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=15,
gradient_checkpointing=True,
fp16=fp16_enabled, # Enable FP16 only if CUDA is available
save_steps=400,
eval_steps=400,
logging_steps=400,
learning_rate=3e-4,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
remove_unused_columns=False
)
# Define the scheduler parameters
num_warmup_steps = int(training_args.max_steps * 0.1)
All instances were passed to the Trainer set for training.
from transformers import Trainer
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.optim import AdamW
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=combined_train_validate,
eval_dataset=cv_Swahili_test,
tokenizer=processor.feature_extractor,
)
# Create the learning rate scheduler
optimizer = AdamW(model.parameters(), lr=training_args.learning_rate)
total_steps = 1000
scheduler = CosineAnnealingLR(
optimizer,
T_max=total_steps,
eta_min=0, # Minimum learning rate
)
# Define a function to update the learning rate during training
def update_lr():
scheduler.step()
Learning rate is one of the most important hyperparameters in the training of neural networks, impacting the speed and effectiveness of the learning process. A learning rate that is too high can cause the model to oscillate around the minimum, while a learning rate that is too low can cause the training process to be very slow or even stall. In the context of machine learning, the learning rate is a hyperparameter that determines the step size at which an optimization algorithm (like gradient descent) proceeds while attempting to minimize the loss function. A learning rate scheduler is a method that adjusts the learning rate during the training process, often lowering it as the training progresses. This helps the model to make large updates at the beginning of training when the parameters are far from their optimal values, and smaller updates later when the parameters are closer to their optimal values, allowing for more fine-tuning. Several learning rate schedulers are widely used in practice:
Step Decay
Exponential Decay
Cosine Annealing
Cosine Annealing was used to adjust the learning rate during training. Cosine annealing reduces the learning rate using a cosine-based schedule. The form of the cosine annealing is defined as:
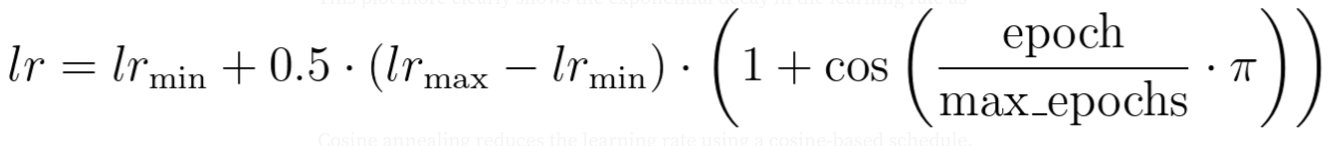
where:
lr_min is the minimum learning rate,
lr_max is the maximum learning rate, and
epoch and max_epochs are the current and maximum number of epochs respectively.
Learning rate schedulers are an important tool in the machine learning practitioner’s toolkit, providing a mechanism to adjust the learning rate over time, which can help to improve the efficiency and effectiveness of the training process. The best learning rate scheduler to use can depend on the specific problem and dataset, and it is often helpful to experiment with different schedulers to see which one works best. In our case, cosine annealing worked pretty well.
Checkout the following for further details:
Subscribe to my newsletter
Read articles from Ronnie Leon directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ronnie Leon
Ronnie Leon
I'm a passionate machine learning engineer with expertise in supervised and unsupervised machine learning techniques, driven to create innovative artificial intelligence solutions for diverse challenges. Leveraging my strong proficiency in Python, I adeptly craft and implement cutting-edge applications, seamlessly integrating artificial intelligence capabilities to guarantee their robustness and efficacy. As an avid learner, I embrace every opportunity to expand my expertise and evolve as a machine learning and backend engineer.