Writing x86 disassembler: start simple
 flysand7
flysand7Before anything I'd like to point out that I used AI to rewrite paragraphs of the text. I'm somewhat bad with words, so getting AI assistance to make an article that's easier to read was nice.
As part of a bigger project (a graphical Linux debugger), I decided to build an x86 disassembler. Before, I tried to make a disassembler but found it hard to finish one that could handle big real programs. This time, I knew I needed a different way to finish the project.
A lot of this story is me explaining why the project worked. Even though many of the choices I made might seem smart now, think of sentences like "I thought it was a good idea to do XXX because..." as "I did XXX and it worked. Here's why:..."
Here's the background: I had some experience with x86 decoding, so I knew it was tricky with lots of special cases and other things mixed in. I also talked with people who knew more about x86 machine code on a Discord call, so I had someone to ask if I got stuck.
Also, I was running out of time. I don't know how normal people handle this, but being someone with ADHD, I had to keep myself busy and not get bored or distracted from the project. My goal was to keep working on the project until it stopped feeling new and interesting.
Problem 1: Setting up
In the past, I used to stop working on my projects too soon because I tried to do everything perfect from the start. This meant writing the command line interface (CLI), making sure the arguments were correct, making sure my memory use was good, naming all my variables right, making sure my plan could handle anything that came along, and dealing with all possible problems right away. But, I ended up with a lot of code that handled problems, a nice CLI, but not a lot of things to offer in terms of functionality.
I've noticed that I really like debugging code. It's easier for me to write a lot of wrong code and then find the mistakes, rather than trying to write everything right the first time.
So, this time, I decided to do things differently. I started with a small working example, chose one instruction, wrote a test, and started making a disassembler that could handle every case of that test. I didn't want to waste time on things that didn't help our main program.
I made a file called 0.asm and put a bunch of mov instructions in it and used nasm to assemble them into a raw binary. The goal was to set up a good foundation for the disassembler so we could easily disassemble other instructions later.
I knew some things about x86 machine code, but not all. For example, I didn't know how the REX prefix extends different fields of the instruction, how SSE uses the data size override prefix in its opcode encoding (which could mean you might need to rewrite the disassembler if you get it wrong), or how many operands an instruction can have.
Because I didn't understand the problem well, I didn't try to write clean or extensible code right away. I thought I couldn't come up with a good way to simplify the problem. It's easier to abstract simple code than to simplify complex code.
I also decided to skip some features, like pretty-printing, until I had something that worked. I added pretty-printing once I had some disassembler action going and got tired of looking at messy struct dumps.
At the end I made my disassembler capable of disassembling the movfuscator output:

Problem 2: too many instructions.
After finishing the mov-disassembler, I saw a big problem - there are too many instructions in x86 machine code. Older disassemblers could handle all the decoding in the code, but now there are hundreds of instructions: general purpose instructions, MMX instructions, SSE, SSE2, SSE3, SSE4, 4.1, 4.2, AVX, AVX2, AMX, and many more.
I thought a table-based approach would work best. In one of my older disassemblers in C, I used X macros to create an encoding table, which I would then go through, checking the opcode bits. This method of matching patterns works well and is fairly easy to extend. But this time I was using Odin, which doesn't have macros, so I needed a different solution.
I wrote a text file, table.txt that would have information about the opcodes of various instructions and used a simple python script to convert that table to Odin code. The table looks something like this now:
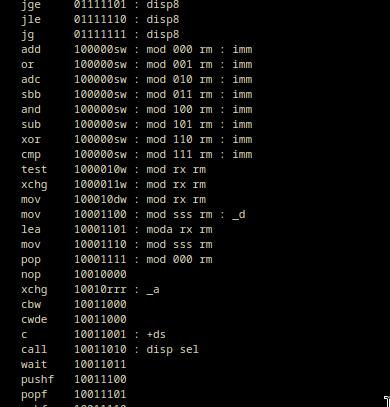
The table.txt file contains a list of opcodes for various x86 instructions. Each line represents an mnemonic, followed by its opcode pattern. The opcode pattern includes placeholders for various components of the opcode, such as mod, rx, rm, the operands, such as imm, disp, sel, implicit operands and flags such as _d, _a that don't have any associated bits and act more like hints to decoder, and finally the encoding flags, such as +n64, +ds. These placeholders represent different parts of the opcode that can vary depending on the specific instruction and its operands.
For example, the line or 0000110w : _a imm represents the OR instruction. The opcode pattern 0000110w indicates that the opcode starts with bits 0000110, followed by a placeholder instruction width field w which represents the width of the operands (byte or word-sized), has implicit AL/AX/EAX/RAX operand and finally imm represents an immediate value.
Similarly, the line push 000ss110 represents the PUSH instruction. The opcode pattern 000ss110 indicates that the opcode starts with bits 000, followed by a placeholder ss which represents the segment register, and then the opcode continues with bits 110.
It was a format that could be extended to fit whatever x86 instruction I encountered and was easy enough to create. In order to fill up that table I used Intel SDM volume 2, appendix B. I'll insert a rant about appendix B at the end of the article, in short, it was a pile of hot garbage, a footgun loaded, aimed and ready to shoot, but worked reasonably well for my purposes.
Once I got this table to decode a few more instructions, like ADD and SUB, I added the rest of general purpose instructions and I wrote a fibonacci function in assembly to decode:
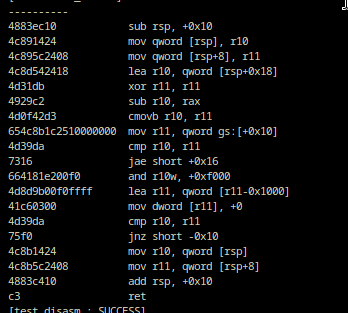
This is just the 4 days of work! By doing trivial table-driving and giving up the questions of performance and clean code I could get something that works in no time at all!
And I managed to make a working prototype before the new year.
Agent 007
Around the time I completed my prototype disassembler, someone on the primeagen discord posted this meme:

Haha, that's kinda funny. You know what else would be funny? If I did
sudo chmod -R 007 ./
to my git repository. I thought it was going to be fine since "others" have the ability to read and write the file and owner still qualifies as "other". In short, that idea of how file permissions work on linux was somewhat wrong and I totally fucked up the permissions on my git repository.
I removed the project folder and re-cloned it from github (good thing It was saved on the cloud, he thought!) and what I found out just before trying to implement the next big feature was that I forgot to push my local changes, so I had to implement REX prefix extensions again. Oh well, it was a bit painful.
Appendix B fiasco
Intel SDM volume 2, appendix B contains opcode table with opcode patterns for various instructions. It looks somewhat like this:
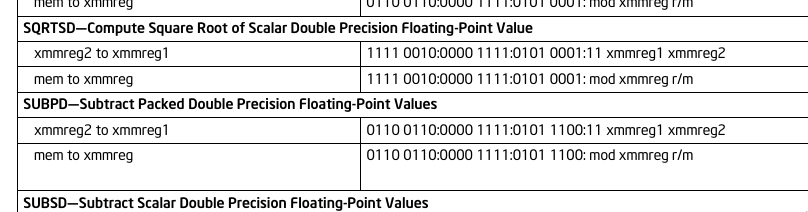
What could go wrong? It's the official Intel manual so it should be completely bug-free right?
At one point they accidentally switched to hex in the binary encoding:

There's one case where they typed mode instead of mod.

Missing space

Every time they have mod/rm byte they split it up into mod=11 and mod != 11 like this:

Really annoying especially since they have a special field mod(a) which means mod that does not equal to 11. You came up with a concept, use it!
So far its all just the nitpicks, but the real pain was MMX when they introduced granularity (gg) field and they don't tell you which values are ok and which aren't. I noticed that some opcodes were overlapping, since I decided to keep my table sorted by increasing opcodes. I had to use other sources to find out which of granularity fields were allowed in any of the MMX instructions.
Takeaway
Start Small: Start with a simple usage case, make sure you got the fundamentals right before you move onto the more complex stuff. Great products start with good first steps.
Understand the problem: You may not find luck implementing something the first time. You may start working on your project and find out that what you wrote is complete garbage. That's fine, understand why it was hot garbage and rewrite it. Remember, this was my 5'th or so attempt at writing a disassembler, and it is the only one that produced reasonable results.
Don't Rush Perfection: Don't worry about writing "good" or "clean" code right away. Focus on getting something working first. Once you have a basic version of the thing, you can start refining your code.
Focus on Essentials: Prioritize essential features over less important ones. Work on the foundation first. For instance, I mentioned that I added pretty-printing later, before that I disassembled into an Instruction struct and just dumped it into the memory. It was the quickest way to get the results on the screen.
Table-Driven Approach: When dealing with a large number of things, a table-driven approach can be effective. Using a scripting language to generate code from a table is a good way to avoid writing a bunch of monotone code.
Subscribe to my newsletter
Read articles from flysand7 directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by