Snippets of Learnings from My First Research Paper
 Priyanshu Mohanty
Priyanshu Mohanty
Nearly a year ago, I was imbued with a Herculean dilemma - whether to focus my endeavors on solely delivering results of a project or go the extra mile and attempt to present at a technical conference. All of this bewilderment for my engineering program's final year capstone project! After much contemplation, I decided to go all in - vying to get my thesis accepted by any coveted research community, in addition to doing it for mere fulfilment of the engineering program's minimum requirements for graduation.
After commencing work in December 2022, I ran into several challenges - the sophistication of our problem statement and the domain itself (speech emotion recognition - a popular NLP problem), and inefficient coordination at times among my team members, to name a few. Despite these hindrances, the experience gained in the process was extremely enriching - I got to learn several new things that were hitherto unbeknownst to me. Consequently, I'd like to share a few of my learnings and the knowledge subsumed as a result:
Importance of Data Augmentation: Data augmentation incorporates amplifying the dataset by applying various transformations to the existing data. A critical problem in the context of predictive models is the lacuna in sufficient data to draw tangible conclusions from. Data augmentation can thus bridge this gap; by introducing newer scenarios and certain unprecedented situations that can preclude the conundrum of overfitting (fitting too closely with the training data, which is insufficient, and not adaptable to changes) from coming to fruition.
Although our proposed methodology doesn't factor in any ounce of data augmentation; it became more and more apparent from our research study of various other papers of how effective this paradigm was in significantly enhancing the performance of the models. In this context, we can generate new forms of audio data based on altering the speed of the audio signal, the pitch of the audio, or by adding some random noise to this signal, among other ploys.
Our ensemble transformer model without augmentation achieved a peak accuracy of around 68%, which was a significant upgrade over various other existing models; however, it was still pegged lower in comparison to the very same models' performance when they were treated with augmented data. Further endeavor would, perhaps, reveal whether this can be fruitful or not.
Features of Audio: Until this point in time, neither my teammates nor I had ever worked on a type of data other than text. This is what made us initially a tad apprehensive. Gradually, over the course of time, with subsequent research and the zeal to learn, we uncovered for ourselves several key characteristics of audio data. One of our primary findings was that audio can be classified as a "time-series" intrinsic data. What this implies is that audio has variable parameters based on temporal features. This led us to secondary revelations - the features of audio itself that may alter with time, such as - pitch, loudness, waveforms, et cetera, to name a few. These features would again hinge on quantifiable or measurable attributes like amplitude, frequency, etc.
But this doesn't merely end here. We need a mechanism to relay information from this data to our predictive model efficiently. This is what would entail data preprocessing and some preliminary exploratory data analysis to both comprehend the dataset itself and the trends in data, which calls upon some level of comprehension and knowledge of the nature of audio data itself (as mentioned above).
We then stumbled upon certain secondary and tertiary features of audio, such as zero-crossing rate, spectral centroid, spectral roll-off, short-term Fourier transform (STFT), Mel-spectrograms, Mel-Frequency Cepstral Coefficients (MFCC), to name a few. Much of these features were appurtenant to spectral characteristics of audio, which in turn, were composites of the basic features like pitch, loudness, discussed above. These features reveal a ton of information on the sentiment of the audio itself; which was the primary objective of our project for prediction. As an example, spectral centroids for "weaker" emotions like "neutral" or "calm" will be lesser as juxtaposed with "stronger" emotions like "angry" or "fearful". This is in empirical correlation with observed properties of human acoustics - stronger emotions carry more ranges of acoustic parameters.
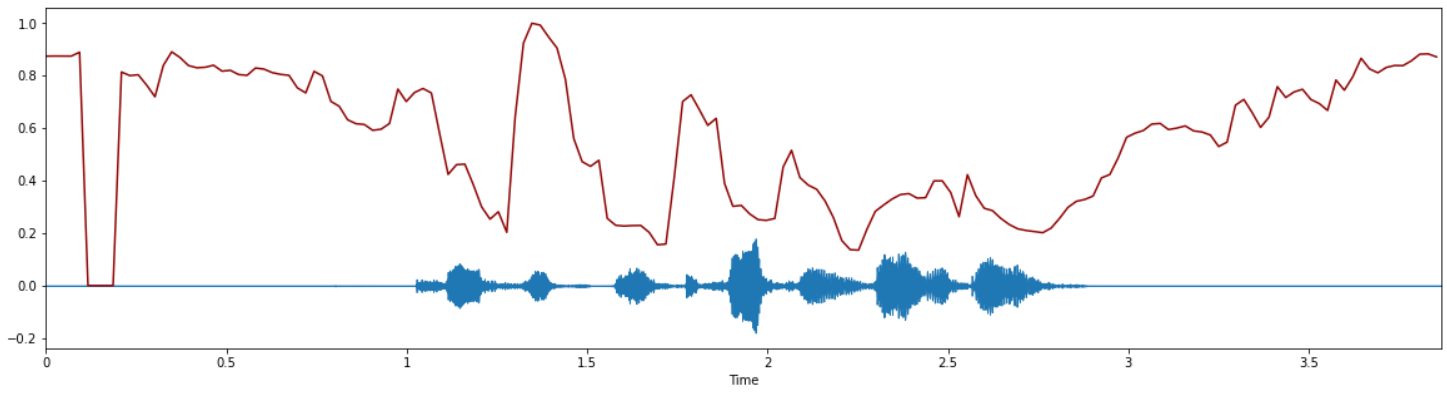
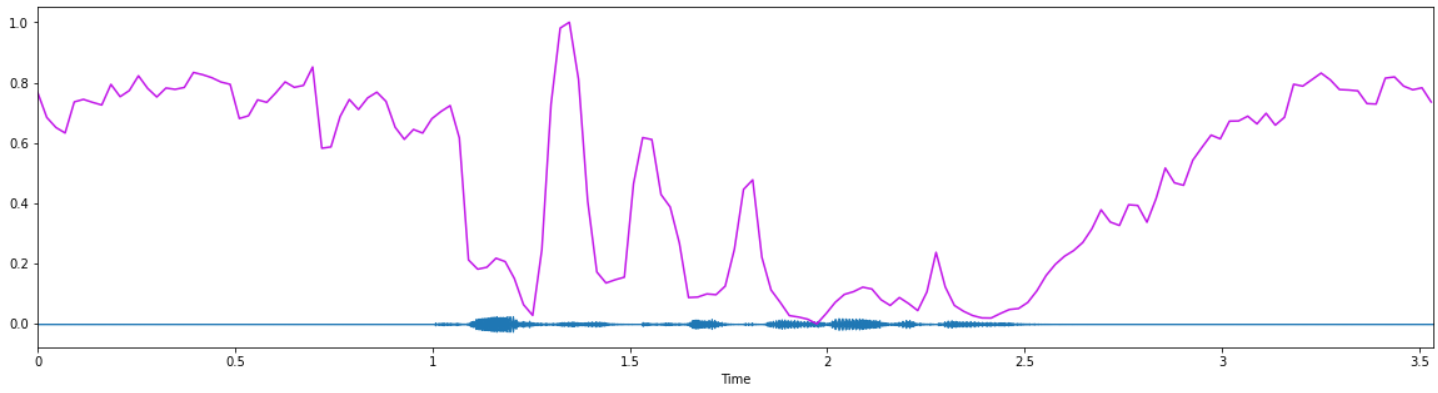
Figure (top): Spectral centroid for male "angry" emotion.
Figure (bottom): Spectral centroid for male "calm" emotion.
Notice how the spectral centroid readings of the first figure are much greater as compared to the second figure, indicative of how stronger emotions are more pronounced.
Relying On Multiple Performance Metrics: Prior to beginning work on this project, I was under the impression that accuracy/precision were the same thing and were exhaustive indicators of the performance of any deep learning-based model. Relentless digging exposed my fallacious assumptions and made me amend my views. It became lucid that one single performance metric alone cannot do justice to qualify the robustness or the efficacy of the model - simply because it can never paint the whole picture. Some of my key learnings on this are as listed:
--> Accuracy represents the fraction of correct predictions (true positives and true negatives) out of all the predictions made. Precision, on the other hand, represents the distinguishing power of the model from true positives and true negatives. Whilst this may sound similar, it is not; as both have different viewpoints of evaluating the model.
--> There are other metrics like recall, F1 score, sensitivity, etc., all of which are based on quantitatively evaluating the model based on its classification power. The classification seeks to label "true" or "false" for each of the sound samples based on each of the different emotion classes. And it is these metrics that reflect more about where the model may potentially be lagging. For instance, when we plot the confusion matrix to correlate the "true" label and the "predicted" label which yields information such as - "true positives", "false positives", "true negatives" and "false negatives"; this can be used to inspect the quality of correct and incorrect predictions in terms of the affirmative and negative labels. The aim of any SOTA model should be to accumulate as many of the "true" labels as possible and minimize the occurrence of "false" labels.
--> As mentioned earlier, the confusion matrix presents us with a gold mine of information on how correctly a model is performing. There is one latent layer of tidings that it sometimes presents us with - the availability or unavailability of data for pertinent classes or labels. It became very apparent from our experimentation on the RAVDESS dataset that the predictions almost always correctly identified the "true negatives", but there were a large number of "false positives" as well, which signifies that the occurrence of "negative" labels was much more than the occurrence of "positive" labels -- which can lead to a phenomenon known as underfitting in the training sample data for "positive" labels whereby, the model would fail to capture the complexity of such data, and can often yield poor results, as the model is devoid of sufficient data to conclude from.
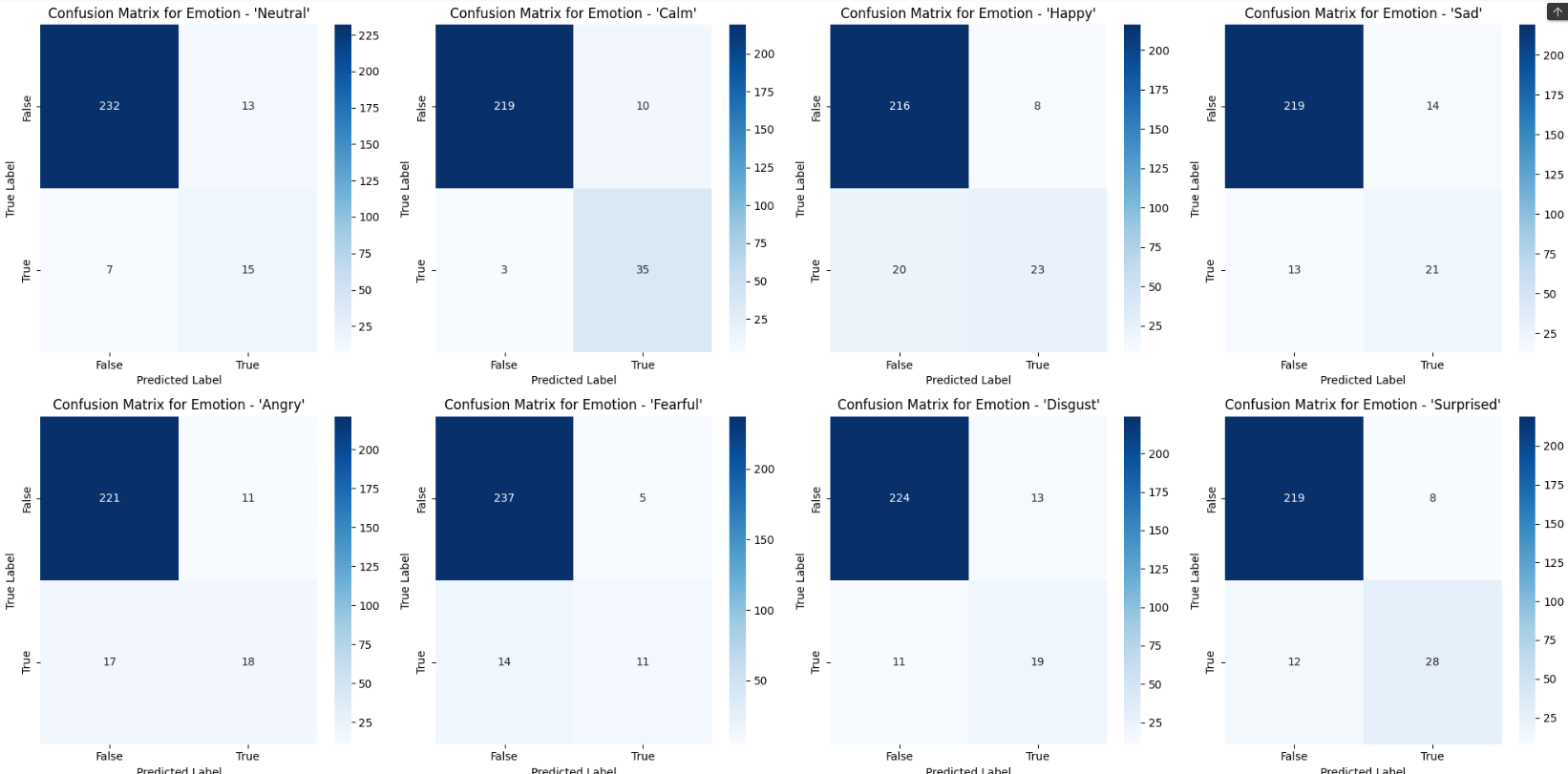
Confusion Matrix Representing Various Emotion Labels
Transformers & Attention Mechanism: Back in the latter half of 2022, when I, along with my teammates, had finalized the problem statement of our capstone project and were pondering on different approaches, something amazing happened. The whole world was introduced to the colossal powers of generative AI with its inception based on the release of the popular LLM (Large Language Model) chatbot ChatGPT. Mesmerized and marveling at the technological leap in AI that had been accomplished; I got inquisitive to learn more about it. That is when I was first introduced to the concept of transformers - now a class of well-known deep-learning architectures used in several exemplary models to solve a plethora of problems.
Touted as a significant breakthrough in the research of DL models, it provides certain advantages such as requiring less training time and alleviating the problem of vanishing gradients (explained in depth later) to a great extent as juxtaposed with recurrent neural networks (RNNs) or long short-term memory (LSTM). A pioneering innovation as presented in the "Attention Is All You Need" research paper (our base paper for foundational knowledge) was the introduction of attention mechanism, more particularly, self-attention; which rids the models' dependency on convolutional or recurrent neural networks.
This specific paper introduced "scaled dot-product attention", an enablement for the model to focus on different parts of an input sequence (may be text or audio data) with varying levels of attention. The advantage of such an attention mechanism is that this allows the model to assign different weights to different words in the input sequence when processing a specific word. This is achieved by computing something known as attention scores. Input sequence is transformed into three vectors: Query ('Q'), Key ('K') & Value ('V'). Scaled-dot product attention is then formulated as:
$$Attention (Q,K,V) = softmax (\frac{QK^T}{\sqrt{d_k}})V$$
$$d_k :the dimension of the key vectors.$$
The term inside the softmax activation function is what's termed as "attention score". This attention score is instrumental in quantifying the relevance or importance of one element in a sequence to another. Consequently, it renders the following advantages:
Temporal Focus: Certain parts of the audio sequence might carry more emotional information than others. Attention scores can help the model focus on the relevant time frames where emotional cues are more prominent.
Word Importance: Attention can be used to identify important words or phrases that contribute significantly to the expression of emotion - crucial when emotions are expressed through spoken language.
Contextual Information: Understanding the emotional context often requires considering the surrounding context. Attention mechanisms allow the model to capture dependencies between different parts of the input sequence - solving the long-term dependency problems that are created in RNNs; and also optimizing over LSTMs.
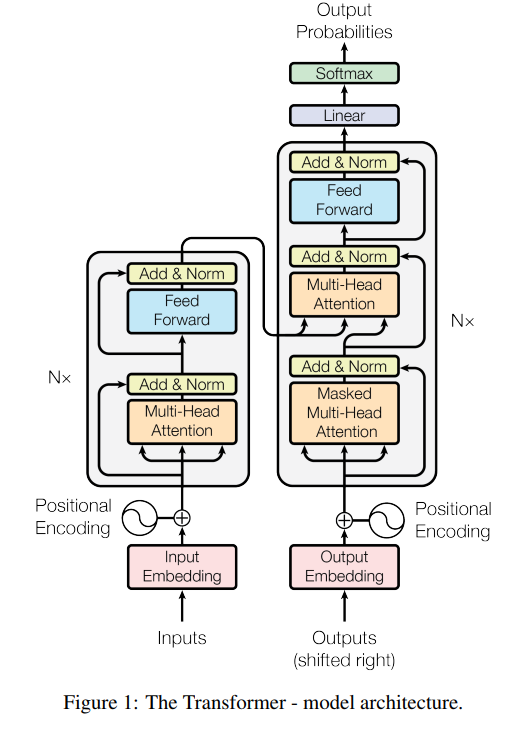
Source: Attention Is All You Need by Google
Vanishing Gradients Problem: A critical problem that may arise during the training of deep neural networks is "vanishing gradients". It refers to the phenomenon of a radical drop in gradients of the loss function with respect to the weights during the course of training. This leads to detrimental and undesirable results, wherein the weights of the network aren't updated or in certain extreme cases even stop changing altogether - causing a significant toll on the ability of the network to learn and make accurate predictions - as the algorithm faces difficulty in making meaningful updates to model parameters.
This came up a very prevalent problem in many well-known deep neural architectures such as CNNs or RNNs. Fortunately, many contemporary and customary practices involved in a typical deep learning routine attempt to address or alleviate this problem. Some of these include but are not limited to - activation functions, normalization techniques, etc.
Attention mechanisms as introduced in transformers models can also work to alleviate this problem to some extent, along with the other contrivances such as positional encoding, normalization which are already intrinsically presented in the transformer models. All of these methods hinge on a plethora of mathematical computations which hinder the gradients from getting infinitesimally small in magnitude.
Keeping these boons in mind, we can accordingly custom design our transformer models to reap their benefits. The original paper makes use of a complex multi-head attention mechanism with positional encoding which weren't utilized for our use-case - but we did retain the encoder-decoder architecture and implemented our custom bidirectional-LSTM model with a scaled-dot product self-attention mechanism.
Whilst these may not be the only snippets of learnings technically; these were some of the most important ones. In addition to this, my research imbibed in me qualities of patience, perseverance, teamwork and communication; skills that are equally important to thrive and succeed. Feel free to check out my published paper at this URL and do leave any feedbacks or suggestions for improvements on the same.
URL to the paper: An Ensemble Transformer Model for Speech Emotion Recognition
Subscribe to my newsletter
Read articles from Priyanshu Mohanty directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by