Data formats in APIs
 Saketh K
Saketh K
Before diving deep into Api types it's important to understand data formats.
Picture this: You're sending a message to your dear friend, but you don't want anyone else to be able to decipher it. So, you decide to encrypt the message using a specialized language only the two of you know. This way, even if a third party intercepts the message, they won't be able to comprehend its true intention. This code-protected message is what we refer to as the "payload." In the realm of APIs (Application Programming Interfaces), the concept of a payload is strikingly similar. When you interact with an API, you're essentially exchanging data, just like you do with your covert message. It's important to remember that the payload is the crucial component of your data, carrying the significant information you wish to transmit or receive. Grasping the concept of payloads is essential in understanding the world of APIs.
What is a payload?
When it comes to APIs, the word "payload" refers to the essential data that is passed between a client and server during an API call. This includes all of the vital information being transmitted or received within the request or response of the API. Having a clear understanding of the payload structure and properly managing the data within it is essential for effectively integrating with external APIs. This ensures a seamless and successful exchange of information between systems.
Here's a breakdown of how the term is used in different parts of the API process:
Request Payload:
When using an API, specifically HTTP-based APIs such as REST or GraphQL, the data you send to the server is known as the request payload. This type of data is usually in the form of JSON or XML and includes the necessary parameters or information needed to execute a specific task.
For example, in a POST request to create a new resource, the payload might include the data for the new resource in JSON format.
jsonCopy code{ "name": "New Resource", "description": "This is a new resource." }
Response Payload:
When a request is sent to the API server, it will respond with a payload. This payload will contain the data that is important for the client or consumer. Similar to the request payload, the response payload is usually in either JSON or XML format.
For example, in a response to a GET request for information about a user, the payload might look like this:
jsonCopy code{ "id": 123, "username": "example_user", "email": "user@example.com" }
Webhooks Payload:
Webhooks serve as a link between systems, allowing for instantaneous communication. When a particular event takes place, the server sends a payload to the client, which may contain relevant details or updates related to the event.
For example, in a webhook notification about a new order, the payload might include details about the order.
jsonCopy code{ "event": "new_order", "order_id": "ABC123", "total_amount": 50.99 }It is absolutely essential for developers who are utilizing APIs to have a full grasp of the payload. This understanding allows them to effectively organize and comprehend the data that is being sent or received. API documentation usually outlines the payload's contents and format, ensuring that both the client and server are on the same page, facilitating seamless communication.
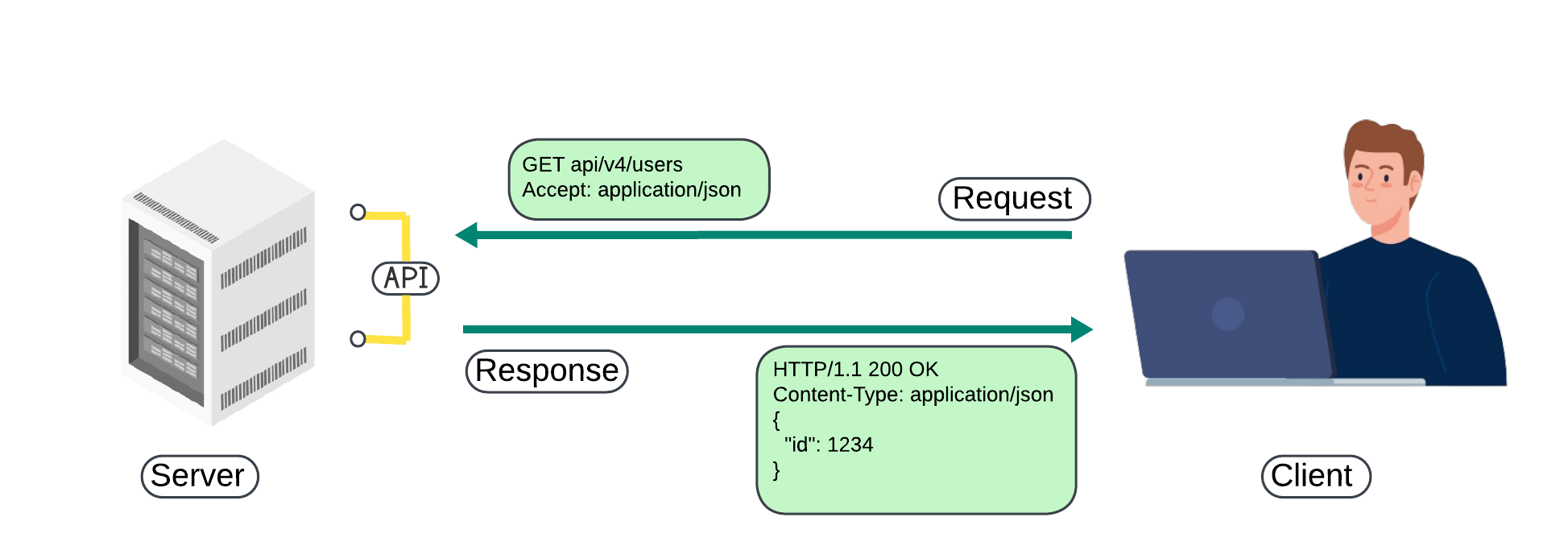
Common data formats in APIs include:
JSON (JavaScript Object Notation):
A lightweight, human-readable format that is widely used for data interchange. It's easy to parse and generate, making it popular in web APIs.
Here is an example of JSON:{ "person": { "name": "Alice", "age": 25, "isStudent": true, "address": { "city": "Wonderland", "zipcode": "12345" }, "interests": ["reading", "painting", "gardening"] }, "company": { "name": "Tech Innovators", "industry": "Technology", "employees": 1000, "locations": ["City A", "City B", "City C"] } }In this example:
There is a "person" object with details about an individual, including their name, age, student status, address, and interests.
There is also a "company" object with information about a hypothetical technology company, including its name, industry, number of employees, and locations.
XML (eXtensible Markup Language):
It is a human-friendly format often utilized in APIs to support hierarchical data. It is slightly more verbose than JSON but provides robust functionality.
<root> <person> <name>Alice</name> <age>25</age> <isStudent>true</isStudent> <address> <city>Wonderland</city> <zipcode>12345</zipcode> </address> <interests> <interest>reading</interest> <interest>painting</interest> <interest>gardening</interest> </interests> </person> <company> <name>Tech Innovators</name> <industry>Technology</industry> <employees>1000</employees> <locations> <location>City A</location> <location>City B</location> <location>City C</location> </locations> </company> </root>In this XML example:
The root element is
<root>, containing two child elements<person>and<company>.The
<person>element has nested elements for name, age, student status, address, and interests.The
<company>element similarly has nested elements for name, industry, number of employees, and locations.
XML uses tags enclosed in angle brackets to define elements, and the hierarchy is represented by the nesting of these elements. Unlike JSON, which is more concise, XML relies on explicit opening and closing tags. XML is often used for configuration files, data storage, and communication between different systems.
YAML (YAML Ain't Markup Language):
Known for its simplicity and readability, YAML is often used in configuration files and some APIs. It's less verbose than XML.
person: name: Alice age: 25 isStudent: true address: city: Wonderland zipcode: 12345 interests: - reading - painting - gardening company: name: Tech Innovators industry: Technology employees: 1000 locations: - City A - City B - City CIn this YAML example:
The indentation is crucial for defining the structure. Indentation is used instead of explicit delimiters.
Colons (
:) are used to separate keys from values.Lists are represented by the dash (
-) followed by space.YAML is sensitive to indentation and relies on it to indicate the structure of the data.
YAML is known for its readability and ease of use, making it a popular choice for configuration files and situations where human readability is important.
Protobuf (Protocol Buffers):
Google created a binary serialization format known for its exceptional efficiency in both size and speed, making it a popular choice for performance-critical situations. This format effectively serializes structured data, ensuring rapid data exchange between systems. Unlike JSON and YAML, Protobuf may not be easily read by humans, but it excels in streamlining data transmission.
To use Protobuf, you define a schema in a .proto file, specifying the structure of your data. Here's an example of a simple .proto file:
syntax = "proto3"; message Person { required string name = 1; required int32 age = 2; required bool is_student = 3; message Address { required string city = 1; required string zipcode = 2; } repeated string interests = 4; optional Address address = 5; } message Company { required string name = 1; required string industry = 2; required int32 employees = 3; repeated string locations = 4; }In this Protobuf example:
PersonandCompanyare message types.Each field within a message type has a data type and a unique field number.
The
Addressmessage type is nested within thePersonmessage type.Fields can be marked as required, optional, or repeated (similar to a list or array in other formats).
Once you define the .proto file, you use a compiler (like the protoc compiler) to generate code in your preferred programming language. This generated code allows you to serialize and deserialize instances of your defined message types.
This is just a schema definition; the actual serialized binary data will look quite different and is not intended to be human-readable. The efficiency and speed of Protobuf make it a popular choice for high-performance applications and network communication where data size and speed are critical.
MessagePack:
A binary format that is more compact than JSON, providing faster serialization and deserialization similar to Protobuf in terms of binary representation. It is used in scenarios where data size and speed are critical.
Here's an example of how you might represent the same data using MessagePack:
import msgpack data = { "person": { "name": "Alice", "age": 25, "isStudent": True, "address": { "city": "Wonderland", "zipcode": "12345", }, "interests": ["reading", "painting", "gardening"], }, "company": { "name": "Tech Innovators", "industry": "Technology", "employees": 1000, "locations": ["City A", "City B", "City C"], }, } # Serialize data to MessagePack format packed_data = msgpack.packb(data) # Deserialize MessagePack data unpacked_data = msgpack.unpackb(packed_data) print("Original data:", data) print("Packed data:", packed_data) print("Unpacked data:", unpacked_data)In this example,
msgpack.packbis used to serialize the data, andmsgpack.unpackbis used to deserialize it. The resulting MessagePack binary data is not human-readable, but it is more compact and efficient for data exchange.Keep in mind that the specific library and methods might vary depending on the programming language you are using. MessagePack is available in various programming languages, and you can find libraries and tools for most popular languages.
Subscribe to my newsletter
Read articles from Saketh K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by