Stream Symphony: More Than Enough Kafka
 Ladna Meke
Ladna Meke
Introduction: Navigating the Data Maze
Feel free to skip this section if you want to dive right into the technical bits.
Imagine you want to order your favourite burger from your neighbourhood spot “Akaso Burger” - you visit the website/mobile app, select your item, and tap the order button. The button is disabled, displaying a spinner to indicate processing, and then re-enables. You get a success notification on the website or the app, quickly followed by an email confirmation 2 seconds later. Shortly after, an email arrives from your bank or PayPal, notifying you of the deducted amount due to your burger purchase. Now let’s imagine it’s almost Christmas, and Akaso Burger realizes that besides you ordering daily, ten thousand other people in your neighbourhood seem to love having their burgers. The company decides to have a 24-hour window where all burgers are 70% off, but a user can only order 5 burgers within this time! You want to take advantage of this, but so do over 10,000 people around you. You repeat the process you’re familiar with - order -> wait for the button to be disabled -> get notification -> get email confirmation, but this time things are a bit slower.
Most of the internet is powered by http: a straightforward request-response protocol. This means that a client initiates a request to a server, and waits some time for a response. In this case, the client is the website or the mobile app that triggers the order request when you click the button. The server is the backend handling the request - it does some operations (e.g. confirming there are enough resources) and then returns a response to the client. This is the standard we’re used to, but what happens when a website has to handle lots and lots of requests? The website can simply continue with the request-response paradigm we know and love, but this means the wait time for a response greatly increases as more people start ordering from Akaso Burger. When the server receives an order, it:
Validates that the user hasn’t ordered more than 5 burgers in 24 hours
Checks if there is enough resources (ingredients, manpower, time) to handle the order
Charges the linked card or PayPal
Confirms the order on the app and at the same time:
Sends a confirmation email
If we go with the http request-response approach, we would need to do the steps above for each order, going through the flow linearly before arriving at the last step. As more users rush to Akaso Burger’s app, this starts getting noticeably slow because each request has to wait for its turn to be processed. As the number of requests increases, the system's capacity to handle them concurrently becomes a bottleneck. What if we forego our full synchronous approach and rethink our architecture? For example, we can notify the user that the order has been received and is being processed. A few seconds later, we notify the user that the order has been confirmed. We can decide to do step 1 above instantly and give the user immediate feedback while we handle the processing in the background. Since we have now broken out of the typical request-response cycle we know and love, how do we handle this huge stream of data now lying somewhere in the background as close to real-time as possible? This is where tools such as RabbitMQ and Apache Kafka come in.
Asynchronous Processing: The Contenders
When it comes to asynchronous processing, RabbitMQ and Kafka emerge as leading contenders. Both serve as robust message broker systems designed for near-real-time, scalable, and high-speed asynchronous processing, but they adopt different approaches. IBM defines a message broker as "a software that enables applications, systems, and services to communicate with each other and exchange information". Let's explore the distinctions before delving into the unique strengths of Kafka.
Kafka's Approach:
Durability: Messages in Kafka persist even after delivery/consumption.
Message Replay: Kafka can replay messages, allowing the resend of the same message.
Speed and Scalability: Built for high throughput, Kafka employs sequential I/O, avoiding random-access memory overhead. By not deleting messages, Kafka conserves compute cycles.
Consumer Pull Model: Unlike pushing messages to consumers, Kafka consumers pull or poll messages from the broker, offering consumer flexibility and efficient resource utilization.
RabbitMQ's Features:
Priority Queues: RabbitMQ supports priority queues, allowing some messages to be routed to higher-priority queues for expedited processing.
Acknowledgment System: Consumers in RabbitMQ acknowledge message receipt, and this information is relayed to the producer, ensuring a reliable message delivery system (at the cost of higher latency).
Ease of Learning: With a simpler architecture, RabbitMQ is considered more straightforward for users new to asynchronous processing.
In the following sections, we'll dive deeper into Kafka's unique architecture.
Components of Kafka
In the previous section, we mentioned that the messages (data) are “delivered”. What exactly does this mean? Kafka has several components that enable it to send and receive messages. Producers send these messages to the broker, which in turn sends (delivers) the messages to one or more consumers. Since the broker itself does not know what the message is, the consumer needs to know what message is relevant to itself. This is aided by using topics - the producer publishes the message to a specific topic on the broker and the consumer(s) listen for messages only for that topic.
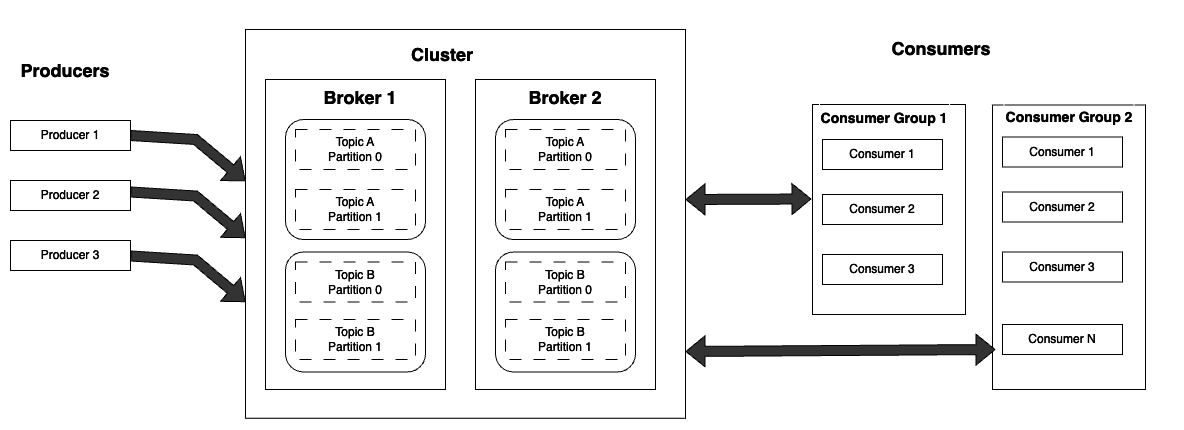
Let’s use a simple metaphor to explain this: Imagine you are a postman delivering packages in a building filled with engineers, mathematicians, and doctors. Each group has a numbered mailbox to receive packages relevant to them (e.g. 1 for Mathematicians, 2 for Engineers, etc). You label each package with the appropriate number and drop it off with the concierge. The concierge uses the number to identify what mailbox to place the package in. Every once in a while, a mathematician, engineer, or doctor walks to their designated mailbox to check if a new package has arrived. In this analogy, you are the producer, the concierge is the broker, the number is the topic, and the people checking the mailboxes are the consumers.
Broker
A central server with the Kafka program running, a broker is the cornerstone of the Kafka system. Because Kafka was designed with scalability and a high degree of fault tolerance and availability in mind, most setups do not use just one broker, but rather a combination of brokers working together called a cluster. These brokers can be deployed in different availability zones to minimize the risk of downtime. The broker is responsible for:
Message Persistence: Stores and manages messages produced by Kafka producers.
Topic and Partition Management: Organizes messages into topics, divides topics into partitions, and manages the partition creation, replication, and reassignment. Each partition has one leader and multiple followers. The broker is responsible for leader election and ensuring that the leader is actively serving read and write requests.
Producer Communication: Acts as the endpoint for Kafka producers to send messages. Producers connect to brokers and publish messages to specific topics. The broker is responsible for receiving and acknowledging these messages.
Consumer Communication: Consumers connect to brokers to subscribe to topics and receive messages. It also maintains an offset for each consumer to keep track of the last consumed message within a partition, as well as managing and updating the offset (position) for each consumer within a partition. This allows consumers to resume reading from where they left off in case of failures or restarts.
Log Compaction: Supports log compaction for topics, retaining only the latest value for each key.
Security and Access Control: Implements security features such as authentication and authorization to control access to topics.
Monitoring and Metrics: Provides metrics for tracking the health, performance, and resource utilization of the Kafka cluster.
Dynamic Configuration: Support dynamic configuration changes so administrators to modify configurations without requiring a restart.
Producer
Producers are client code interacting with the Kafka broker, responsible for sending messages to specified topics. While multiple producers can be created, reusing a single producer generally offers better performance.
When the producer starts up, it establishes a TCP connection with the broker(s) to get metadata such as topics, partitions, leaders, and clusters. It also opens another TCP connection for message sending when the producer send() function is called. Subsequent send() calls to the same topic reuse the same TCP connection. The default TCP connection between the producer and broker is unencrypted plaintext, eliminating the overhead of the brokers decrypting the messages. Because plaintext is not suitable if any of the servers are public, Kafka allows the producer (and consumer) to select a connection protocol during initialization. It is recommended to use a secure option like SSL (might not be needed when both servers are in a VPC). Periodically, according to the config metadata.max.age.ms, a refresh of the metadata happens to proactively discover new brokers or partitions. For a deeper dive into producer internals, check this awesome post.
The exact timing of when a message is sent can vary depending on the configuration and the acknowledgment settings. For the most part, message sending happens asynchronously. When the producer send() function is called, it receives an acknowledgment from the broker even if the message has not been fully committed. When batching is enabled (the default), the producer adds any message to its internal buffer and attempts to send it immediately according to the batch size (default of 16KB). If the linger config is enabled, the producer will wait for the linger milliseconds before sending the batch. This is aimed at increasing throughput but at the expense of increasing latency. For example, a linger.ms of 5 means that a 5ms artificial delay is introduced before the producer sends the batch. This increases the chances of messages being sent in a batch since the producer would “linger” for 5ms to see if more messages arrive and add them to the batch. It should be noted though that if we already have the batch size worth of messages, this setting is ignored and the producer sends the batch immediately. In summary, producers will send out the next batch of messages whenever linger.ms or batch.size is met first.
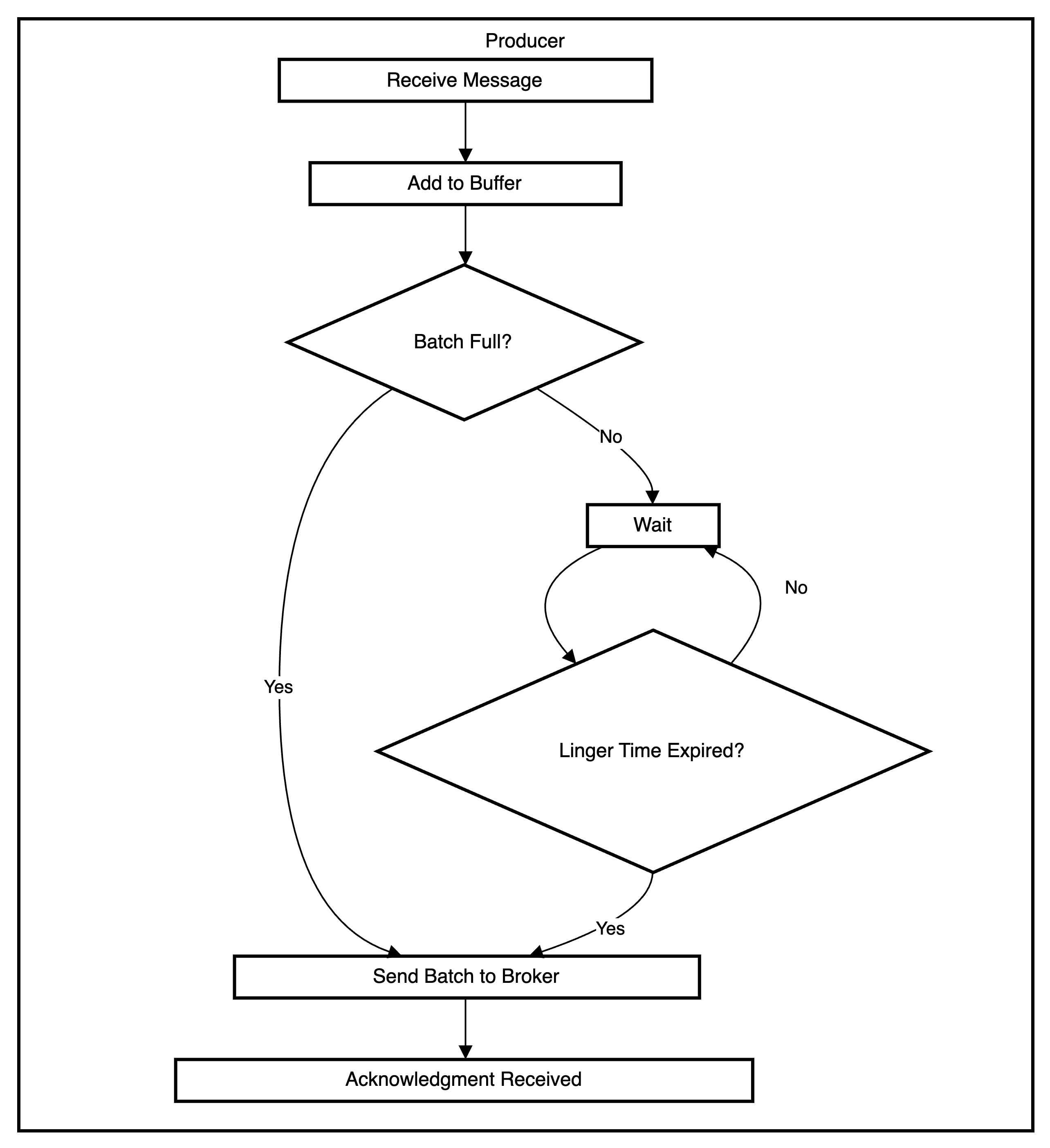
We can force the messages to be sent (irrespective of the linger and batch settings) by flushing the producer. This is a blocking operation and effectively makes the producer synchronous because it has to wait for acknowledgement of delivery from the broker. As a result, flushing should be used sparingly (e.g low throughput environments or in tests). Another point worth mentioning is that the buffer memory is finite, so if more messages arrive over the buffer.memory limit, the producer will be blocked for a configurable time max.block.ms after which it throws an exception. The buffer memory might be full if the producer is receiving messages faster than it is sending, or if the broker is down for any reason.
Topic
A Kafka topic serves as a way to organize messages, akin to organizing files in folders. Producers choose a topic to write to, while consumers select the topic they wish to read from. Topics are created and managed using CLI commands specific to the operating system: kafka-topics.bat for Windows and kafka-topics.sh for Mac and Linux (usually in a startup script).
Topics, including those created dynamically, are stored and replicated on Kafka brokers. Kafka automatically creates certain topics, such as the __consumer_offsets topic, as part of its operation. The ability to dynamically create topics is governed by the auto.create.topics.enable setting on the broker. When enabled, the broker creates a topic and partitions when:
Producer writes to a topic that isn’t currently created.
Producer fetches metadata for a topic that does not exist
Consumer reads from a topic that does not exist
However, creating topics on the fly can lead to maintenance challenges as a typo can cause unwanted topics to be created. Topics created this way also share the same replication factor, number of partitions, and retention settings.
Kafka uses topics to parallelize processing and scale horizontally by splitting messages into different partitions in different brokers. We will discuss partitions in more detail later on.
Consumer
A Kafka consumer is a client application that reads data from a specific topic, more precisely from a particular partition within that topic. Similar to producers, consumers establish a TCP connection with the broker when started. Unlike traditional systems where messages are pushed to consumers, Kafka's design encourages consumers to poll the broker for new messages at their own pace. The reasons for this pull-based approach are detailed in Kafka's consumer design documentation.
Consumers continuously poll the broker for new messages, returning a number of messages defined by max.poll.records alongside the offsets for these messages. Kafka uses offset to keep track of the position of the message the consumer has read. The default behaviour of the consumer is to auto commit offsets enable.auto.commit, which means that every 5 seconds (or auto.commit.interval.ms), the consumer updates the broker with the current offset. This is handled by the client libraries making a request to the broker to update the internal __consumer_offsets topic. Consider disabling auto-commit and using manual commit in production to avoid potential issues with offsets. This is well captured in the “Auto Commit” section of this article which is pasted here for visibility:
With auto commit enabled, kafka consumer client will always commit the last offset returned by the poll method even if they were not processed. For example, if poll returned messages with offsets 0 to 1000, and the consumer could process only up to 500 of them and crashed after auto commit interval. Next time when it resumes, it will see last commit offset as 1000, and will start from 1001. This way it ended up losing message offsets from 501 till 1000. Hence with auto commit, it is critical to make sure we process all offsets returned by the last poll method before calling it again. Sometimes auto commit could also lead to duplicate processing of messages in case consumer crashes before the next auto commit interval.
Consumers periodically send heartbeats to the broker to signal their activity and ensure the broker is aware of their current status. This occurs during message polling or when committing offsets, whether automatically or manually.
Imagine a situation where a topic is receiving 20,000+ messages in a topic per second. If we have a single consumer reading from that topic, message consumption would be considerably slow. Kafka was built for rapid real time message handling, so how does this happen? With the help of partitions and consumer groups which will be discussed in the next sections.
Beyond the Basics: Digging Deeper
Partitions and Replication
In previous sections, we established that producers write data to a topic by selecting a partition. It is important to think about Kafka’s mental model at the partition point level and not at the topic level. What exactly are partitions and why is this important for Kafka.
Let’s imagine you are participating in a Burger eating competition where you have to eat 1000 burgers. It would take you days to consume all 1000 burgers, but what if you could have your brother help eat some burgers? In this case, you could place 500 burgers in Box A and give your brother 500 burgers in Box B. Now this means you both can finish the combined 1k burgers in shorter time. What if you include your sister and nephew as well? Now you can have 4 boxes each containing 250 burgers that would be finished much faster because all 4 of you are eating the burgers at the same time, in parallel. Parallelism helps you rapidly speed up your consumption. What you have essentially done is to partition your burgers into 4 boxes so you can have 4 consumers finish these burgers much quicker. Let’s take the analogy up a notch - imagine if it is crucial for these 1k burgers to be consumed, and all 4 of you are in the same room eating the burgers. If an emergency happens in the room e.g fire alarms goes off, all four people have to stop eating the burgers. What if the first two people take 250 burgers each in one building, and the other 2 people take 250 burgers into the adjacent building? Now if any incident happens in one building, at least two people will still be eating burgers and the other two can join them later. What you have done now is called **redundancy (**or fault tolerance) - a fault in one building does not stop operations because the other building is available to continue.
This is exactly how Kafka handle partitions! Partitions act as logical divisions that aid in load balancing, parallel processing, and fault tolerance. When a topic is created, the number of partitions can be defined, or it falls back to num.partitions on the broker config which defaults to 1. When producers write to a topic, they can select the partition key to write to. If the partition key is not set when writing to the topic, Kafka defaults to using the round-robin partition strategy - that is for N partitions, it cycles from partition 0 to N and loops back to 0. With the partition key set, producers can consistently route messages to the same partition (ideal for maintaining order or grouping related messages). Partitions are distributed across brokers, just as in our analogy above, the boxes can be in different buildings instead of one. This means if a broker hosting one partition fails, other brokers can still serve their partitions. Without partitions, Kafka can still operate with multiple brokers, but partitions enable the distribution and parallel processing of data.
Key Concepts:
Load Balancing: Partitions enable load balancing, distributing data across multiple consumers.
Parallel Processing: Parallelism is achieved by allowing multiple consumers to process partitions simultaneously.
Fault Tolerance: Redundancy ensures continued operation even if a broker hosting a partition fails.
To understand replication, let’s tweak our analogy. Now instead of being in a burger eating competition, you are in a book reading competition. You need to be able to read 1000 books and know what books have been read. As before, we have spread the books into 4 different boxes in two different buildings. Let’s say Building 1 has Box A and B and Building 2 has box C and D. If Building 1 has a fault, all the books in Boxes A and B cannot be read, as we can only read books in Boxes C and D in Building 2. While Building 1 is down, if the two people that were initially reading the books in boxes A and B decide to go to Building 2, they both do not have access to the books they were reading or had read. They can only start reading books in Boxes C and D. This means the system are not fully fault-tolerant. To resolve this, we can make our system more robust by taking a copy of Box A and B and duplicating it Building 2. Let’s call these new boxes Ax and Bx. With this change, if Building 1 is down, the two people can go to Building 2 and continue reading from boxes Ax and Bx. This is called replication.
Replication essentially takes a copy of the partitions and copies them over to other brokers for improved availability. When a topic is created, the replication factor can be defined, which is a number indicating how many copies of each partition we want on the brokers. The default replication factor is 1 meaning there is no replication, so only one copy of each partition for that topic will ever be created. The replication factor cannot be greater than the number of brokers because there needs to be a corresponding broker for each replica. One of these copies is assigned as the leader, and the rest are followers. When the producer writes to a partition, Kafka writes to the broker designated as the leader of that partition and then propagates this data to the followers. In the same manner, when consumers read from the partition, they only read from the leader node. If the leader broker fails for any reason, Kafka promotes one of the followers to be a new leader.
Acks (or acknowledgments) is a way for the broker to inform the producer that it has received a message. Depending on the producer acks configuration, replication can considerably increase latency. For example, if the acks setting is set to 'all', now the producer needs to wait for all the follower brokers to acknowledge receiving the message before marking the request as complete. That said, irrespective of the acks setting, consumers cannot see a message until it has been fully propagated to all the follower nodes.
In the image below, we have 3 brokers in the cluster. Topic A has 2 partitions, so each partition lives in a different broker e.g Partition 0 an 1 for Topic A are placed in Brokers 1 and 2 respectively
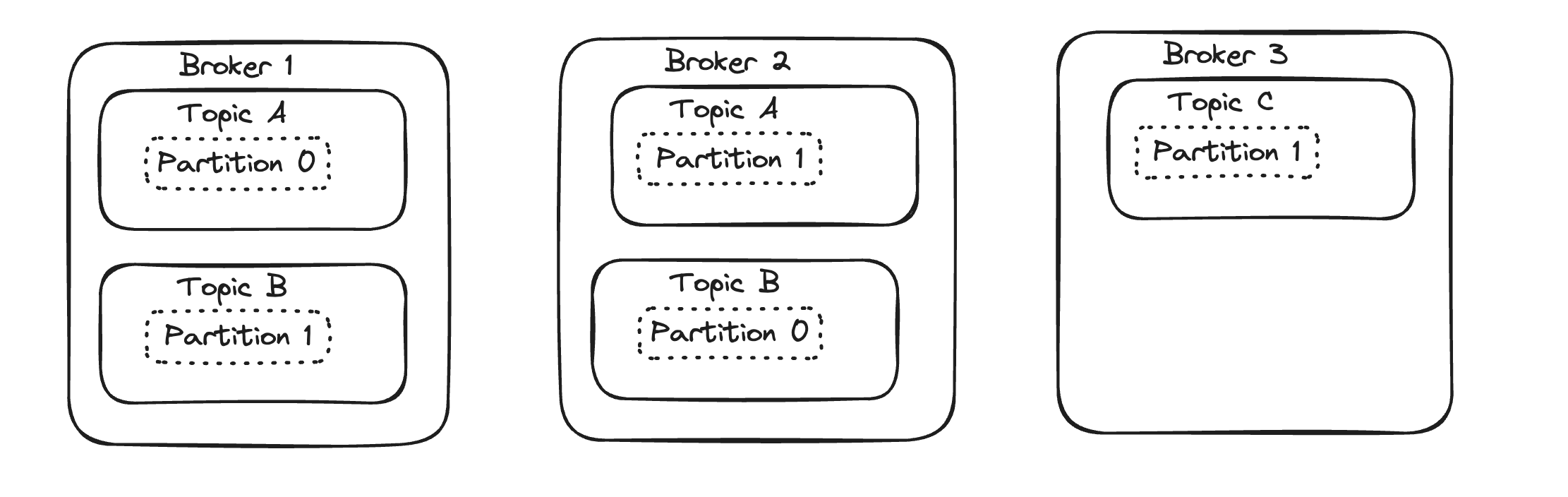
In this next image, we introduce replication. With two partitions and a replication factor of 2, both partitions for Topic A are now copied into both Brokers 1 and 2. Because we have fewer partitions than brokers, some brokers would not have partitons for this topic
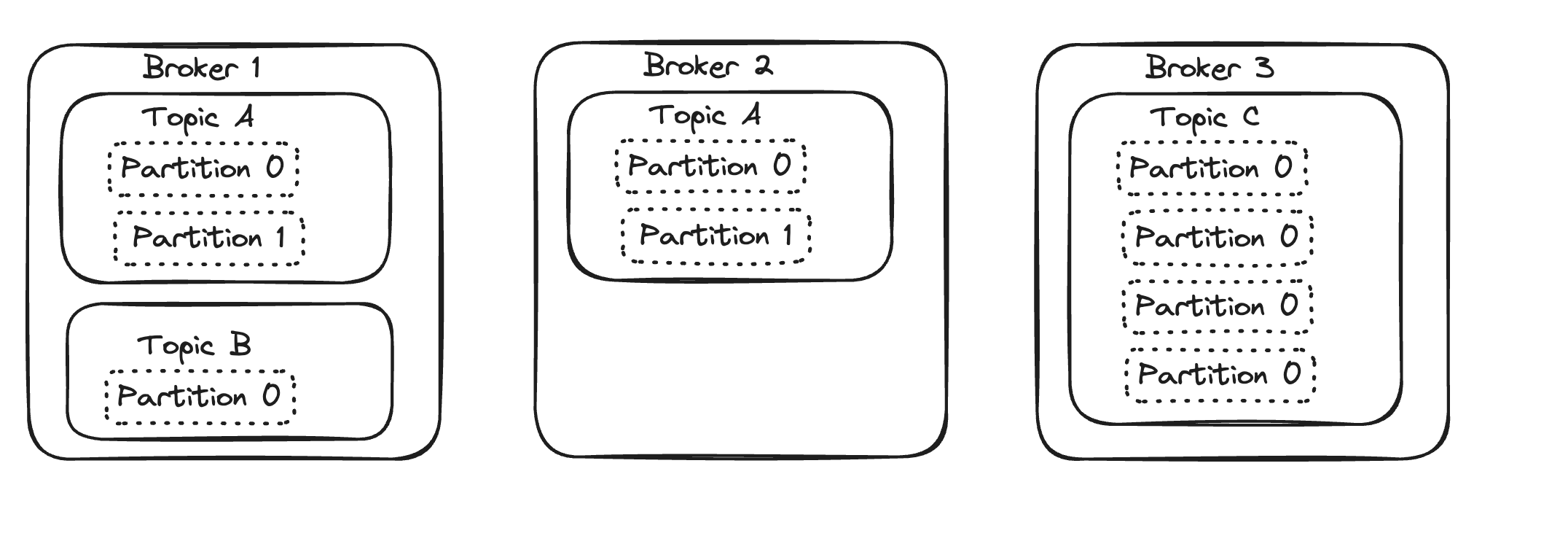
What if we have 3 partitions and we also want to a replication factor of 2? In the image below, observe that all three partitions are copied to the brokers. Partition 0 is replicated on Broker 1 and Broker 3, and the other partitions are similarly replicated. For brevity, other topics are not shown
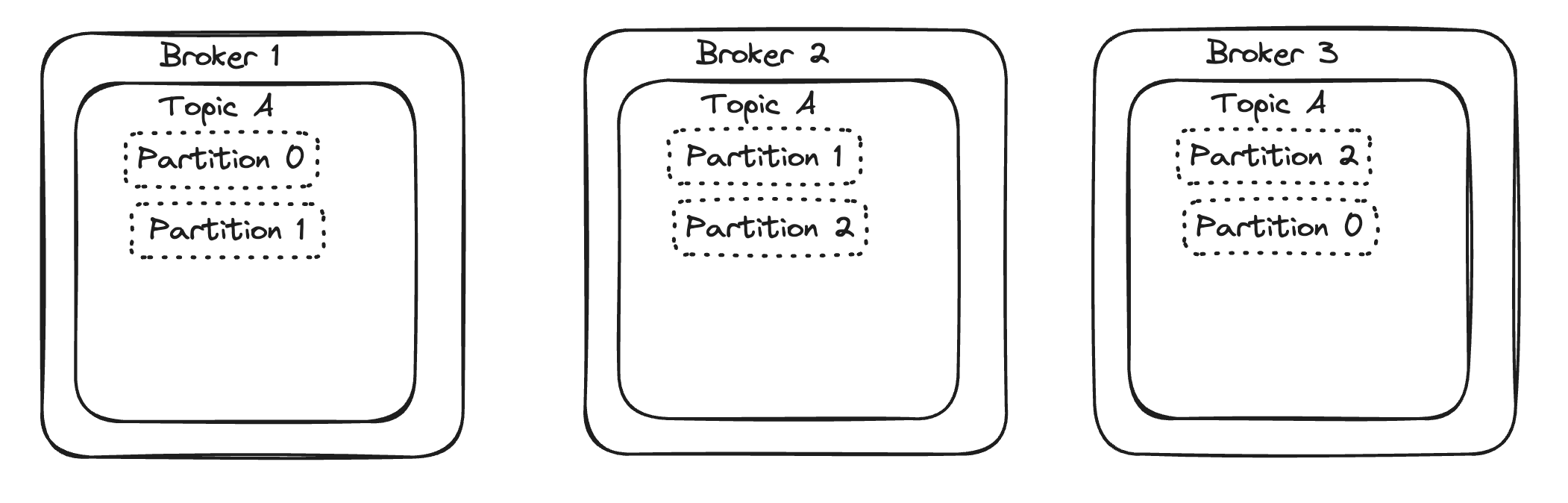
It is also possible to have a lot more partitions than brokers, as shown in the next image. In this case, we have 4 partitions and a replication factor of 3 (not possible to have more replicas than brokers). Notice how a copy of each partition is placed in every broker.
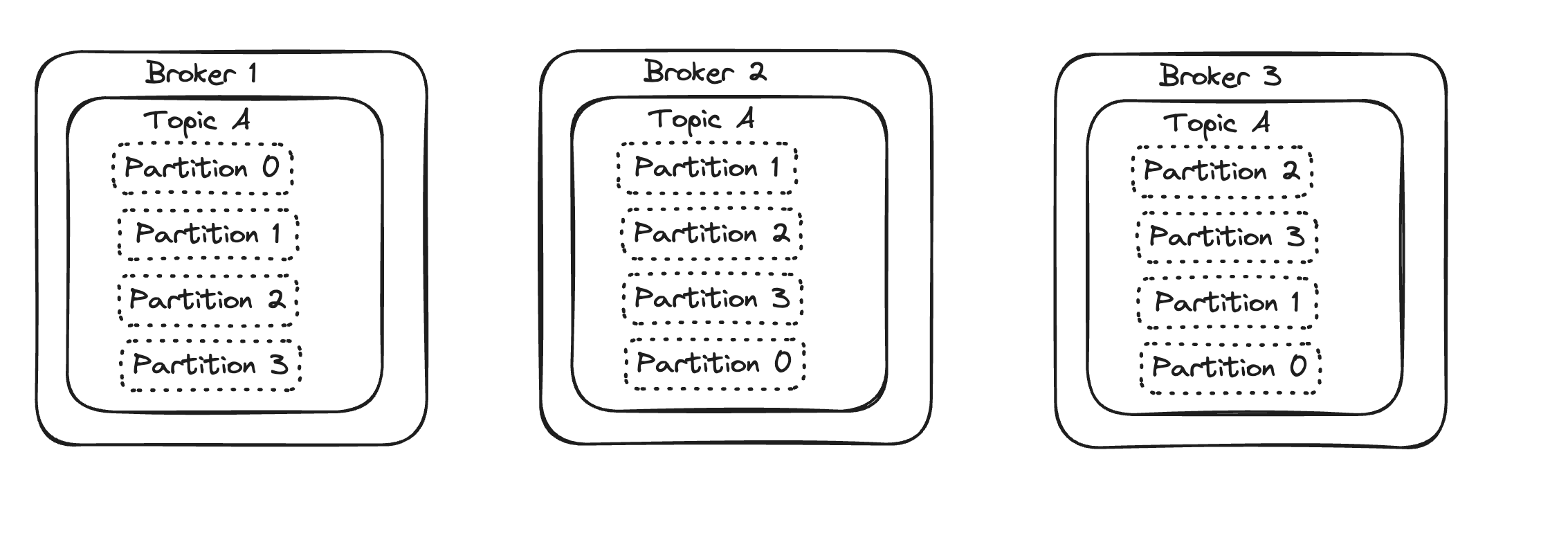
Armed with this knowledge, it is crucial to visualize messages at the partition level - meaning producing, consuming and offsets are all for a partition and not the entire topic. This means changing the number of partitions or replicas on an existing topic can become tricky since existing consumers would be depending on the partitions. The best way to resolve this is to use a streaming transformation to automatically stream all the messages from the original topic into a new Kafka topic which has the desired number of partitions or replicas as explained here.
With the introduction of partitions, how would the consumers subscribe to a particular partition? Would the consumers need to keep track of the partition number before reading? Kafka solves this with the concept of a consumer group.
Consumer Group
The previous sections described a simplistic approach to message consumption at the topic level without considering partitions. Now, with our data partitioned, we can fully leverage parallelization by deploying multiple consumers that read from specific partitions. These consumers are organized into a Kafka abstraction known as a Consumer Group. To group consumers, specify a group ID when creating the consumer, as shown below:
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'topic1',
group_id='my-group-id',
bootstrap_servers='your_kafka_bootstrap_servers'
...
)
Kafka ensures that only a single consumer within a consumer group can read from a partition within a topic, preventing duplication of data for a given partition. This avoids potential race conditions in parallel processing, where multiple consumers within the same group might work on messages from different partitions simultaneously.
If the number of consumers exceeds the number of partitions, surplus consumers remain idle until one of the consumers dies. Conversely, suppose we have a topic with 8 partitions and initially start 3 consumers in the same consumer group. During a rebalance, Kafka may assign each consumer to 2 partitions, leaving 2 partitions unassigned. If a fourth consumer is later added, Kafka will rebalance and assign each consumer to 2 partitions, achieving a balanced assignment. This opens up some interesting ideas:
Placing all consumers in a single group transforms Kafka into a queue, as a partition can only be read by one consumer in the group. On the other hand, placing each consumer in its own group makes Kafka act as a Pub/Sub system, allowing each group to access the same message.
Kafka designates one of the brokers as the group coordinator, responsible for decisions on partition assignment when new consumers join and reassignment when a consumer leaves. The coordinator, informed by periodic heartbeat requests from consumers, manages the dynamic state of the consumer group.
References
https://www.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch04.html
https://medium.com/@rramiz.rraza/kafka-programming-different-ways-to-commit-offsets-7bcd179b225a
https://blog.developer.adobe.com/exploring-kafka-producers-internals-37411b647d0f
https://www.techpoolx.com/blog/the-side-effect-of-fetching-kafka-topic-metadata.html
https://www.conduktor.io/kafka/kafka-topic-replication/#Kafka-Topic-Replication-Factor-0
https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client
Subscribe to my newsletter
Read articles from Ladna Meke directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ladna Meke
Ladna Meke
Fullstack developer with the occasional dabble in DevOps