Amazon S3 - A Storage Service
 Vyankateshwar Taikar
Vyankateshwar Taikar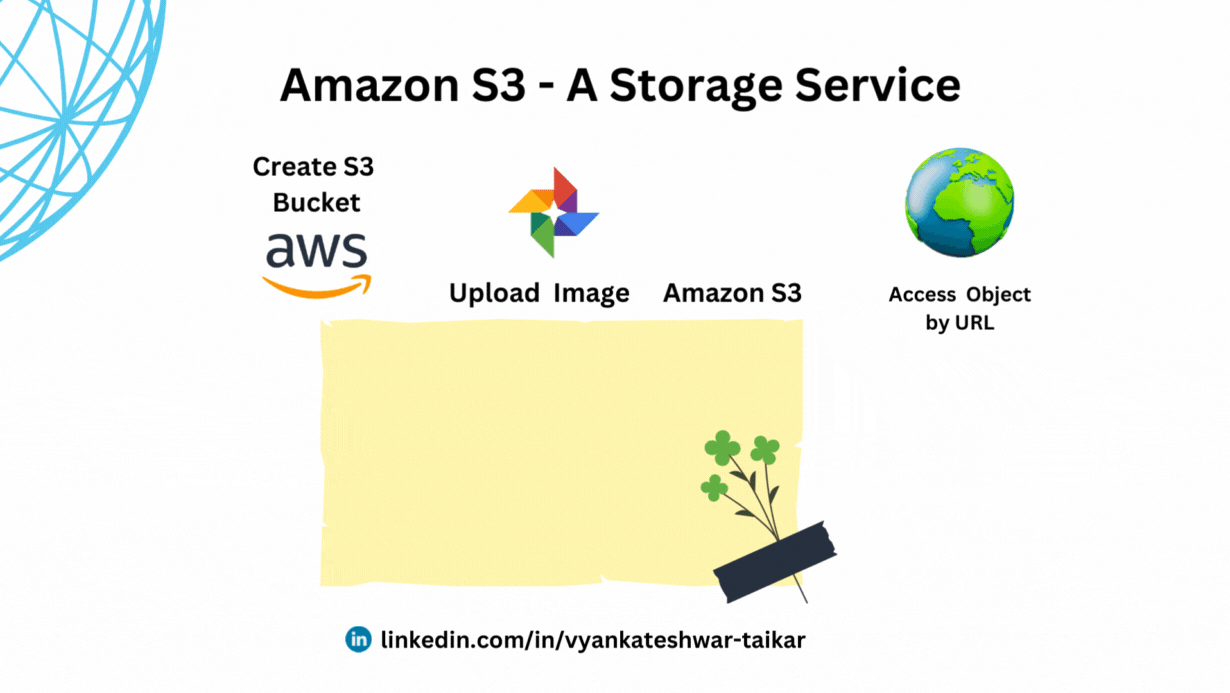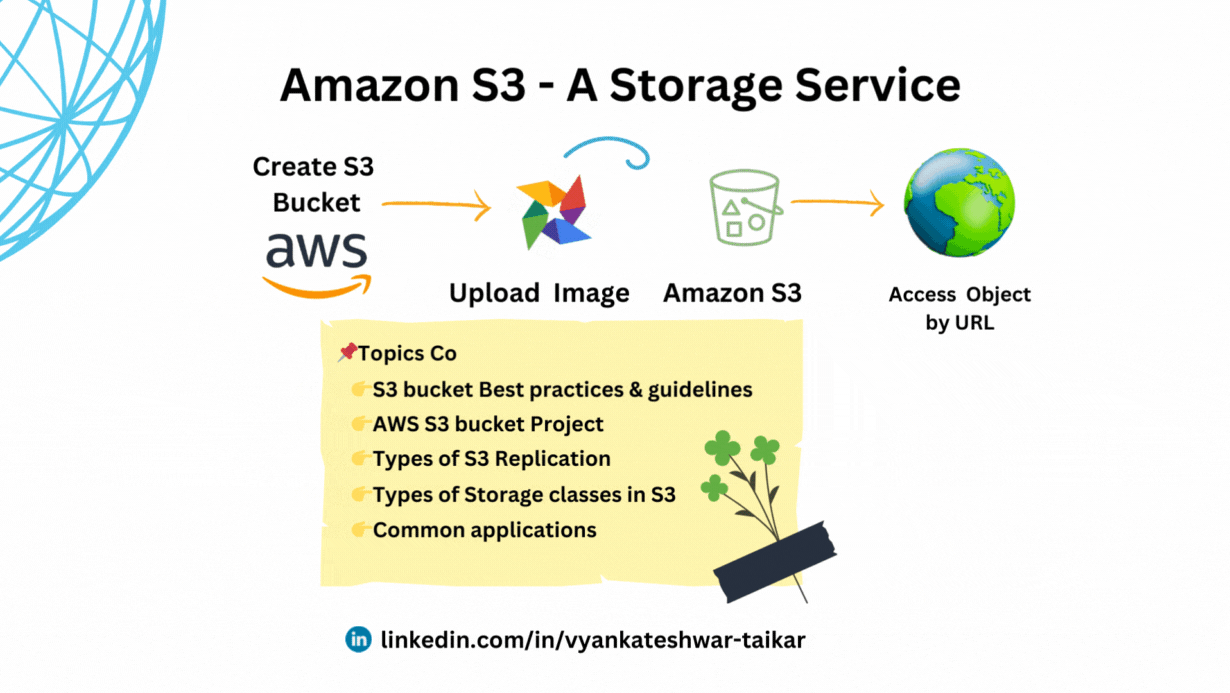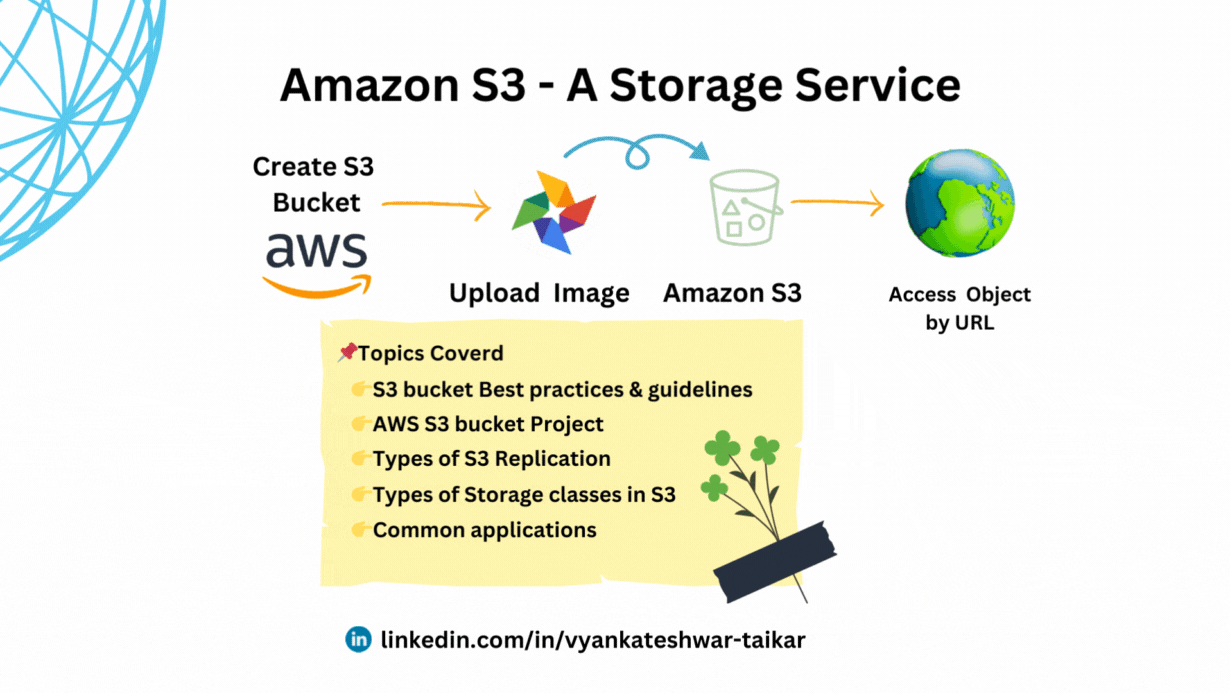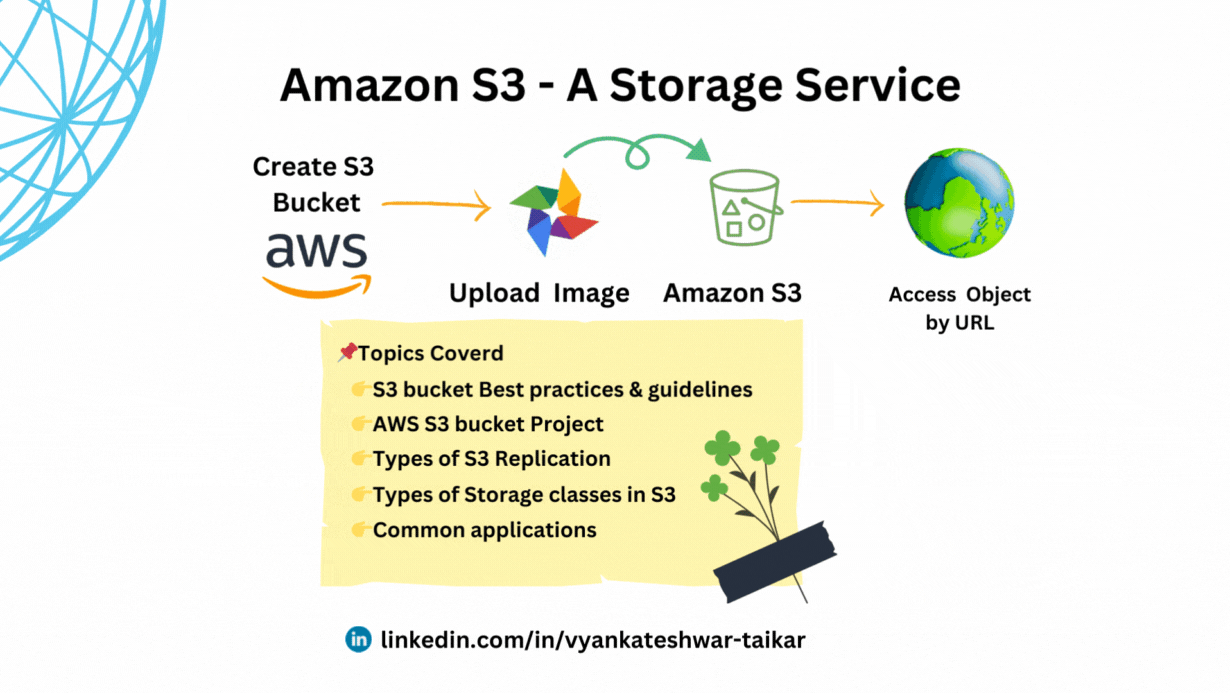
💠What Is Storage ?
The availability of computing resources for the storage and retrieval of data is referred to as storage in the context of AWS (Amazon Web Services).
AWS provides a range of storage services to meet different requirements and use cases. In terms of AWS, the following is a fundamental description of storage:
💠Storage Types Available In AWS:
S3: Simple Storage Service is object storage that we use and is charged for by AWS. It is a cloud storage solution.
EBS: Elastic Block store provided with the instance, only the attached instance can use this storage just like C or D drive in our system, it is block storage means for deploying software.
Elastic File System : you may share file data without having to worry about managing or providing storage.
Scalable file storage that is also EC2 optimized is provided by Amazon EFS. It can be utilized as a shared datasource for any workload or program that executes several times. You can set up instances to mount the file system using an EFS file system.
Glacier: Glacier is another low-cost, long-term data archiving solution offered by Amazon S3.
Storage Gateway: It stores data locally as well as on the premises in S3.
More For storage you can read it out here👉 Explore Amazon Storage

For now, We will discuss only Amazon S3 in this blog .
💠What is Amazon S3 ?
You can store and retrieve any volume of data from any location on the web with Amazon S3, which is an object storage solution that is user-friendly and has a simplified web service interface. You can also pay for the storage that you use with Amazon S3.
S3 is a Global service provided by amazon.

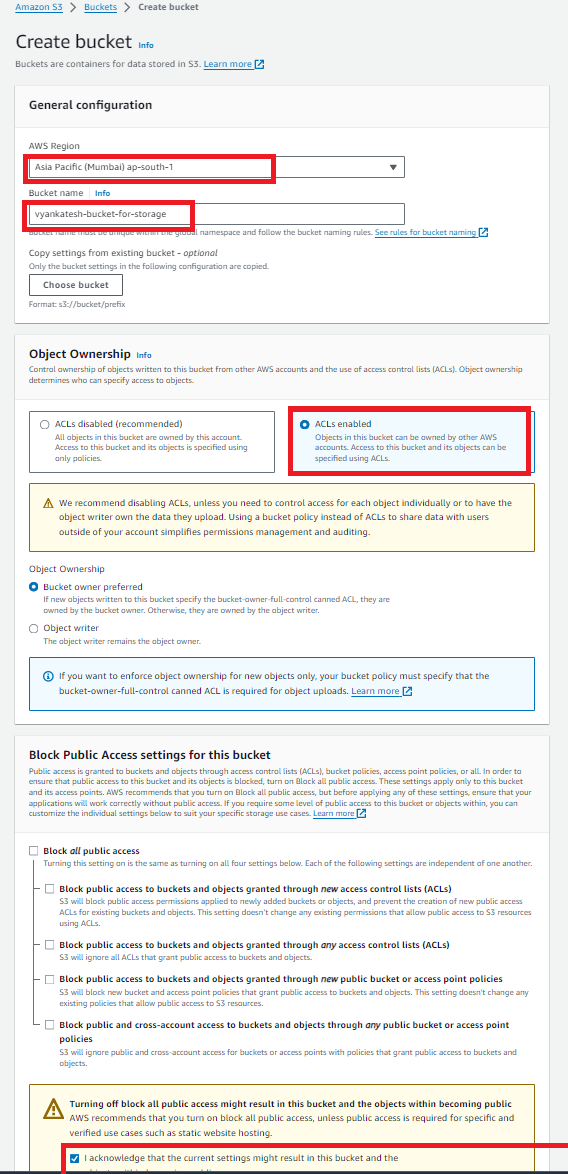
💠S3 bucket naming practices & guidelines.
These are the guidelines for naming:
Bucket names have to be three to sixty-three characters long.
Only lowercase letters, numbers, dots, and hyphens are permitted in bucket names. Therefore, underscores and capital letters cannot be used in bucket names.
They have to have a letter or number at the start and end. IP addresses cannot be used as bucket names.
They cannot have the prefix xn at the beginning or the suffix -s3alias at the end.
Also, a bucket name needs to be globally unique, as we've already seen.
💠Creating a new S3 bucket in AWS
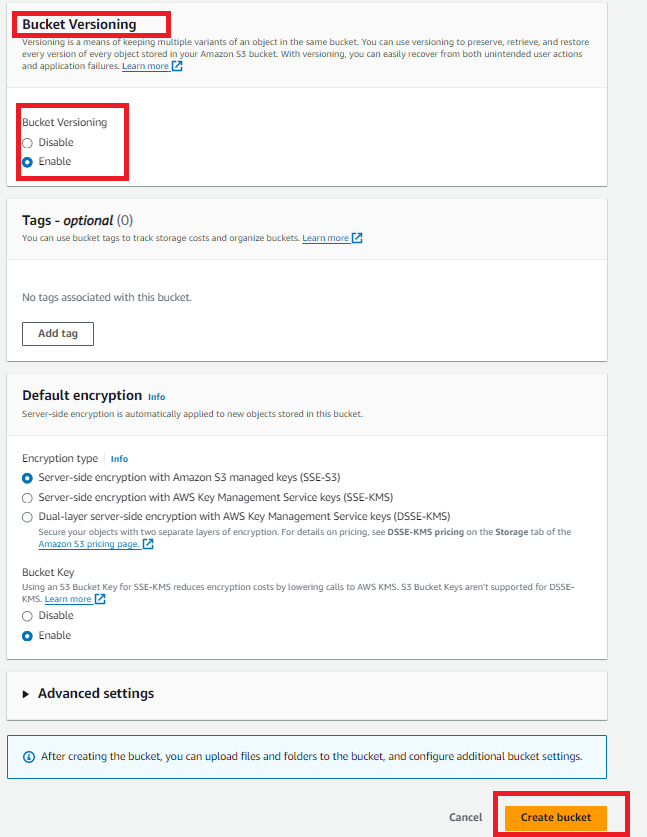
Enable versioning: To maintain several versions of the same file, enable versioning. If a log request for bucket access is required, mark it and include the tag in order to track costs in invoicing.
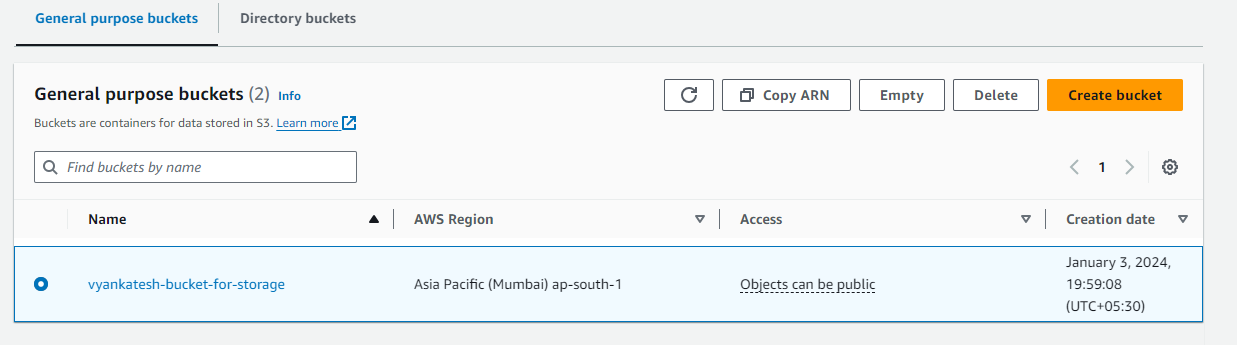
Upload data to the same bucket that was created, uniquely named vyankatesh-bucket-for-storage in the Asia Pacific (Mumbai) ap-south-1.
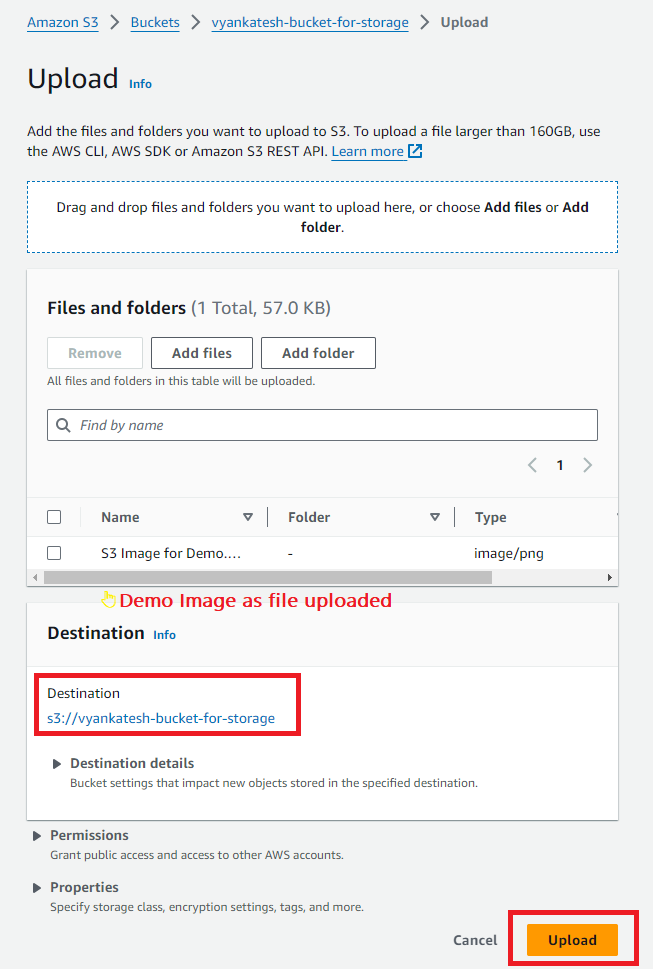
As we uploaded data , now we can check it .
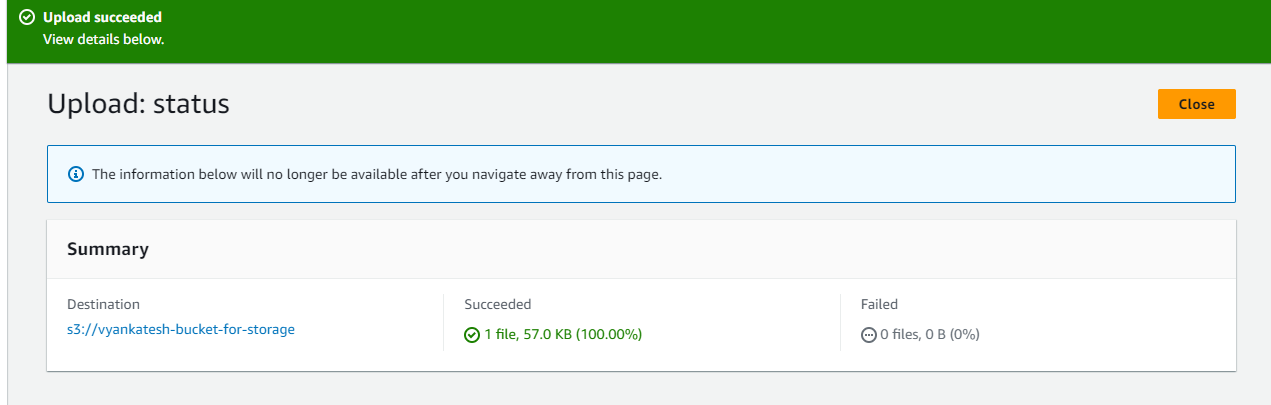
Make it public using ACL
Before Check with URL, Copy the object URL it and open in new window.
paste it url , and access the Object . nothing but image that i uploaded in the S3
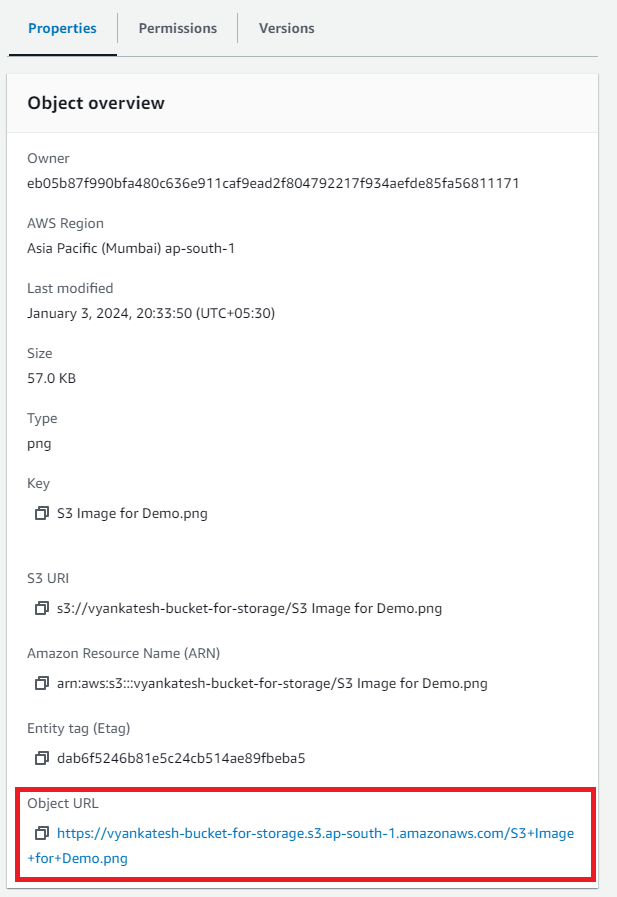
Here, we can look at object related to the uploaded file, such as the owner, the latest changed date, the Etag that is specific to each item in the bucket, and the storage class, which by default chooses the primary and standard URL for file access or download.
💠S3 Replication
The practice of copying data from Amazon Simple Storage Service (S3) buckets across many regions is known as S3 replication. This contributes to improving the resilience, availability, and durability of data.
Two Types of S3 Replication
- Cross-Region Replication (CRR):
Source and Destination Buckets: Replication between source and destination S3 buckets located in several AWS regions is involved in source and destination buckets.
Data Transfer: Asynchronous copies of the objects in the source bucket are made to the destination bucket, which is located in a different region.
Use Cases: Reducing latency for users who are dispersed geographically, disaster recovery, and compliance needs.
- Same-Region Replication (SRR):
Source and Destination Buckets: Replication happens between source and destination buckets inside the same AWS region.
Data Transfer: Redundancy and fault tolerance are provided via the asynchronous replication of objects within the same region.
Use Cases: Use cases include compliance within a given region, fault tolerance, and high availability.
💠Types of Storage class Available in S3
An S3 storage class is a technique to group S3 into several categories of data storage according to needs for availability, durability, and frequency of use. Based on the data's usage patterns, Amazon S3 provides a variety of storage classes to assist users maximize both speed and cost. S3 Standard Infrequent Access (IA), S3 Standard, S3 Intelligent Tiering, S3 One Zone-Infrequent Access, S3 Glacier Instant Retrieval, S3 Glacier Deep Archive & S3 Glacier Flexible Retrieval . We are going to explore each of these storage classes in more detail and examine specific use cases related to each one.
1)S3 Standard : - This S3 default storage type is created for data that is accessed frequently. It provides excellent performance, availability, and durability.
It is intended for usage in situations where frequent and speedy access to data is required, together with low latency and high throughput.
Data in this storage class is spread across several locations and devices inside an AWS Region. This offers high availability, which means data is always accessible, and high durability, which means data is safeguarded against hardware failure.
Strong read-after-write consistency for new objects is another feature of the S3 Standard that enables instantaneous reading of newly created objects. Typical applications for S3 Standard include general-purpose storage
2)S3 Standard Infrequent Access (IA) : For data that is accessed infrequently but yet needs low-latency access when needed, it is an affordable storage solution.
It provides the low latency, high throughput, and great durability of S3 Standard at a reasonable cost per GB of storage and retrieval. The amount of data that must be retrieved and the time required to do so determine the retrieval fees.
For storing long-term backups, disaster recovery files, or data that must be kept for reasons of compliance, the S3 Standard-IA storage class offers an excellent mix between performance and cost.
It is also appropriate for storing data that needs to be accessible quickly when needed but is not accessed frequently.
3)S3 One Zone-Infrequent Access: One Zone-IA stores data in just one Availability Zone (AZ), as opposed to other storage classes that store data in at least three AZs.
It is intended for readily re-created data in the event of a loss. One Zone-IA stores data in a single AZ inside a region, making it a less expensive alternative when compared to other S3 storage classes.
For data that is rarely accessed but yet needs low-latency access when needed, S3 One Zone-IA is the best option.
At a lesser cost, it provides the same low latency access as the S3 Standard-IA storage class.
It is meant for use scenarios where data can be readily replicated, like disaster recovery, backups, and rarely accessed non-business-critical data.
4)S3 Intelligent-Tiering : It is a storage class that, in response to shifting access or usage patterns, intelligently moves items between different access tiers in order to optimize your storage costs.
By automatically shifting items between three access tiers the frequent access tier (default tier), the rarely access tier, and the archive rapid access tier.
it is intended to optimize costs for data with uncertain or fluctuating access patterns.
Objects are added to the frequent access tier when they are uploaded to this storage class.
S3 Intelligent-Tiering tracks your objects' access behaviors over time and intelligently transfers them between access tiers according on how they are used.
It is significant to remember that this storage type has no retrieval fees.
5)S3 Glacier Instant Retrieval : When data needs to be retrieved in milliseconds but is rarely used, it is stored in this type of storage.
When comparing data stored in the storage class to the S3 Standard-IA with the same latency and throughput characteristics, savings can reach up to 68%. You are responsible for paying for any data transfers in addition to storage and retrieval fees while utilizing S3 Glacier Instant Retrieval.
The size of the archive and the manner of retrieval you choose will determine how much it costs to recover data. Bulk, standard, and accelerated retrieval modes are provided.
Data access is possible in 1–5 minutes with expedited retrieval and 3–5 hours with conventional retrieval.
The most affordable choice is bulk retrieval, which gives users access to data in 5 to 12 hours. Applications that need low-latency access to data archives can benefit from using it as a storage solution.
6)S3 Glacier Flexible Retrieval : It provides inexpensive storage for material that has been archived and is viewed 1-2 times year.
This storage class provides the three retrieval options, just like S3 Glacier Instant Retrieval.
Additionally, partial retrievals are possible via Flexible Retrieval, allowing users to access only a subset of their preserved data rather than the complete archive.
This can save money and time, particularly if there is a lot of data being archived.
S3 Glacier Flexible Retrieval is the best option for offshore data storage, disaster recovery, and backup storage.
7)S3 Glacier Deep Archive: This is the S3 storage class with the lowest pricing.
It facilitates digital preservation of data that may be retrieved once or twice a year as well as long-term retention (often spanning many years to decades).
Since this storage type takes 12 hours to retrieve data, it should only be used for data that is unlikely to be needed very soon.
It is intended for users who must save a lot of data for long periods of time due to legal or commercial obligations.
💠Common applications for Amazon S3 storage comprise (Use Cases)
Data archiving and backup for on-site or cloud data
Distribution and storage of software, media, and content
Analytics for big data
Hosting of static websites hosting of cloud-native mobile and web applications
Recovery from disasters
Today, Some of the essential elements of Amazon S3 have been studied. I think the information in this post will be sufficient to get you started with the service and to let you choose an S3 storage choice based on cost, performance, or use case in an informed manner. Continue exploring this service to take advantage of all that it has to offer. Make sure to use the comments area to ask any questions you may have.
I hope you enjoy the blog post!
✔Find out more blogs 👉 Here
✔Connect with me on 👉 Linkedin
If you do, please show your support by giving it a like ❤, leaving a comment 💬, and spreading the word 📢 to your friends and colleagues 😊.
Subscribe to my newsletter
Read articles from Vyankateshwar Taikar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vyankateshwar Taikar
Vyankateshwar Taikar
Hi i am Vyankateshwar , I have a strong history of spearheading transformative projects that have a direct impact on an organization's bottom line as a DevOps Engineer with AWS DevOps tools implementations.