Building an LRU (Least Recently Used) Cache in GO
 Mide Dickson
Mide Dickson
Hey there! I am sure you are ready to hop in and get your hands dirty with this interesting topic.
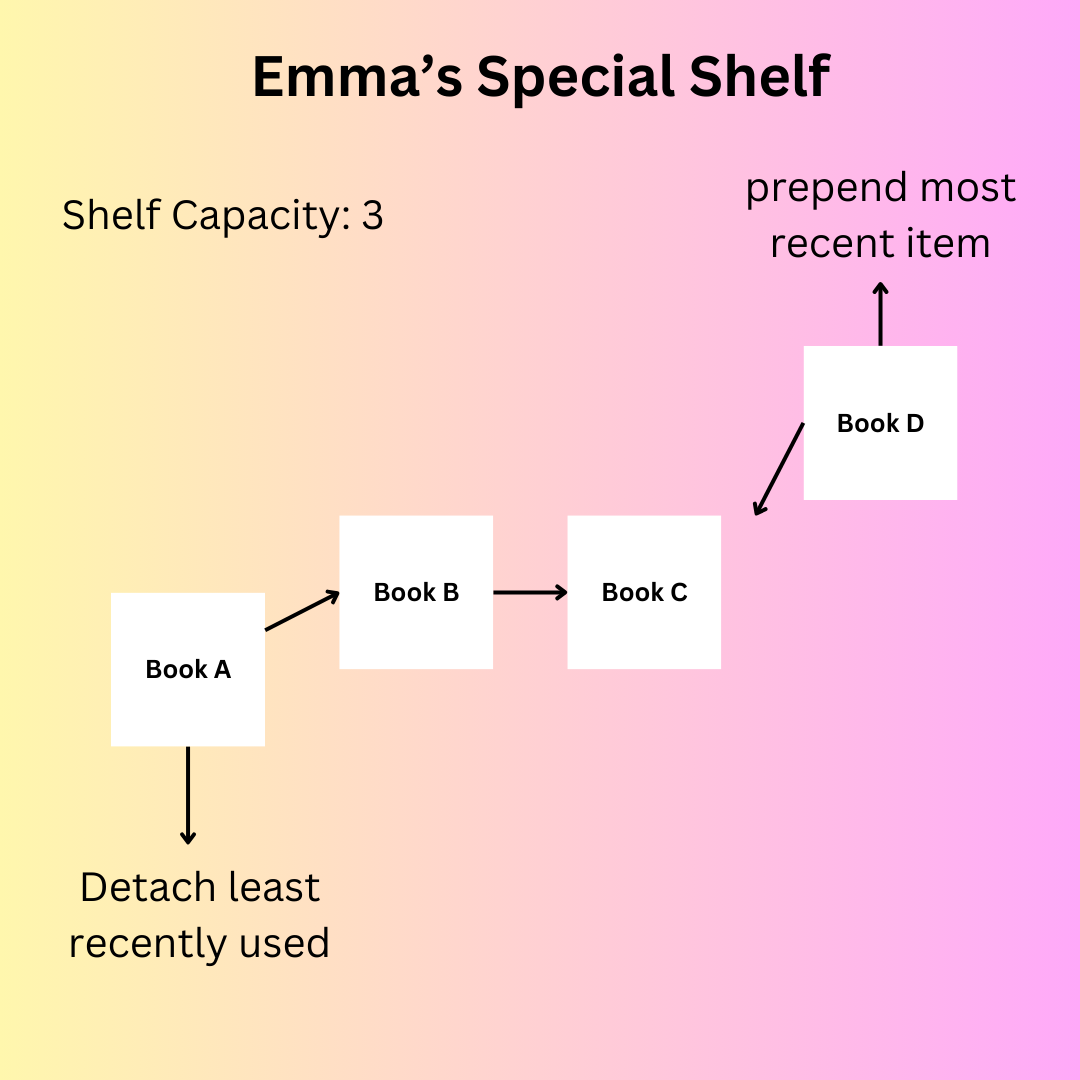
But before we go into all that hard work, let me tell you about my very good friend, Emma.
Emma works in a library, so every time I go there to get a book, she keeps a special shelf for me to ensure quick and efficient retrieval of my most frequently requested books. However, managing this special bookshelf comes with its challenges.
The library has a vast collection of books, and finding the right one can be time-consuming. Without Emma's special bookshelf, I would have to sift through the entire library every time I wanted a book, which would be impractical and slow. That's where Emma's thoughtful approach to organizing my most-used books on a dedicated shelf comes into play.
But here's the catch: the special bookshelf has limited space. It can only accommodate a certain number of books at a time. So, Emma needs to strategically select which books to keep on this shelf to ensure that the most relevant ones are readily available to me.
She came up with an idea to keep track of the books I use most frequently so that they remain on the shelf, while occasionally swapping out the least recently used books to make room for new additions.
Now, every time I request a book, Emma checks if it's already on the special bookshelf. If it is, she moves it to the front, signifying that it's the most recently used. However, if the requested book is not on the shelf, Emma identifies the least recently used book and replaces it with the new one.
In this way, Emma ensures that the special bookshelf always contains the books I need the most, making finding and retrieving them quick and efficient.
Emma's special bookshelf for me is a situation where the concept of a Least Recently Used (LRU) cache comes in handy! The LRU cache strategy is like having a curated selection of books at my fingertips, thanks to Emma's thoughtful management of the limited space on the special shelf. It's a clever solution to the challenges of collecting and searching for books in a vast library.
You can keep Emma's special bookshelf in mind as we implement the LRU Cache:
Now, let's get started properly! 🔥
What is a Least Recently Used (LRU) Cache?
Just as it is in the library, optimizing data storage and retrieval is a continual challenge in software engineering. Many tools are available to achieve this and the Least Recently Used (LRU) cache stands out as a pragmatic solution for efficient memory management.
This guide delves into the technical intricacies of constructing an LRU cache using the Go programming language. We'll break down the main ideas behind the LRU cache, look into how it's built, and explain how it works when there's not much memory available.
Understanding the Basics
Before delving into the implementation details, it's crucial to grasp the fundamental concepts behind an LRU (Least Recently Used) cache. An LRU cache is designed to efficiently manage a limited amount of data by retaining the most recently accessed items while evicting the least recently used ones when capacity is reached.
Key Principles:
Recent Usage Matters:
LRU caches prioritize recent access over historical usage.
Items that haven't been accessed recently are candidates for eviction.
Fixed Capacity:
The cache has a predetermined capacity, limiting the number of items it can store.
Eviction occurs when the capacity is exceeded.
Quick Lookups:
Efficient lookup mechanisms are essential for quick access to cached items.
Data structures like maps are often employed for rapid key-based retrieval.
Optimizing for Common Scenarios:
LRU caches are effective in scenarios where certain items are accessed more frequently than others.
They strike a balance between computational efficiency and storage utilization.
In the next sections, we'll delve into the data structure design and the initial steps of our LRU cache implementation.
Data Structure Design
With a conceptual understanding of an LRU cache, let's transition to the foundational aspect: designing the necessary data structures to bring our cache to life.
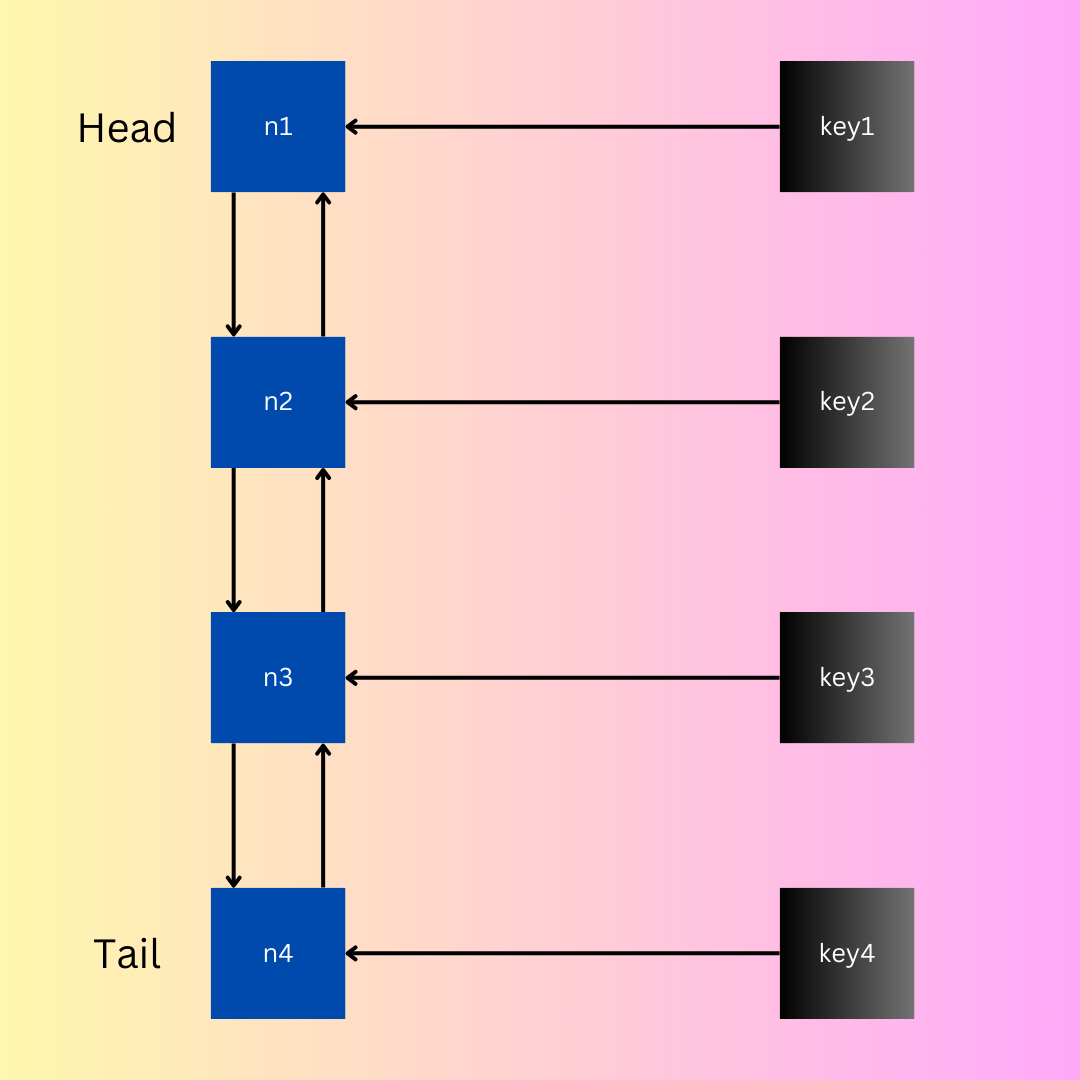
The LRU data structure design will use a combination of two popular data structures:
Doubly Linked List
HashMaps
The implementation of an LRU (Least Recently Used) cache with a doubly linked list and hashmaps serves specific purposes, combining the advantages of both data structures to achieve efficient and quick operations.
Doubly Linked List:
Ordering Elements: The doubly linked list helps maintain the order of elements based on their usage. The most recently used item is positioned at the front (head) of the list, while the least recently used item is at the back (tail).
Constant Time Removal and Insertion: Removing and inserting elements in a doubly linked list can be done in constant time once you have a reference to the node. This makes it efficient to adjust the order of elements as they are accessed.
Hashmaps:
Fast Lookups: Hashmaps provide fast and constant-time lookups based on a key. In the context of an LRU cache, keys are associated with nodes in the doubly linked list.
Efficient Retrieval: When you need to find or update a specific item in the cache, a hashmap allows you to directly locate the corresponding node in the linked list, providing quick access.
Combined Benefits:
Optimal Removal and Insertion: Combining a doubly linked list with a hashmap enables optimal removal and insertion of elements. The hashmap facilitates quick identification of the node to be removed or updated, while the doubly linked list allows for efficient reordering of elements based on their usage.
Constant Time Operations: The LRU cache operations, such as adding, removing, or updating items, often involve both the hashmap and the linked list. Using these two structures together allows for constant-time operations in many scenarios, providing efficiency in managing the cache.
Data Structure Implementation
Let's implement the Super LRU data structure as we designed in the section above. It's also noteworthy to mention that Go's flexibility and support for generics enhance the adaptability of our implementation. Generics allow our LRU cache to be used with a wide range of data types, offering a versatile solution for various scenarios.
1. Node Structure Implementation:
Define a
Nodestructure to represent each item in the cache.Include fields for the value, a pointer to the next node, and a pointer to the previous node.
type Node[V comparable] struct {
Value interface{}
Next *Node[V]
Prev *Node[V]
}
func newNode[V comparable](value V) *Node[V] {
node := &Node[V]{Value: value}
return node
}
The newNode[V comparable](value V) *Node[V] function initializes a new Node with the specified value.
2. LRUCache Initialization:
Create a function for initializing the LRU cache with a specified capacity.
Set up the head and tail pointers, and initialize the maps for quick lookups.
type LRUCache[K, V comparable] struct {
length int
capacity int
head *Node[V]
tail *Node[V]
lookup map[K]*Node[V]
reverseLookup map[*Node[V]]K
}
func newLRUCache[K, V comparable](capacity int) *LRUCache[K, V] {
lruCache := &LRUCache[K, V]{}
lruCache.Init(capacity)
return lruCache
}
func (r *LRUCache[K, V]) Init(capacity int) {
r.length = 0
r.capacity = capacity
r.head = nil
r.tail = nil
r.lookup = make(map[K]*Node[V])
r.reverseLookup = make(map[*Node[V]]K)
}
The newLRUCache[K, V comparable](capacity int) *LRUCache[K, V] function initializes a new LRUCache with the specified capacity using the Init(capacity int) method.
Cache Management Functions and Methods
Let's shrink the functions and methods that constitute the core of our LRU cache implementation. Each function plays a crucial role in managing the cache, from initialization to updating and retrieving values.
func (r *LRUCache[K, V]) Update(key K, value V) {
// Updates the cache with a new key-value pair.
// Handles cases of updating an existing entry or inserting a new one.
}
func (r *LRUCache[K, V]) Get(key K) (value V) {
// Retrieves a value from the cache based on the given key.
// Updates the position of the corresponding node.
}
func (r *LRUCache[K, V]) trimCache() {
// Trims the cache size to fit the specified capacity.
// Removes the least recently used items when the cache exceeds its capacity.
}
func (r *LRUCache[K, V]) detach(node *Node[V]) {
// Detaches a node from the linked list.
}
func (r *LRUCache[K, V]) prepend(node *Node[V]) {
// Prepends a node to the front of the linked list.
}
Understanding these functions and methods provides a solid foundation for comprehending the inner workings of our LRU cache implementation. As we progress, we will witness how these components seamlessly interact to deliver efficient and flexible caching capabilities in Go.
Update Function
Now that we've laid the groundwork with our data structures, let's delve into the implementation of the Update function. This crucial function ensures that our LRU cache is up-to-date, handling both the insertion of new items and the update of existing ones.
1. Update Function:
Implement a function to update the cache with a new key-value pair.
Check if the key exists, and handle the cases of updating an existing entry and inserting a new one.
func (r *LRUCache[K, V]) Update(key K, value V) {
// Check if the key already exists
node, ok := r.lookup[key]
if !ok {
// If not found, create a new node
node = newNode(value)
r.prepend(node)
r.length++
r.trimCache()
r.lookup[key] = node
r.reverseLookup[node] = key
} else {
// If the key exists, move the node to the front and update the value
r.detach(node)
r.prepend(node)
node.Value = value
}
}
In this function, we handle the scenarios where the key is found or not found in the cache.
If the key doesn't exist, we create a new node, prepend it to the front, update the cache size, and update the lookup and reverseLookup maps. If the key exists, we detach the node, move it to the front, and update its value.
The trimCache function is called to ensure that the cache remains within its specified capacity.
Get Function
Moving forward, let's implement the Get function, this function allows us to retrieve a value from the LRU cache based on a given key. It plays a crucial role in efficiently accessing cached data and maintaining the order of recently used items.
2. Get Function:
Develop a function to retrieve a value from the cache based on a given key.
Check if the key exists in the cache, and update the position of the corresponding node.
func (r *LRUCache[K, V]) Get(key K) (value V) {
// check the cache for existence
node, ok := r.lookup[key]
if !ok {
// if not found, return zero-value of V
return
}
// update the value we found and move it to the front
r.detach(node)
r.prepend(node)
value = node.Value
return
}
In this function, we first check if the key exists in the cache. If it does, we retrieve the corresponding node, detach it from its current position, prepend it to the front of the list, and return the associated value. If the key is not found, we return nil.
The detach and prepend functions are crucial here, as they ensure that the accessed node is appropriately moved to the front of the linked list, reflecting its recent usage.
As our LRU cache functionality expands, the next step involves handling the scenario where the cache size exceeds its specified capacity.
Trimming the Cache
Now, let's focus on the function responsible for maintaining the cache size within the specified capacity—trimCache. This function ensures that our LRU cache remains efficient by removing the least recently used items when the number of elements surpasses the defined limit.
Cache Size Management Function:trimCache
Method:
func (r *LRUCache[K, V]) trimCache() { // Trim cache to fit capacity if r.length <= r.capacity { return } tail := r.tail r.detach(tail) key := r.reverseLookup[tail] delete(r.lookup, key) delete(r.reverseLookup, tail) r.length-- }Explanation:
The function begins by checking if the current length of the cache (
r.length) is less than or equal to the specified capacity (r.capacity). If this condition is met, it indicates that the cache is within its capacity, and no trimming is required, so the function returns.If the cache has exceeded its capacity, the function proceeds to trim it. It does so by retrieving the least recently used node, which corresponds to the tail of the linked list (
tail := r.tail).The
detachmethod is then called to remove the tail node from the linked list. This process involves updating pointers in the previous and next nodes, effectively detaching the node from the list.The key associated with the tail node is obtained from the
reverseLookupmap (key := r.reverseLookup[tail]). This key is used to remove the entry from both thelookupandreverseLookupmaps, ensuring consistency after the node is detached.The
deletestatements remove the key-node association from the maps, preventing any residual references to the removed node.Finally, the length of the cache is decremented (
r.length--) to reflect the removal of the least recently used item.
This function ensures that our LRU cache dynamically adjusts to the defined capacity, preventing unnecessary memory usage and maintaining optimal performance.
Node Management Functions: detach and prepend
Before we progress further, let's explore the intricacies of the node management functions—detach and prepend. These functions play a pivotal role in maintaining the order of nodes within the doubly-linked list, ensuring that the most recently used items are positioned at the front.
Node Management Function: detach
Method:
func (r *LRUCache[K, V]) detach(node *Node[V]) { // Detach a node from the linked list if node.Prev != nil { node.Prev.Next = node.Next } if node.Next != nil { node.Next.Prev = node.Prev } if node == r.head { r.head = r.head.Next } if node == r.tail { r.tail = r.tail.Prev } node.Prev = nil node.Next = nil }Explanation:
detachis responsible for removing a given node from the doubly-linked list. It checks if the node has a previous (node.Prev) or next (node.Next) node and adjusts their pointers accordingly to skip the node being detached.If the node is the head of the list (
node == r.head), the head pointer is updated to the next node.If the node is the tail of the list (
node == r.tail), the tail pointer is updated to the previous node.The function then nullifies the previous and next pointers of the detached node to isolate it from the list.
Node Management Function: prepend
Method:
func (r *LRUCache[K, V]) prepend(node *Node[V]) { // Prepend a node to the front of the linked list if r.head == nil { r.tail = node r.head = node return } node.Next = r.head r.head.Prev = node r.head = node }Explanation:
prependadds a given node to the front of the doubly-linked list. If the list is currently empty (r.head == nil), both head and tail pointers are set to the new node.Otherwise, the new node's
Nextpointer is set to the current head, and the current head'sPrevpointer is set to the new node.Finally, the head pointer is updated to the new node.
These node management functions are how our LRU cache maintains the order of items within the linked list, these functions seamlessly integrate into the broader implementation of our LRU cache.
Putting It All Together
We have defined all the functions and methods we require to make our LRU cache work. After following all the steps above, we should have an LRU cache that can perform the following operations:
Initiate a new cache with a specific capacity
Update the cache; by adding new items to the top of the list
Get stored items from the cache, and prepend them to the top of the list
Upon updating new items, check that we are still within capacity by dropping the least recently used item in the cache per time.
All of that is done but how do we know if it is working for sure?
Here's a sample test file to test all the aspects of our LRU cache:
package main
import (
"testing"
)
func TestLRUCache(t *testing.T) {
// Create a new LRU cache with a capacity of 3
lru := newLRUCache(3)
// Test 1: Adding and getting values
lru.Update("key1", 1)
lru.Update("key2", 2)
lru.Update("key3", 3)
// Check the length after adding 3 entries
if lru.length != 3 {
t.Errorf("Expected length: 3, Got: %d", lru.length)
}
// Check the values retrieved from the cache
checkValue(t, lru.Get("key1"), 1, "key1")
checkValue(t, lru.Get("key2"), 2, "key2")
checkValue(t, lru.Get("key3"), 3, "key3")
// Test 2: Updating an existing value
lru.Update("key2", 22)
// Check the length after updating an entry
if lru.length != 3 {
t.Errorf("Expected length: 3, Got: %d", lru.length)
}
// Check the updated value
checkValue(t, lru.Get("key2"), 22, "key2")
// Test 3: Adding more values to trigger eviction
lru.Update("key4", 4)
lru.Update("key5", 5)
// Check the length after adding 2 more entries
if lru.length != 3 {
t.Errorf("Expected length: 3, Got: %d", lru.length)
}
// Check that the least recently used entry was evicted
checkValue(t, lru.Get("key1"), nil, "key1")
// Check the values of remaining entries
checkValue(t, lru.Get("key2"), 22, "key2")
checkValue(t, lru.Get("key4"), 4, "key4")
checkValue(t, lru.Get("key5"), 5, "key5")
}
func checkValue(t *testing.T, actual interface{}, expected interface{}, key string) {
if actual != expected {
t.Errorf("Expected value for %s: %v, Got: %v", key, expected, actual)
}
}
And there you have it! Save this file as main_test.go run:
go test
All the test cases should pass, you can modify the test file to observe the behaviour of the cache and test more edge cases if you wish!
I hope you enjoyed reading this piece as much as I enjoyed writing it. If you did, kindly drop a like, and follow for more technical articles that will help you learn advanced coding and software engineering concepts.
You can find the full implementation on GitHub here: https://github.com/midedickson/go-lru
Till I write to you again, Bye. 👋
Subscribe to my newsletter
Read articles from Mide Dickson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mide Dickson
Mide Dickson
I am a creative, entrepreneurial engineer. I am a self-taught software engineer with 6 years of experience building software that enhances multiple business operations and changes people's lives. Currently building software to facilitate financial management, sales, and email marketing for businesses that dare to scale far and wide! I have worked with teams building solutions across various industries. I have domain knowledge in building SaaS and Enterprise applications. I am fascinated by the low-level architecture of communication patterns and database internals. My favourite tools are Python, Javascript/Typescript, and GO. (I'm always exploring more) I also have a background in writing. I can distil complex technical concepts into clear and concise documentation that is easy for any audience to understand. I love the challenge of solving hard problems, learning new skills, and applying them to my day-to-day tasks.