A Beginner's Guide to Recurrent Neural Networks (Part 1 of 2)
 Japkeerat Singh
Japkeerat Singh
Imagine you're watching a movie. Each scene in the movie is connected to the previous one, right? You understand the story because you remember what happened before. Recurrent Neural Networks (RNNs) work in a similar way. They are a type of Neural Network that remembers past information and uses it to understand new data. Just like you use your memory of the previous scenes to understand the current scene in a movie, RNNs use information from the past to make sense of new information.
Towards Intuitive Understanding
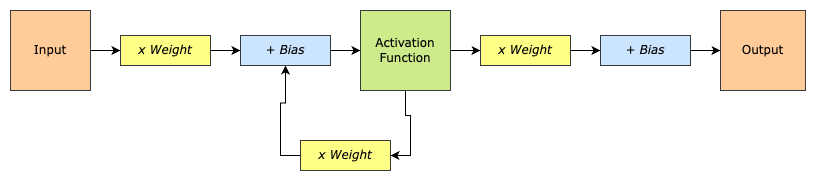
The above diagram is a high-level representation of 1 neuron of an RNN. Unlike a simple neural network, it has a feedback loop. Output from the Activation Function is fed back to the input and then summed together before sending it again to the activation function.
I’ll be honest, this representation always confused me. Coming from a programming point of view, I was confused, wouldn’t this mean we are always stuck in the loop? The following representation actually cleared the confusion.
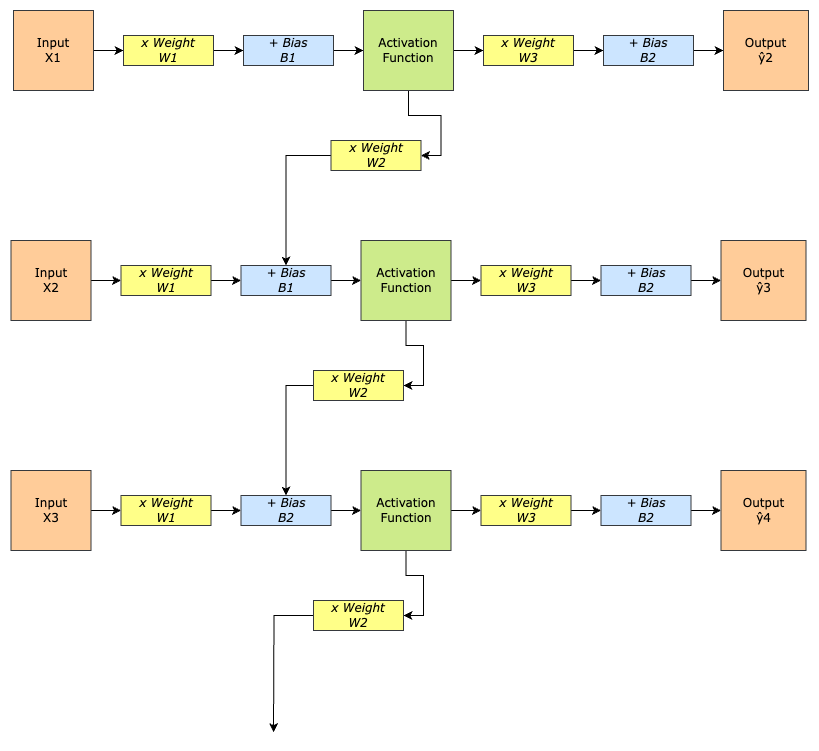
Notice anything different in this representation?
The feedback loop basically affects the next data point in the sequence, not the same one. Input X1 output from the activation function is multiplied with Weight W2 and summed with Input X2 before sending it to the activation function. This process continues till forever.
The Curse in Disguise
Take a good look at the unrolled representation of the RNN once more. Especially the feedback loop. The same thing that makes RNNs remember historical context are also its curse (and the basis of further advancements in NLP and Sequence Data Processing).
Let’s consider 2 examples - one where W2 is too small and another where W2 is too large. I’ll keep it intuitive. Mathematically, we’ll discuss in a separate post.
Too Small W2
If the weight of the feedback loop is too small (for the argument sake, let’s say 0.1) the impact of X1 on the prediction of ŷ5 (for instance) would be negligible. Why? Because X1 got multiplied with a tiny value of 0.1 so many times that it has now almost approached 0 (X1x0.1x0.1x0.1x0.1 = X1x0.0001). So no matter what X1 is, it will be only able to provide 0.01% of it to ŷ5.
This problem means that the historical information is not well preserved when making the predictions for a sequence that occurs after a few data points have been processed.
This problem has a name - Vanishing Gradient.
Too Large W2
If the weight of the feedback loop is too large (anything above 1, so for the sake of argument, let’s say 2) the impact of X1 on the prediction of ŷ5 would overshadow the impact of X2 which in turn would overshadow X3 and so on. Meaning, older the history, more the impact it would have on the predictions. Recent events would have next to no impact on the output.
This problem too has a name - Exploding Gradient.
TLDR;
Recurrent Neural Networks are a type of Neural Networks that uses historical information to predict next data point in the sequence.
RNNs are cursed with the exact thing that makes them unique. If the weight of feedback loop is too small, the gradient vanishes (meaning, RNN would hardly remember the past) and if the weight of feedback loop is too large, the gradient explodes (meaning, RNN would live in the ancient history, present and recent history would have less impact in predictions).
Subscribe to my newsletter
Read articles from Japkeerat Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Japkeerat Singh
Japkeerat Singh
Hi, I am Japkeerat. I am working as a Machine Learning Engineer since January 2020, straight out of college. During this period, I've worked on extremely challenging projects - Security Vulnerability Detection using Graph Neural Networks, User Segmentation for better click through rate of notifications, and MLOps Infrastructure development for startups, to name a few. I keep my articles precise, maximum of 4 minutes of reading time. I'm currently actively writing 2 series - one for beginners in Machine Learning and another related to more advance concepts. The newsletter, if you subscribe to, will send 1 article every Thursday on the advance concepts.