Scrape Cloud for SSL/TLS Certificate
 Rizwan Syed
Rizwan Syed
Crafting a thorough reconnaissance strategy involves harnessing SSL/TLS certificate data from the internet to empower Bug Bounty Hunters, Pentesters, Red Teamers, and Blue Teamers. Through systematic web scraping of SSL/TLS certificates and structuring the data into a JSON file, we can streamline various aspects such as attack surface discovery, domain enumeration, asset inventory management, monitoring, incident response, shadow IT detection, and phishing prevention.
Our methodology entails obtaining lists of IPv4 subnets from major providers such as Amazon, DigitalOcean, Google, Microsoft, and Oracle to pinpoint public IP assets within the specified SNI IP ranges, extracting SSL certificates using TLSx, and subsequently parsing key details from the certificates utilizing the jq command. Our focus lies in gathering and recording vital information like IP addresses, port, common names, organizational details, and Subject Alternative Names (SAN).
The resultant JSON file serves as a robust tool for swift searches, facilitating the mapping and correlation of data throughout the reconnaissance process. This streamlined approach expedites the identification of assets linked to the target domain, organization, or specific IP. By seamlessly integrating this methodology into our reconnaissance toolkit, we bolster our ability to navigate the digital landscape and proactively respond to potential threats.
Creating a dedicated database by systematically scraping SSL/TLS certificates from the internet is a strategic initiative akin to services like crt.sh. This approach offers customization, offline access, improved search capabilities.
Already built database for this ?
https://kaeferjaeger.gay/?dir=sni-ip-ranges
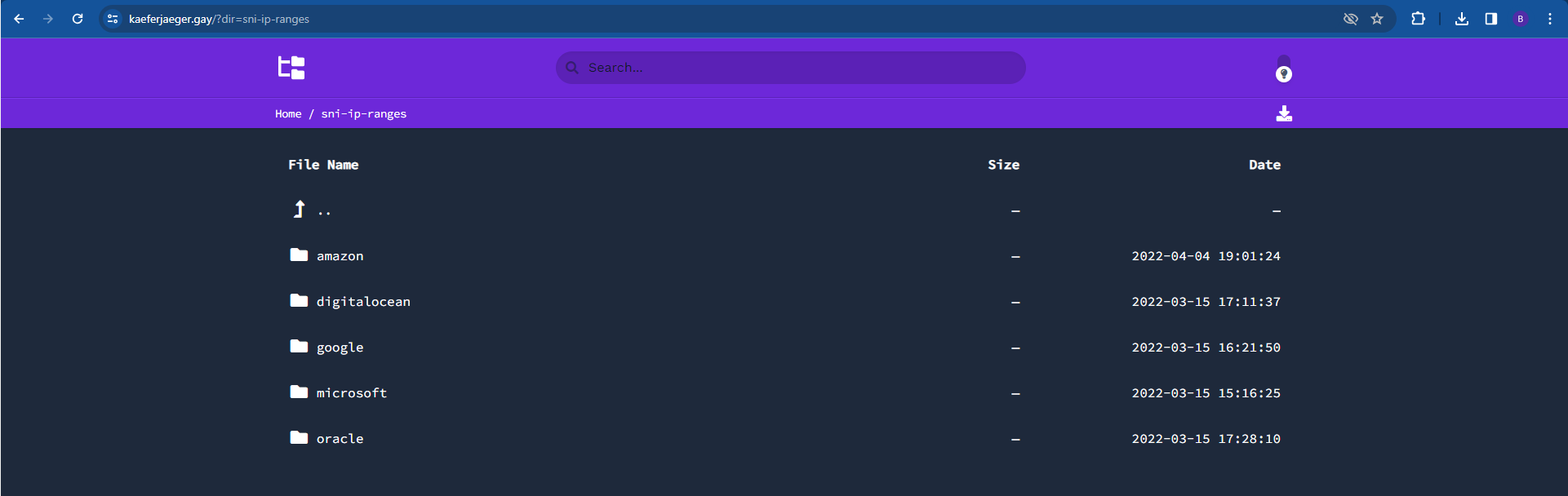
Any Automated Tool around this ?
- CloudRecon: https://github.com/g0ldencybersec/CloudRecon
CloudRecon is a comprehensive suite of GO tools designed for red teamers and bug hunters to uncover hidden, ephemeral assets within target organizations' cloud infrastructures. The suite consists of three key features:
Scrape: Real-time inspection of SSL certificate fields (CN and SN) in specified IP ranges, providing essential information such as IP addresses and common names.
Store: Retrieves and downloads SSL certificates, storing pertinent data like Organizations, CNs, and SANs. This feature aims to establish a personalized crt.sh database for users.
Retr: Parses and searches through locally stored certificates, allowing users to query the database for specific results.
However, it's important to note that the current version has some limitations, including the scrape feature only providing IP addresses and common names in its output. Additionally, the store feature may encounter a panic error due to goroutine issues. Users are advised to be mindful of these limitations while utilizing CloudRecon for their campaigns and hunts.
This script allows you to download and search Server Name Indication (SNI) IP ranges from various providers.
This allows users to update and download the latest SNI IP ranges, creating individual files for each provider. It also enables searching for a specific domain within these ranges. This tool is valuable for Bug Bounty Hunters, Pentesters, Red Teamers, and Blue Teamers, aiding in attack surface discovery, domain enumeration, asset inventory maintenance, monitoring, incident response, shadow IT identification, and phishing detection. Overall, it enhances security professionals' capabilities in identifying and addressing potential security risks.
This script can be used to discover the IPs that belongs to the target organizations.
SNI IP ranges from providers such as Amazon, DigitalOcean, Google, Microsoft, and Oracle.
Keafer-g, much like CloudRecon, serves as another tool for identifying assets within cloud infrastructures. Similarly, it has limitations that align with CloudRecon, providing users with IP addresses and common names. The suggested workflow involves users using tools like 'grep' to filter out their target domains from the obtained information.
git clone https://github.com/mr-rizwan-syed/kaefer-g.git
cd kaefer-g
# To download all sni-ranges from kaeferjaeger site
./sni_lookup.sh -update
# To extract
./sni_lookup.sh <domain>
./sni_lookup.sh <string>
We aim to adopt a manual approach to comprehensively scrape cloud assets across the entire internet. This process involves downloading SSL/TLS certificates from these assets and parsing the data to extract specific information such as IP addresses, ports, common names, organizational details, and Subject Alternative Names (SAN).
Prerequisite:
ProjectDiscovery TLSX: https://github.com/projectdiscovery/tlsx
JQ: For parsing Json files
Tmux: Terminal Multiplexer, detach the session (it keeps running in the background)
# For this go must be installed on your system Or else you can directly download the binary from the release page
go install github.com/projectdiscovery/tlsx/cmd/tlsx@latest
apt install jq tmux -y
Steps:
mkdir certrepo && cd certrepo
# https://github.com/lord-alfred/ipranges
wget https://raw.githubusercontent.com/lord-alfred/ipranges/main/all/ipv4_merged.txt
# Run this in TMUX / Screen session, as scraping would take time
cat ipv4_merged.txt | tlsx -json -silent -c 600 -o certdb_raw.json
# Parsing only the thing we needed
cat certdb_raw.json | jq -c 'select(.probe_status) | { "ip": .ip, "port": .port, "organization_name": .issuer_org[0], "common_name": .subject_cn, "san": .subject_an[] }' 2>/dev/null 1>certdb.json
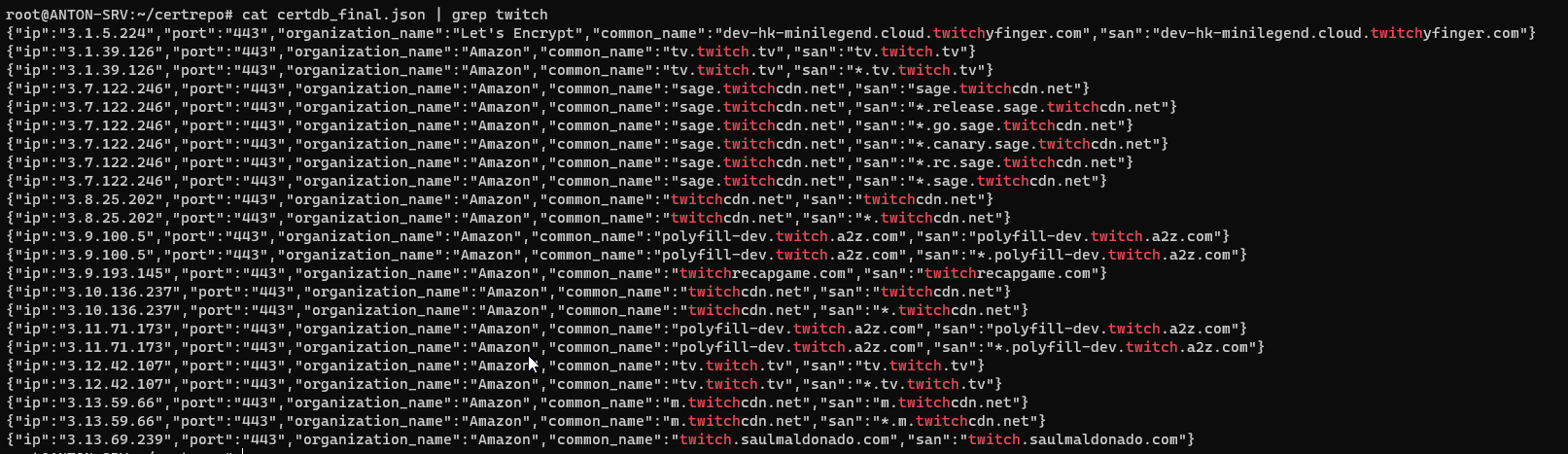
cat certdb.json | grep 'DOMAIN'
cat certdb.json | grep '<ANY-STRING>'
cat certdb.json | grep '<ANY-STRING>' | jq -r .common_name
Subscribe to my newsletter
Read articles from Rizwan Syed directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by