Bias Variance Tradeoff
 Krish Parekh
Krish Parekh
Introduction
Having a proper understanding of Bias and Variance, is the key to achieve accuracy and robustness for your machine learning model. It helps us address the issue of Overfitting and Underfitting
The Basic : Why Worry About Overfitting and Underfitting?
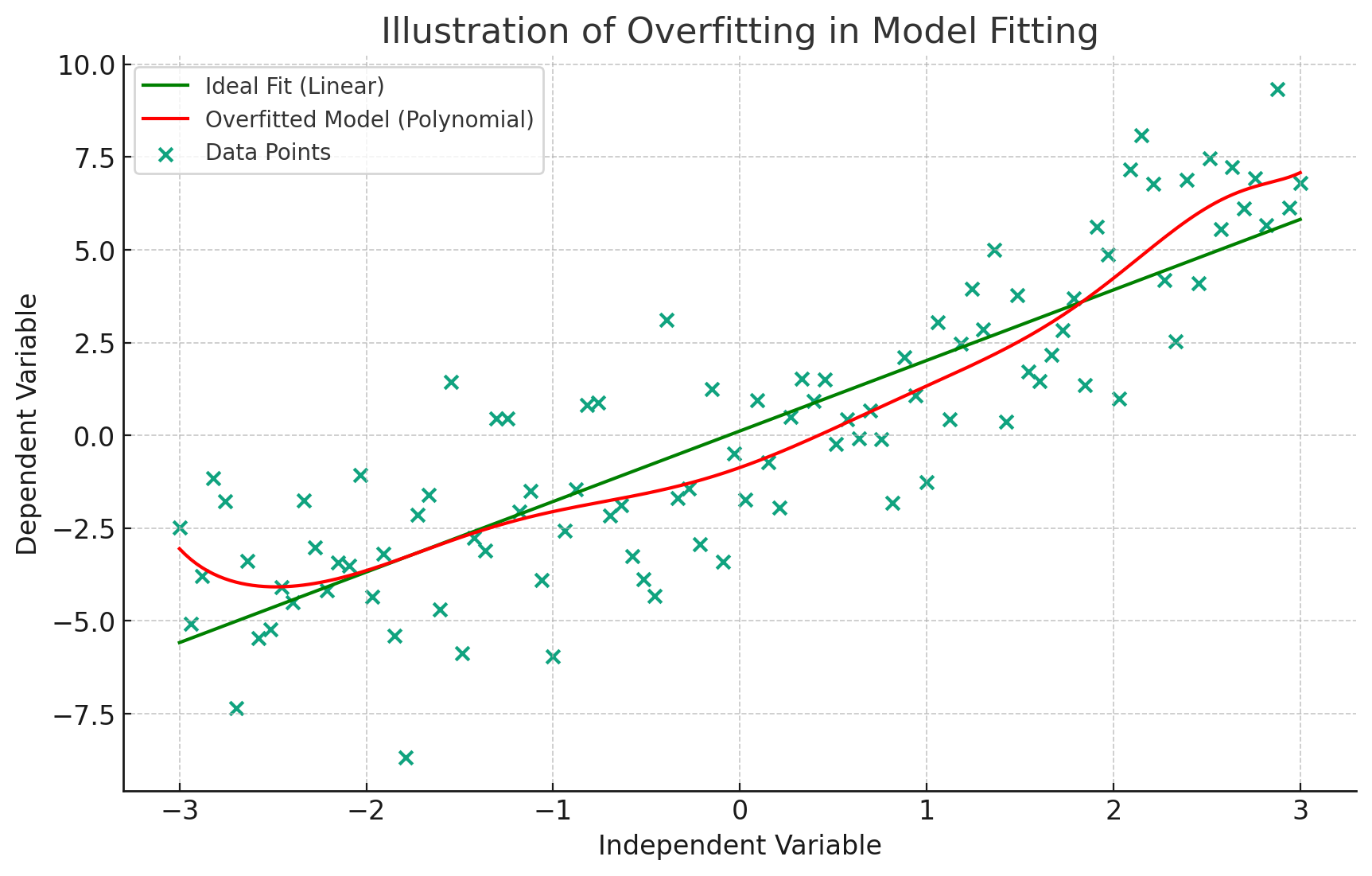
Overfitting
When machine learning models pay a little to much attention on training dataset and forgets to generalize it for unseen or test dataset. Here the model performs well on training data but has poor outcome on testing or unseen data.
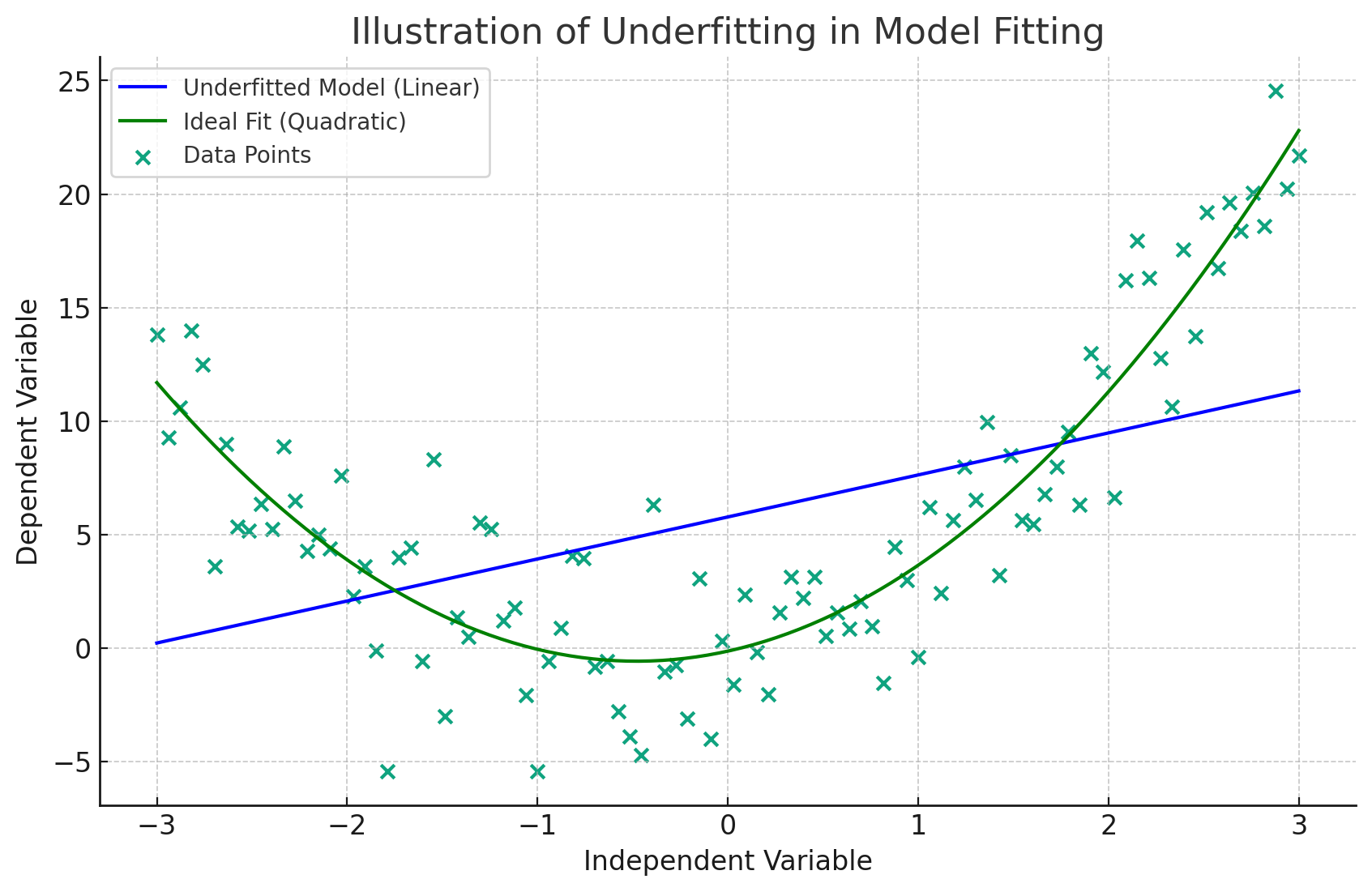
Underfitting
When the machine learning model pays a very little attention to the relationship in the data points leading to poor performance not in the training data, but testing data as well.
TL;DR: Overfitting in machine learning is akin to a student who memorizes facts without grasping the underlying principles. Just as such a student struggles with unexpected questions in an exam, an overfitted model fails to perform well on new, unseen data. On the other hand, underfitting is like a student preparing for the wrong subject, such as studying history for a math exam. This student, much like an underfitted model, is ill-equipped to handle the tasks at hand due to a fundamental lack of relevant knowledge.
The Bias-Variance Tradeoff
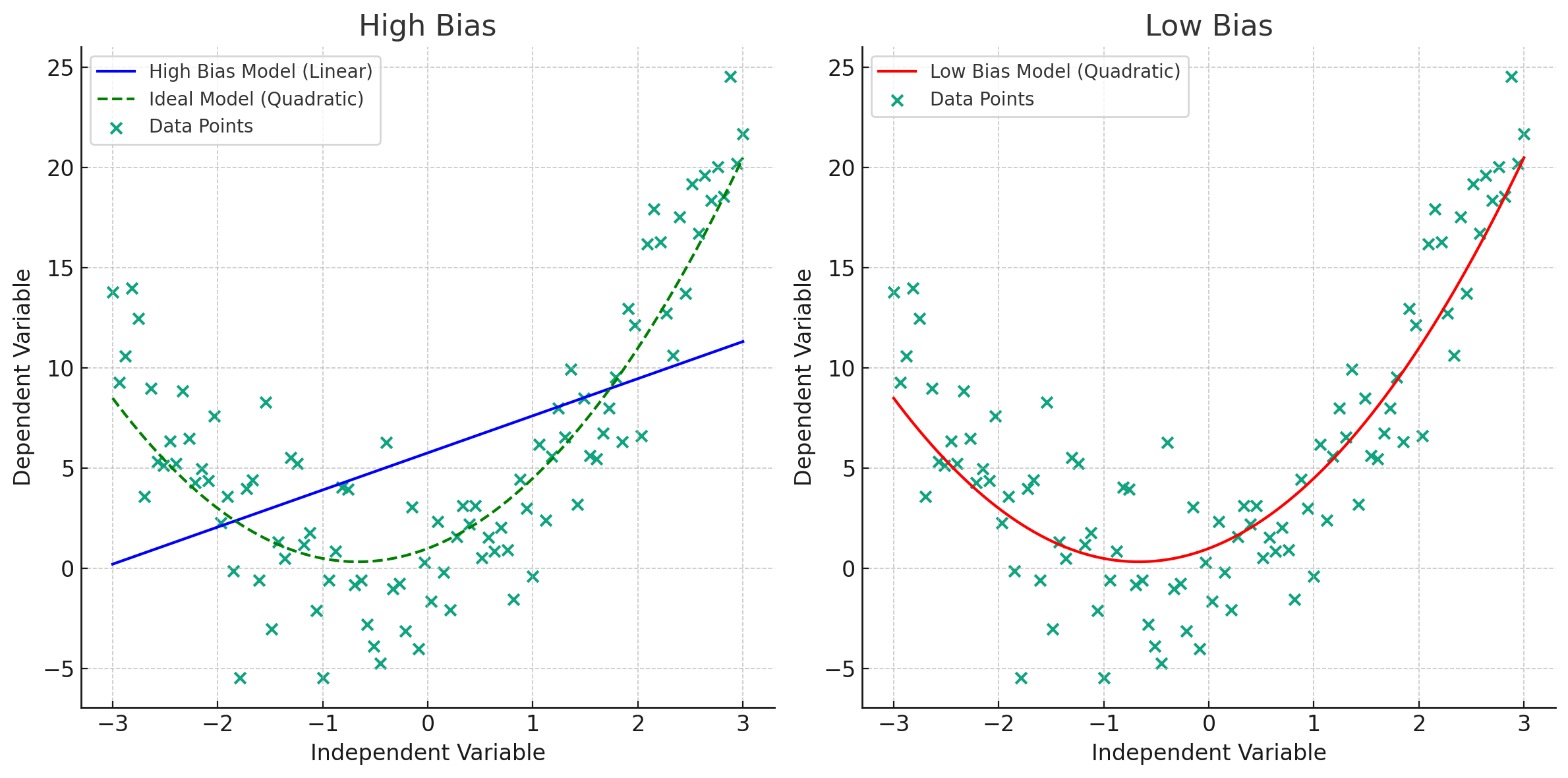
Bias
Think of bias as an error between what your model predicts and the actual value. High bias means model overlooks important trends in the data. Which leads to high error in both training and testing data.
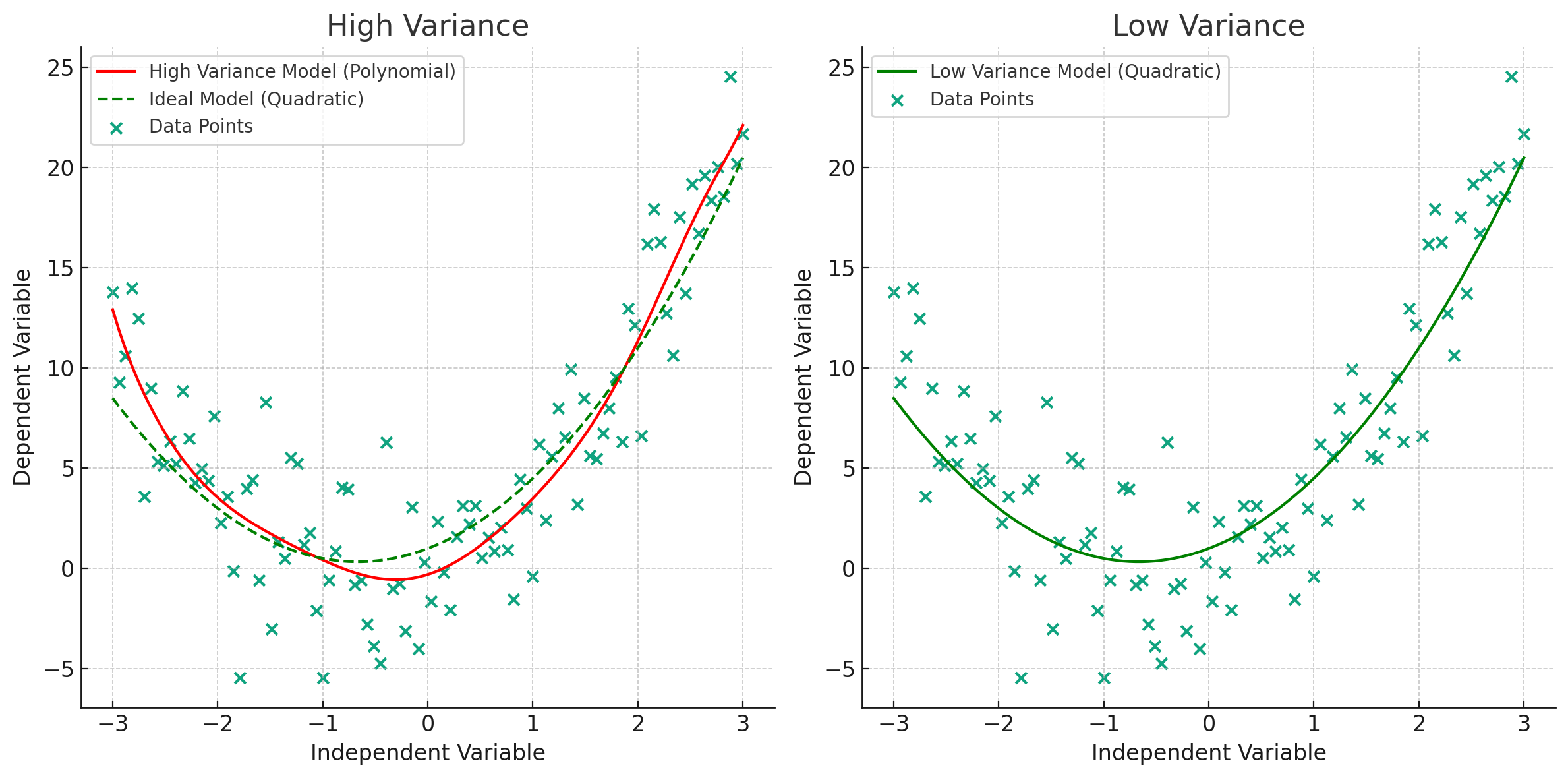
Variance
Variance is about variability. It measures how much your model's predictions would change if trained on different datasets. High variance is a sign that your model is too focused on the training data, failing to generalize to new, unseen data.
The Right Balance
As a programmer, your primary task is to achieve an optimal balance between bias and variance in your models. When a model exhibits high bias and low variance, it typically results in underfitting, meaning it oversimplifies the data. Conversely, a model with low bias and high variance tends to overfit, capturing too much noise from the data. Therefore, the ideal objective is to create a model that maintains both low bias and low variance for Good fit.
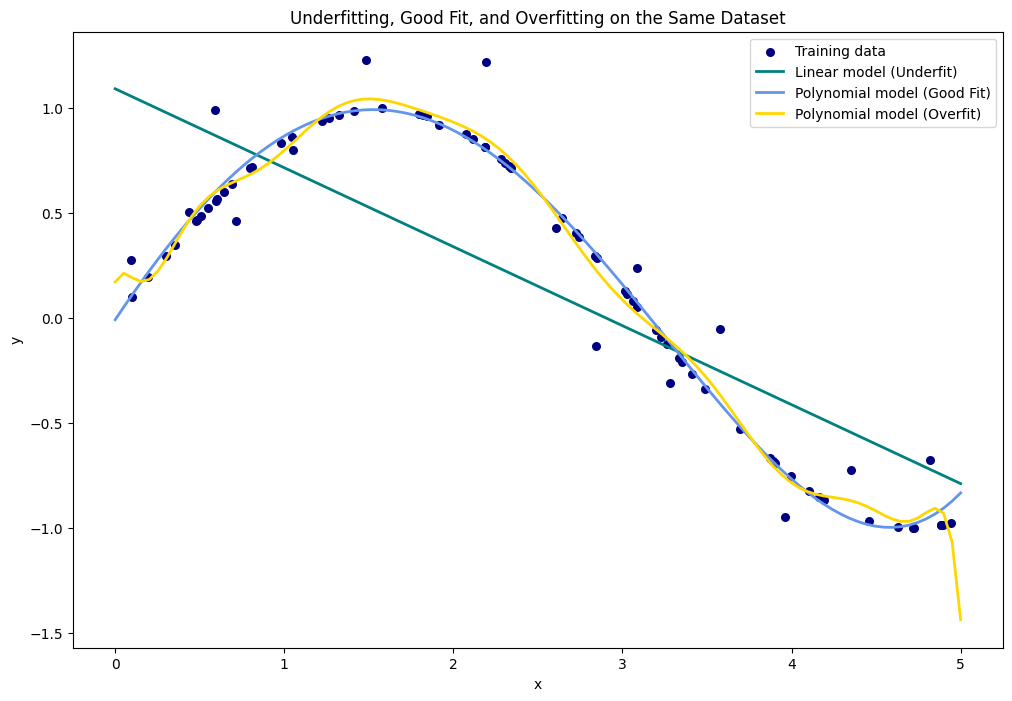
In our upcoming blog, we'll dive into the scenario of tackling Overfitting and Underfitting scenarios. If you've found value in this blog, feel free to spread the word by liking and sharing it with others.
Subscribe to my newsletter
Read articles from Krish Parekh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Krish Parekh
Krish Parekh
I enjoy figuring out problems—looking into what’s going on, finding what works, and sometimes taking a few extra steps to get it right. I started as an Android developer, then moved to web development and backend systems. Now I’m learning DevOps and getting better at it every day. A while back, I worked at a fintech startup and helped build a wealth management dashboard for clients with over $300 million in assets. It was a good experience that taught me a lot. This year, I’m working on improving my DevOps skills and always up for learning more. If you like tech, working together, or solving problems, feel free to reach out!